Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Automatizza l'implementazione Catena di approvvigionamento dei data lake in una configurazione multi-repository
Keshav Ganesh, Amazon Web Services
Riepilogo
Questo modello fornisce un approccio automatizzato per l'implementazione e la gestione Catena di approvvigionamento di AWS dei data lake utilizzando funzionalità di integrazione continua multirepository e distribuzione continua (). CI/CD) pipeline. It demonstrates two deployment methods: automated deployment using GitHub Actions workflows, or manual deployment using Terraform directly. Both approaches use Terraform for infrastructure as code (IaC), with the automated method adding GitHub Actions and JFrog Artifactory for enhanced CI/CD
La soluzione sfrutta Catena di approvvigionamento Amazon Simple Storage Service (Amazon S3) per stabilire l'infrastruttura del data lake, utilizzando entrambi i metodi di distribuzione per automatizzare la configurazione e la creazione di risorse. AWS Lambda Questa automazione elimina le fasi di configurazione manuali e garantisce implementazioni coerenti in tutti gli ambienti. Inoltre, Catena di approvvigionamento elimina la necessità di competenze approfondite in materia di estrazione, trasformazione e caricamento (ETL) e può fornire approfondimenti e analisi basati su Amazon Quick Sight.
Implementando questo modello, le organizzazioni possono ridurre i tempi di implementazione, mantenere l'infrastruttura come codice e gestire i data lake della catena di fornitura attraverso un processo automatizzato e controllato dalla versione. L'approccio multirepository fornisce un controllo granulare degli accessi e supporta l'implementazione indipendente di diversi componenti. I team possono scegliere il metodo di implementazione più adatto agli strumenti e ai processi esistenti.
Prerequisiti e limitazioni
Prerequisiti
Assicurati che sul tuo computer locale sia installato quanto segue:
AWS Command Line Interface (AWS CLI) versione 2
Terraform v1.12
o versione successiva
Assicurati che siano presenti le seguenti condizioni prima della distribuzione:
Un attivo Account AWS.
Un cloud privato virtuale (VPC) con due sottoreti private Account AWS a tua scelta. Regione AWS
Autorizzazioni sufficienti per il ruolo AWS Identity and Access Management (IAM) utilizzato per l'implementazione nei seguenti servizi:
Catena di approvvigionamento — Accesso completo preferito per l'implementazione dei relativi componenti, come set di dati e flussi di integrazione, oltre ad accedervi da. Console di gestione AWS
Amazon CloudWatch Logs: per creare e gestire gruppi di CloudWatch log.
Amazon Elastic Compute Cloud (Amazon EC2) — Per i gruppi di sicurezza Amazon EC2 e gli endpoint Amazon Virtual Private Cloud (Amazon VPC).
Amazon EventBridge : destinato all'uso da Catena di approvvigionamento.
IAM: per creare ruoli AWS Lambda di servizio.
AWS Key Management Service (AWS KMS) — Per accedere al bucket di artefatti Amazon S3 AWS KMS keys utilizzato e al bucket di staging Amazon S3. Catena di approvvigionamento
AWS Lambda — Per creare le funzioni Lambda che distribuiscono i componenti. Catena di approvvigionamento
Amazon S3: per accedere al bucket di artefatti Amazon S3, al bucket di registrazione degli accessi al server e al bucket di staging. Catena di approvvigionamento Se utilizzi la distribuzione manuale, sono necessarie anche le autorizzazioni per il bucket di artefatti Amazon S3 Terraform.
Amazon VPC: per creare e gestire un VPC.
Se preferisci utilizzare i flussi di lavoro GitHub Actions per la distribuzione, procedi come segue:
Configura OpenID Connect (OIDC)
per il ruolo IAM con le autorizzazioni menzionate in precedenza. Crea un ruolo IAM con autorizzazioni simili per accedere a. Console di gestione AWS Per ulteriori informazioni, consulta Creare un ruolo per concedere le autorizzazioni a un utente IAM nella documentazione IAM.
Se preferisci eseguire una distribuzione manuale, procedi come segue:
Crea un utente IAM che assuma il ruolo IAM con le autorizzazioni menzionate in precedenza. Per ulteriori informazioni, consulta Creare un ruolo per concedere le autorizzazioni a un utente IAM nella documentazione IAM.
Assumi il ruolo nel tuo terminale locale.
