Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
# Suddivisione dei parlanti (diarizzazione)
Con la diarizzazione degli altoparlanti, è possibile distinguere tra diversi altoparlanti nell'uscita di trascrizione. Amazon Transcribe è in grado di distinguere tra un massimo di 30 oratori diversi ed etichettare il testo di ciascun oratore unico con un valore unico (fino a). `spk_0` `spk_9`
Oltre alle [sezioni di trascrizione standard](how-input.md#how-it-works-output) (`transcripts` e `items`), le richieste con suddivisione dei parlanti abilitata includono una sezione `speaker_labels`. Questa sezione è raggruppata per parlante e contiene informazioni su ogni enunciato, tra cui l'etichetta del parlante e i timestamp.
```
"speaker_labels": {
"channel_label": "ch_0",
"speakers": 2,
"segments": [
{
"start_time": "4.87",
"speaker_label": "spk_0",
"end_time": "6.88",
"items": [
{
"start_time": "4.87",
"speaker_label": "spk_0",
"end_time": "5.02"
},
{{...}}
{
"start_time": "8.49",
"speaker_label": "spk_1",
"end_time": "9.24",
"items": [
{
"start_time": "8.49",
"speaker_label": "spk_1",
"end_time": "8.88"
},
```
Per visualizzare un esempio completo di trascrizione con suddivisione dei parlanti (per due parlanti), consulta [Esempio di output di diarizzazione (batch)](diarization-output-batch.md).
## Suddivisione dei parlanti in una trascrizione in batch
Per suddividere i parlanti in una trascrizione in batch, consulta i seguenti esempi:
### Console di gestione AWS
1. Accedi alla [Console di gestione AWS](https://console.aws.amazon.com/transcribe/).
1. Nel riquadro di navigazione, scegli **Processi di trascrizione**, quindi seleziona **Crea processo** (in alto a destra). Si aprirà la pagina **Specifica i dettagli del processo**.
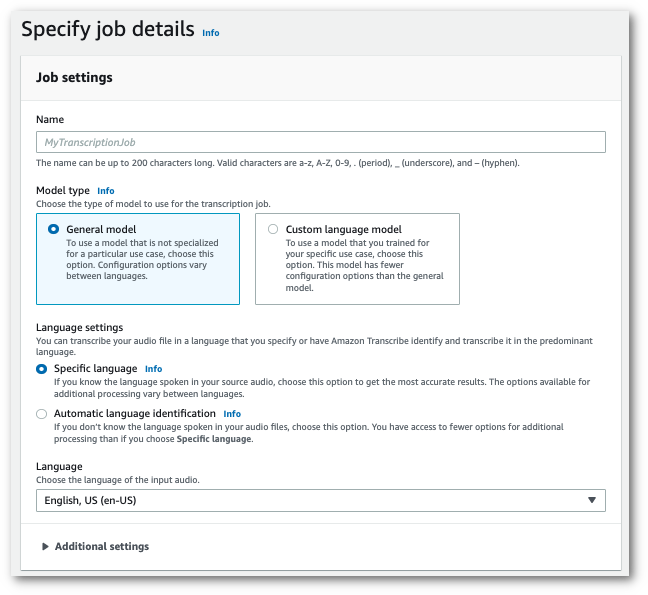
1. Compila tutti i campi che desideri includere nella pagina **Specifica i dettagli del processo**, quindi seleziona **Avanti**. Verrà visualizzata la pagina **Configura processo - *opzionale***.
**Per abilitare il partizionamento degli altoparlanti, in **Impostazioni audio, scegli Identificazione audio**.** Quindi scegli **Partizionamento degli altoparlanti** e specifica il numero di altoparlanti.