Se preferisci utilizzare i flussi di lavoro di GitHub Actions per la distribuzione, configura quanto segue:
Un account JFrog Artifactory
per ottenere il nome host, il nome utente di accesso e il token di accesso di accesso. Una chiave di JFrog progetto e un archivio
per archiviare gli artefatti.
Limitazioni
L' Catena di approvvigionamento istanza non supporta tecniche complesse di trasformazione dei dati.
Catena di approvvigionamento è più adatto per i domini della catena di fornitura perché fornisce analisi e approfondimenti integrati. Per qualsiasi altro dominio, Catena di approvvigionamento può essere utilizzato come archivio dati come parte dell'architettura del data lake.
Potrebbe essere necessario migliorare le funzioni Lambda utilizzate in questa soluzione per gestire i tentativi di API e la gestione della memoria in un'implementazione su scala di produzione.
Alcune Servizi AWS non sono disponibili in tutte. Regioni AWS Per la disponibilità regionale, vedi AWS Servizi per regione
. Per endpoint specifici, consulta Endpoints and quotas del servizio e scegli il link relativo al servizio.
Architecture
Puoi implementare questa soluzione utilizzando i flussi di lavoro GitHub Actions automatizzati o manualmente utilizzando Terraform.
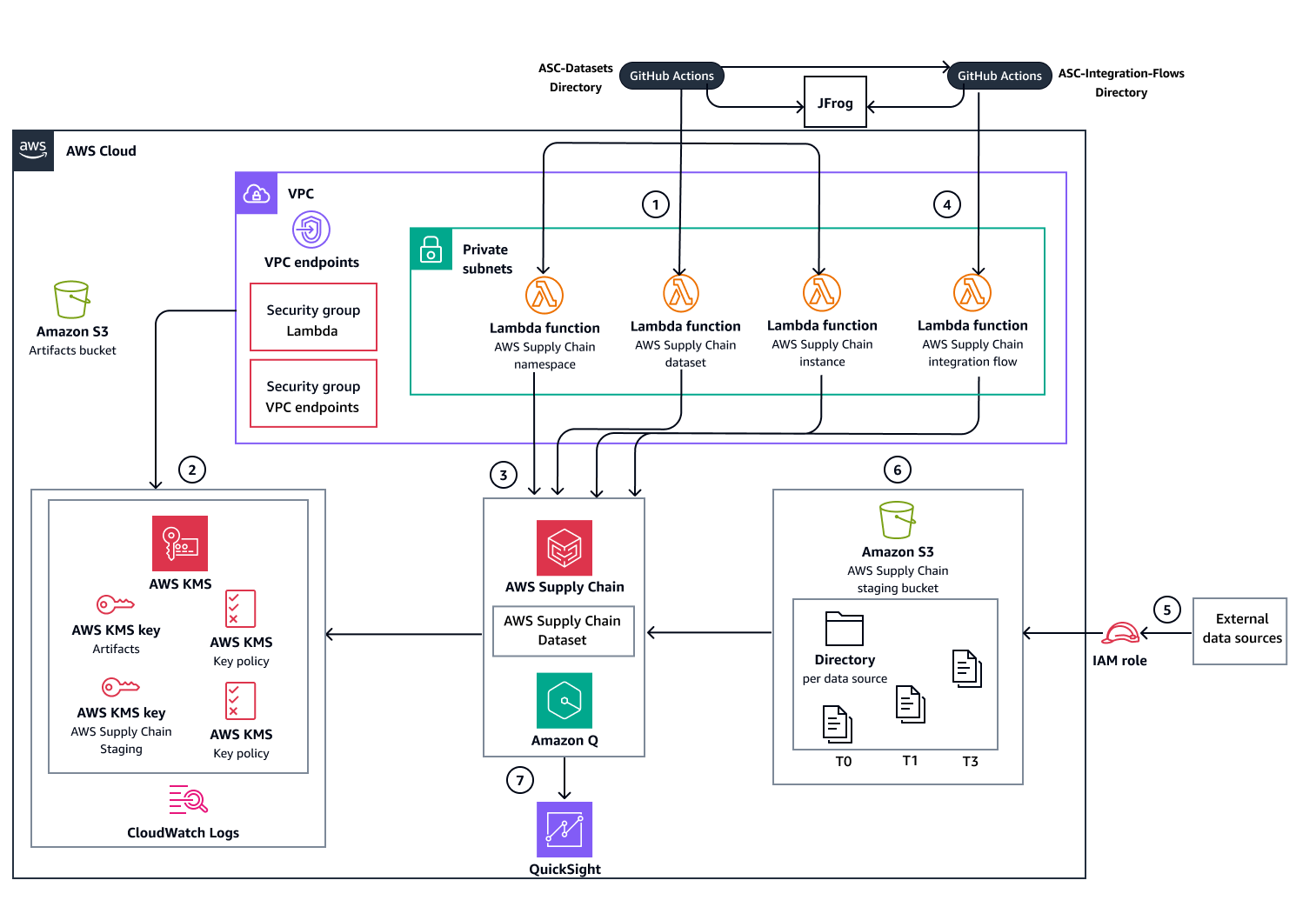
Distribuzione automatizzata con Actions GitHub
Il diagramma seguente mostra l'opzione di distribuzione automatizzata che utilizza i flussi di lavoro GitHub Actions. JFrog Artifactory viene utilizzato per la gestione degli artefatti. Memorizza le informazioni sulle risorse e gli output per l'uso in una distribuzione multirepository.
Distribuzione manuale con Terraform
Il diagramma seguente mostra l'opzione di distribuzione manuale tramite Terraform. Invece di JFrog Artifactory, Amazon S3 viene utilizzato per la gestione degli artefatti.

Workflow di implementazione
I diagrammi mostrano il seguente flusso di lavoro:
Distribuisci l'infrastruttura e i database dei set di dati dei Catena di approvvigionamento servizi utilizzando uno dei seguenti metodi di distribuzione:
Distribuzione automatizzata: utilizza i flussi di lavoro di GitHub Actions per orchestrare tutte le fasi di distribuzione e utilizza JFrog Artifactory per la gestione degli artefatti.
Distribuzione manuale: esegue i comandi Terraform direttamente per ogni fase di distribuzione e utilizza Amazon S3 per la gestione degli artefatti.
Crea le AWS risorse di supporto necessarie per il funzionamento del servizio: Catena di approvvigionamento
Endpoint e gruppi di sicurezza Amazon VPC
AWS KMS keys
CloudWatch Registra i gruppi di log
Crea e distribuisci le seguenti risorse di infrastruttura:
Funzioni Lambda che gestiscono (creano, aggiornano ed eliminano) l'istanza del Catena di approvvigionamento servizio, i namespace e i set di dati.
Catena di approvvigionamento gestione temporanea del bucket Amazon S3 per l'inserimento di dati
Implementa la funzione Lambda che gestisce i flussi di integrazione tra lo staging bucket e i set di dati. Catena di approvvigionamento Una volta completata l'implementazione, le fasi rimanenti del flusso di lavoro gestiscono l'inserimento e l'analisi dei dati.
Configura l'inserimento dei dati di origine nel bucket di Catena di approvvigionamento staging Amazon S3.
Dopo aver aggiunto i dati al bucket Catena di approvvigionamento di staging Amazon S3, il servizio attiva automaticamente il flusso di integrazione nei set di dati. Catena di approvvigionamento
Catena di approvvigionamento si integra con Quick Sight Analytics per produrre dashboard basate sui dati acquisiti.
Tools (Strumenti)
Servizi AWS
Amazon CloudWatch Logs ti aiuta a centralizzare i log di tutti i tuoi sistemi e applicazioni, Servizi AWS così puoi monitorarli e archiviarli in modo sicuro.
AWS Command Line Interface (AWS CLI) è uno strumento open source che ti aiuta a interagire Servizi AWS tramite comandi nella shell della riga di comando.
Amazon Elastic Compute Cloud (Amazon EC2) fornisce capacità di calcolo scalabile nel Cloud AWS. Puoi avviare tutti i server virtuali di cui hai bisogno e dimensionarli rapidamente.
Amazon EventBridge è un servizio di bus eventi senza server che ti aiuta a connettere le tue applicazioni con dati in tempo reale provenienti da una varietà di fonti. Ad esempio, AWS Lambda funzioni, endpoint di invocazione HTTP che utilizzano destinazioni API o bus di eventi in altro modo. Account AWS
AWS Identity and Access Management (IAM) ti aiuta a gestire in modo sicuro l'accesso alle tue AWS risorse controllando chi è autenticato e autorizzato a utilizzarle.