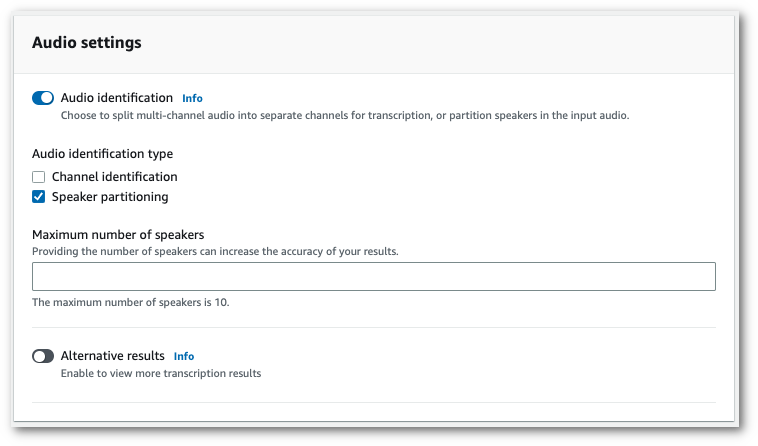
1. Seleziona **Crea processo** per eseguire il processo di trascrizione.
### AWS CLI
Questo esempio utilizza il comando [avvia processo trascrizione](https://awscli.amazonaws.com/v2/documentation/api/latest/reference/transcribe/start-transcription-job.html). Per ulteriori informazioni, consulta [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html).
```
aws transcribe start-transcription-job \
--region {{us-west-2}} \
--transcription-job-name {{my-first-transcription-job}} \
--media MediaFileUri=s3://{{amzn-s3-demo-bucket}}/{{my-input-files}}/{{my-media-file}}.{{flac}} \
--output-bucket-name {{amzn-s3-demo-bucket}} \
--output-key {{my-output-files}}/ \
--language-code {{en-US}} \
--settings ShowSpeakerLabels={{true}},MaxSpeakerLabels={{3}}
```
Ecco un altro esempio che utilizza il comando [avvia processo trascrizione](https://awscli.amazonaws.com/v2/documentation/api/latest/reference/transcribe/start-transcription-job.html) e un corpo della richiesta che consente la suddivisione dei parlanti con quel processo.
```
aws transcribe start-transcription-job \
--region {{us-west-2}} \
--cli-input-json file://{{my-first-transcription-job}}.json
```
Il file *my-first-transcription-job.json* contiene il seguente corpo della richiesta.
```
{
"TranscriptionJobName": "{{my-first-transcription-job}}",
"Media": {
"MediaFileUri": "s3://{{amzn-s3-demo-bucket}}/{{my-input-files}}/{{my-media-file}}.{{flac}}"
},
"OutputBucketName": "{{amzn-s3-demo-bucket}}",
"OutputKey": "{{my-output-files}}/",
"LanguageCode": "{{en-US}}",
"ShowSpeakerLabels": 'TRUE',
"MaxSpeakerLabels": {{3}}
}
```
### AWS SDK per Python (Boto3)
Questo esempio utilizza AWS SDK per Python (Boto3) per identificare i canali utilizzando il metodo [start\_transcription\_job](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/transcribe.html#TranscribeService.Client.start_transcription_job). Per ulteriori informazioni, consulta [StartTranscriptionJob](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_StartTranscriptionJob.html).
```
from __future__ import print_function
import time
import boto3
transcribe = boto3.client('transcribe', '{{us-west-2}}')
job_name = "{{my-first-transcription-job}}"
job_uri = "s3://{{amzn-s3-demo-bucket}}/{{my-input-files}}/{{my-media-file}}.{{flac}}"
transcribe.start_transcription_job(
TranscriptionJobName = job_name,
Media = {
'MediaFileUri': job_uri
},
OutputBucketName = '{{amzn-s3-demo-bucket}}',
OutputKey = '{{my-output-files}}/',
LanguageCode = '{{en-US}}',
Settings = {
'ShowSpeakerLabels': True,
'MaxSpeakerLabels': {{3}}
}
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName = job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
print(status)
```
## Suddivisione dei parlanti in una trascrizione in streaming
Per suddividere i parlanti in una trascrizione in streaming, consulta i seguenti esempi:
### Trascrizioni in streaming
1. Accedi alla [Console di gestione AWS](https://console.aws.amazon.com/transcribe/).
1. **Nel riquadro di navigazione, scegli Real-time trascrizione.** Scorri verso il basso fino a **Impostazioni audio** ed espandi questo campo se è ridotto al minimo.
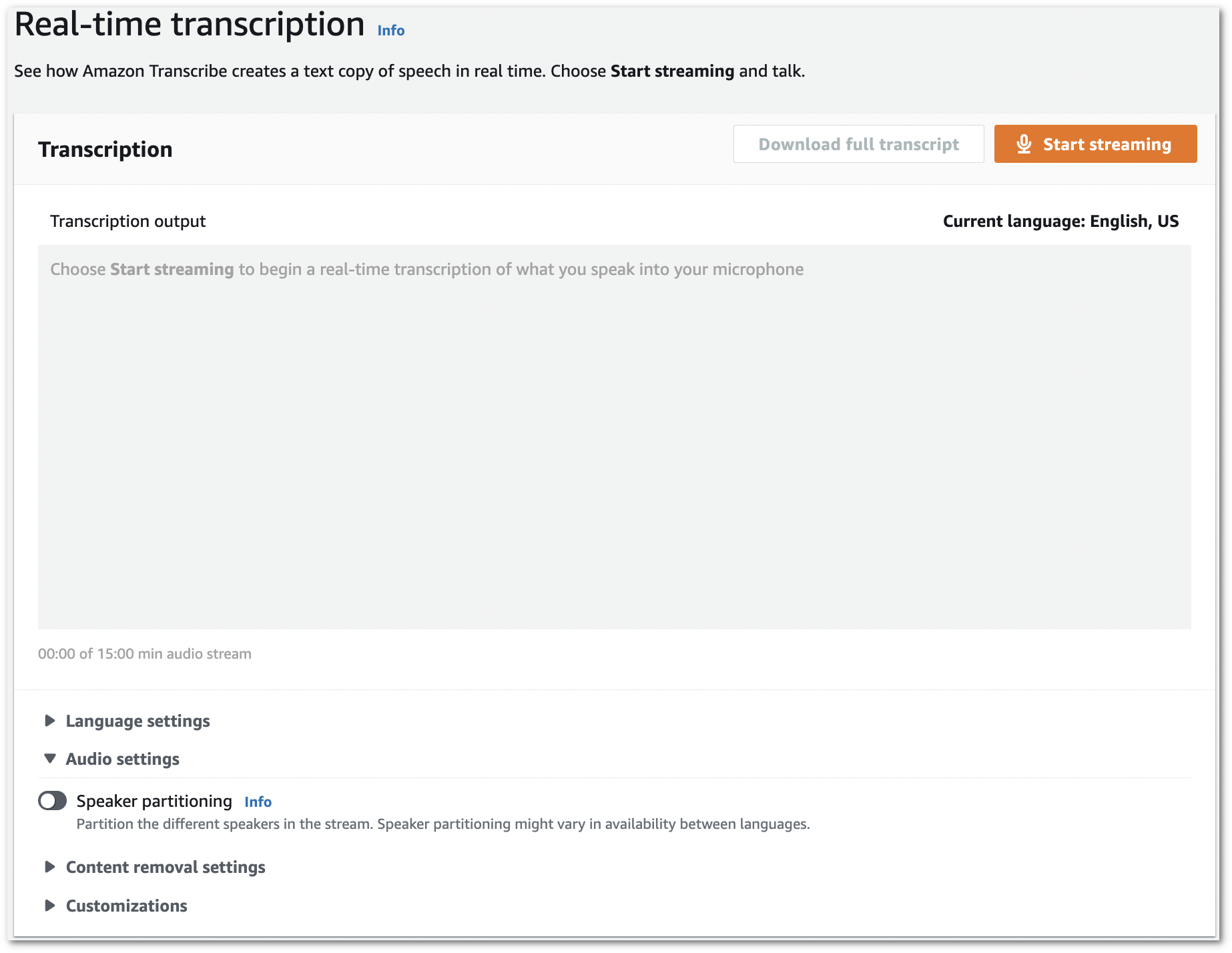
1. Attiva la **suddivisione dei parlanti**.
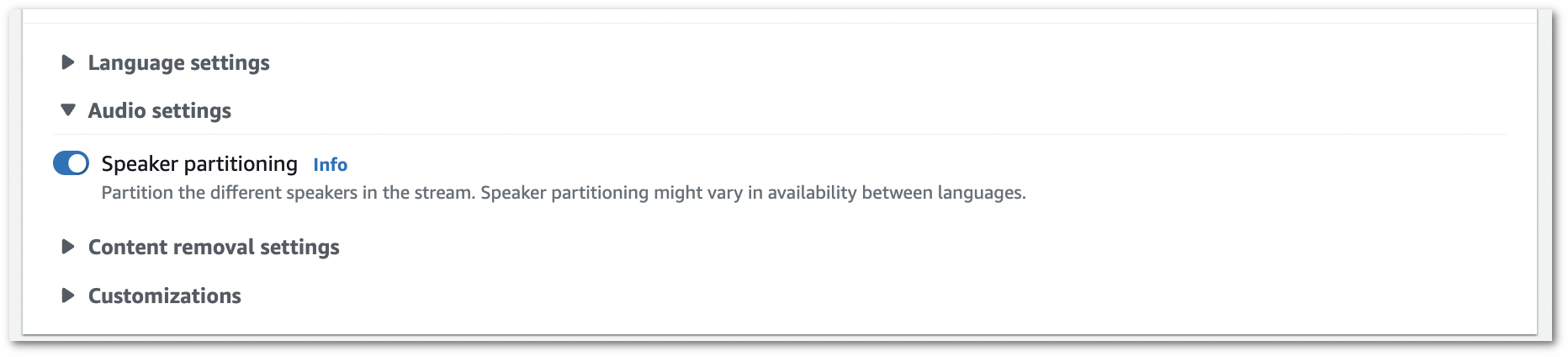
1. A questo punto puoi eseguire la trascrizione del flusso. Seleziona **Avvia streaming** e inizia a parlare. Per terminare la dettatura, seleziona **Interrompi streaming**.
### HTTP/2 streaming
Questo esempio crea una HTTP/2 richiesta per partizionare gli altoparlanti nell'output di trascrizione. Per ulteriori informazioni sull'utilizzo HTTP/2 dello streaming con Amazon Transcribe, consulta. [Configurare uno stream HTTP/2](streaming-setting-up.md#streaming-http2) Per ulteriori dettagli sui parametri e le intestazioni specifici di Amazon Transcribe, consulta [StartStreamTranscription](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_streaming_StartStreamTranscription.html).
```
POST /stream-transcription HTTP/2
host: transcribestreaming.{{us-west-2}}.amazonaws.com
X-Amz-Target: com.amazonaws.transcribe.Transcribe.{{StartStreamTranscription}}
Content-Type: application/vnd.amazon.eventstream
X-Amz-Content-Sha256: {{string}}
X-Amz-Date: {{20220208}}T{{235959}}Z
Authorization: AWS4-HMAC-SHA256 Credential={{access-key}}/{{20220208}}/{{us-west-2}}/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature={{string}}
x-amzn-transcribe-language-code: {{en-US}}
x-amzn-transcribe-media-encoding: {{flac}}
x-amzn-transcribe-sample-rate: {{16000}}
x-amzn-transcribe-show-speaker-label: true
transfer-encoding: chunked
```
Le definizioni dei parametri sono disponibili nell'[API Reference](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_Reference.html); i parametri comuni a tutte le operazioni AWS API sono elencati nella sezione [Parametri comuni](https://docs.aws.amazon.com/transcribe/latest/APIReference/CommonParameters.html).