AWS IAM Identity Centerti aiuta a gestire centralmente l'accesso Single Sign-On (SSO) a tutte le tue applicazioni e a quelle sul cloud. Account AWS
AWS Key Management Service (AWS KMS) ti aiuta a creare e controllare chiavi crittografiche per proteggere i tuoi dati.
AWS Lambda è un servizio di calcolo che consente di eseguire il codice senza gestire i server o effettuarne il provisioning. Esegue il codice solo quando necessario e si ridimensiona automaticamente, quindi paghi solo per il tempo di elaborazione che utilizzi.
Amazon Q in Catena di approvvigionamento è un assistente AI generativo interattivo che ti aiuta a gestire la catena di approvvigionamento in modo più efficiente analizzando i dati nel tuo Catena di approvvigionamento data lake.
Amazon Quick Sight è un servizio di business intelligence (BI) su scala cloud che ti aiuta a visualizzare, analizzare e generare report sui dati in un'unica dashboard.
Amazon Simple Storage Service (Amazon S3) è un servizio di archiviazione degli oggetti basato sul cloud che consente di archiviare, proteggere e recuperare qualsiasi quantità di dati.
Catena di approvvigionamentoè un'applicazione gestita basata sul cloud che può essere utilizzata come archivio dati nelle organizzazioni per i domini della catena di fornitura, che può essere utilizzata per generare approfondimenti ed eseguire analisi sui dati acquisiti.
Amazon Virtual Private Cloud (Amazon VPC) ti aiuta a lanciare AWS risorse in una rete virtuale che hai definito. Questa rete virtuale è simile a una comune rete da gestire all'interno del proprio data center, ma con i vantaggi dell'infrastruttura scalabile di AWS. Un endpoint Amazon VPC è un dispositivo virtuale che ti aiuta a connettere privatamente il tuo VPC a Supported Servizi AWS senza richiedere un gateway Internet, un dispositivo NAT, una connessione VPN o una connessione. AWS Direct Connect
Altri strumenti
GitHub Actions
è una piattaforma di integrazione e distribuzione continua (CI/CD) strettamente integrata con i repository. GitHub Puoi utilizzare GitHub Actions per automatizzare la pipeline di compilazione, test e distribuzione. HashiCorp Terraform
è uno strumento di infrastruttura come codice (IaC) che ti aiuta a creare e gestire risorse cloud e locali. JFrog Artifactory
fornisce l' end-to-endautomazione e la gestione di file binari e artefatti attraverso il processo di distribuzione delle applicazioni. Python
è un linguaggio di programmazione per computer generico. Questo modello utilizza Python con cui il codice della AWS funzione può interagire Catena di approvvigionamento .
Best practice
Mantieni la massima sicurezza possibile durante l'implementazione di questo modello. Come indicato in Prerequisiti, assicurati che un cloud privato virtuale (VPC) con due sottoreti private sia presente nel Account AWS Regione AWS tuo computer di tua scelta.
Utilizza le chiavi gestite AWS KMS dal cliente laddove possibile e concedi loro autorizzazioni di accesso limitate.
Per configurare i ruoli IAM con il minimo accesso richiesto per l'acquisizione dei dati per questo pattern, consulta Secure Data Ingestion from Source Systems to Amazon S3
nel repository di questo pattern.
Epiche
| Operazione | Description | Competenze richieste |
|---|---|---|
Clonare il repository. | Per clonare l'archivio di questo pattern, esegui il seguente comando nella tua workstation locale:
| AWS DevOps |
(Opzione automatizzata) Verifica i prerequisiti per la distribuzione. | Assicurati che i prerequisiti per la distribuzione automatizzata siano completi. | Proprietario dell'app |
(Opzione manuale) Preparati per la distribuzione dei Catena di approvvigionamento set di dati. | Per accedere alla
Per assumere il ruolo ARN creato nei Prerequisiti, esegui il comando seguente:
Per configurare ed esportare le variabili di ambiente, esegui i seguenti comandi:
| AWS DevOps |
(Opzione manuale) Preparati a gestire i flussi di Catena di approvvigionamento integrazione durante la distribuzione. | Per accedere alla
Per assumere il ruolo ARN creato in precedenza, esegui il seguente comando:
Per configurare ed esportare le variabili di ambiente, esegui i seguenti comandi:
| Proprietario dell'app |
| Operazione | Description | Competenze richieste |
|---|---|---|
Copia la | Per copiare la
| AWS DevOps |
Configura la | Per configurarlo
| AWS DevOps |
Configura il nome del ramo nel file di workflow .github. | Imposta il nome del ramo nel file del flusso di lavoro di distribuzione
| Proprietario dell'app |
Configura GitHub gli ambienti e configura i valori dell'ambiente. | Per configurare GitHub gli ambienti nella propria GitHub organizzazione, utilizzare le istruzioni in Configurazione GitHub degli ambienti Per configurare i valori di ambiente | Proprietario dell'app |
Attiva il flusso di lavoro. | Per inviare le modifiche all' GitHub organizzazione e attivare il flusso di lavoro di distribuzione, esegui il comando seguente:
| AWS DevOps |
| Operazione | Description | Competenze richieste |
|---|---|---|
Copia la | Per copiare la
| AWS DevOps |
Configura la | Per configurare la
| AWS DevOps |
Configura il nome del ramo nel file di workflow .github. | Imposta il nome del ramo nel file del flusso di lavoro di distribuzione
| Proprietario dell'app |
Configura GitHub gli ambienti e configura i valori dell'ambiente. | Per configurare GitHub gli ambienti nella propria GitHub organizzazione, utilizzare le istruzioni in Configurazione GitHub degli ambienti Per configurare i valori di ambiente | Proprietario dell'app |
Attiva il flusso di lavoro. | Per inviare le modifiche all' GitHub organizzazione e attivare il flusso di lavoro di distribuzione, esegui il comando seguente:
| AWS DevOps |
| Operazione | Description | Competenze richieste |
|---|---|---|
Passa alla directory | Per accedere alla
| AWS DevOps |
Configura il bucket Amazon S3 dello stato Terraform. | Per configurare il bucket Amazon S3 dello stato Terraform, usa lo script seguente:
| AWS DevOps |
Configura il bucket Terraform Artifacts Amazon S3. | Per configurare il bucket Terraform Artifacts Amazon S3, usa lo script seguente:
| AWS DevOps |
Configura il backend Terraform e la configurazione dei provider. | Per configurare il backend Terraform e la configurazione dei provider, utilizza il seguente script:
| AWS DevOps |
Genera un piano di distribuzione. | Per generare un piano di distribuzione, esegui i seguenti comandi:
| AWS DevOps |
Implementa le configurazioni. | Per distribuire le configurazioni, esegui il comando seguente:
| AWS DevOps |
Aggiorna altre configurazioni e archivia gli output. | Per aggiornare le politiche AWS KMS chiave e archiviare gli output delle configurazioni applicate nel bucket Terraform Artifacts Amazon S3, esegui i seguenti comandi:
| AWS DevOps |
| Operazione | Description | Competenze richieste |
|---|---|---|
Passa alla directory | Per accedere alla
| AWS DevOps |
Configura il backend Terraform e la configurazione dei provider. | Per configurare il backend Terraform e le configurazioni del provider, utilizza il seguente script:
| AWS DevOps |
Genera un piano di distribuzione. | Per generare un piano di distribuzione, esegui i comandi seguenti. Questi comandi inizializzano l'ambiente Terraform, uniscono le variabili di configurazione
| AWS DevOps |
Implementa le configurazioni. | Per distribuire le configurazioni, esegui il comando seguente:
| AWS DevOps |
Aggiorna altre configurazioni. | Per aggiornare le politiche AWS KMS chiave e archiviare gli output delle configurazioni applicate nel bucket Terraform Artifacts Amazon S3, esegui i seguenti comandi:
| AWS DevOps |
| Operazione | Description | Competenze richieste |
|---|---|---|
Carica file CSV di esempio. | Per caricare file CSV di esempio per i set di dati, procedi nel seguente modo:
| Ingegnere dei dati |
| Operazione | Description | Competenze richieste |
|---|---|---|
Configura Catena di approvvigionamento l'accesso. | Per configurare Catena di approvvigionamento l'accesso da Console di gestione AWS, procedi nel seguente modo:
| Proprietario dell'app |
| Operazione | Description | Competenze richieste |
|---|---|---|
Attiva il flusso di lavoro Destroy per le risorse dei flussi di integrazione. | Attiva il flusso di lavoro di distruzione | AWS DevOps |
Attiva il flusso di lavoro di distruzione delle risorse dei set di dati. | Attiva il flusso di lavoro di distruzione | AWS DevOps |
| Operazione | Description | Competenze richieste |
|---|---|---|
Passa alla directory | Per accedere alla
| AWS DevOps |
Configura il backend Terraform e la configurazione dei provider. | Per configurare il backend Terraform e la configurazione dei provider, utilizza il seguente script:
| AWS DevOps |
Genera un piano di distruzione dell'infrastruttura. | Per prepararti alla distruzione controllata dell' AWS infrastruttura generando un piano di smontaggio dettagliato, esegui i seguenti comandi. Il processo inizializza Terraform, incorpora le configurazioni Catena di approvvigionamento dei set di dati e crea un piano di distruzione che è possibile esaminare prima dell'esecuzione.