### WebSocket flusso
Questo esempio crea un URL prefirmato che separa i parlanti nell'output della trascrizione. Le interruzioni di riga sono state aggiunte per la leggibilità. Per ulteriori informazioni sull'utilizzo degli WebSocket stream con Amazon Transcribe, consulta[Configurare uno WebSocket stream](streaming-setting-up.md#streaming-websocket). Per ulteriori dettagli sui parametri, consulta [https://docs.aws.amazon.com/transcribe/latest/APIReference/API_streaming_StartStreamTranscription.html](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_streaming_StartStreamTranscription.html).
```
GET wss://transcribestreaming.{{us-west-2}}.amazonaws.com:8443/stream-transcription-websocket?
&X-Amz-Algorithm=AWS4-HMAC-SHA256
&X-Amz-Credential={{AKIAIOSFODNN7EXAMPLE}}%2F{{20220208}}%2F{{us-west-2}}%2F{{transcribe}}%2Faws4_request
&X-Amz-Date={{20220208}}T{{235959}}Z
&X-Amz-Expires={{300}}
&X-Amz-Security-Token={{security-token}}
&X-Amz-Signature={{string}}
&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date
&language-code=en-US
&specialty={{PRIMARYCARE}}
&type={{DICTATION}}
&media-encoding={{flac}}
&sample-rate={{16000}}
&show-speaker-label=true
```
Le definizioni dei parametri sono disponibili nell'[API Reference](https://docs.aws.amazon.com/transcribe/latest/APIReference/API_Reference.html); i parametri comuni a tutte le operazioni AWS API sono elencati nella sezione [Parametri comuni](https://docs.aws.amazon.com/transcribe/latest/APIReference/CommonParameters.html).