| AWS DevOps |
Esegui un piano di distruzione dell'infrastruttura. | Per eseguire la distruzione pianificata dell'infrastruttura, esegui il seguente comando:
| AWS DevOps |
Rimuovi gli output Terraform dal bucket Amazon S3. | Per rimuovere il file di output che è stato caricato durante la distribuzione di
| AWS DevOps |
| Operazione | Description | Competenze richieste |
|---|---|---|
Passa alla directory | Per accedere alla
| AWS DevOps |
Configura il backend Terraform e la configurazione dei provider. | Per configurare il backend Terraform e la configurazione dei provider, utilizza il seguente script:
| AWS DevOps |
Genera un piano di distruzione dell'infrastruttura. | Per creare un piano per la distruzione delle risorse del Catena di approvvigionamento set di dati, esegui i seguenti comandi:
| AWS DevOps |
Bucket Amazon S3 vuoti. | Per svuotare tutti i bucket Amazon S3 (tranne il bucket di registrazione degli accessi al server, che è configurato per
| AWS DevOps |
Esegui un piano di distruzione dell'infrastruttura. | Per eseguire la distruzione pianificata dell'infrastruttura del Catena di approvvigionamento set di dati utilizzando il piano generato, esegui il comando seguente:
| AWS DevOps |
Rimuovi gli output Terraform dal bucket di artefatti Terraform di Amazon S3. | Per completare il processo di pulizia, rimuovi il file di output che è stato caricato durante la distribuzione di eseguendo il comando seguente:
| AWS DevOps |
Risoluzione dei problemi
| Problema | Soluzione |
|---|---|
Un Catena di approvvigionamento set di dati o un flusso di integrazione non è stato distribuito correttamente a causa di errori Catena di approvvigionamento interni o autorizzazioni IAM insufficienti per il ruolo di servizio. | Innanzitutto, pulisci tutte le risorse. Quindi, ridistribuisci le risorse del Catena di approvvigionamentoset di dati e quindi ridistribuisci le risorse |
Il flusso di Catena di approvvigionamento integrazione non recupera i nuovi file di dati caricati per i set di dati. Catena di approvvigionamento |
|
Risorse correlate
AWS documentazione
Altre risorse
Comprensione dei flussi di lavoro di GitHub Actions
(GitHub documentazione)
Informazioni aggiuntive
Questa soluzione può essere replicata per più set di dati e può essere interrogata per ulteriori analisi, tramite dashboard predefiniti forniti o integrazione Catena di approvvigionamento personalizzata con Amazon Quick Sight. Inoltre, puoi utilizzare Amazon Q per porre domande relative alla tua Catena di approvvigionamento istanza.
Analizza i dati con Catena di approvvigionamento Analytics
Per istruzioni su come configurare Catena di approvvigionamento Analytics, consulta Impostazione di Catena di approvvigionamento Analytics nella Catena di approvvigionamento documentazione.
Questo modello ha dimostrato la creazione di set di dati Calendar e Outbound_Order_Line. Per creare un'analisi che utilizzi questi set di dati, procedi nel seguente modo:
Per analizzare i set di dati, utilizza la dashboard di Seasonality Analysis. Per aggiungere la dashboard, segui i passaggi in Dashboard predefiniti nella documentazione. Catena di approvvigionamento
Scegli la dashboard per visualizzarne l'analisi basata su file CSV di esempio per i dati del calendario e i dati della linea degli ordini in uscita.
La dashboard fornisce informazioni sulla domanda nel corso degli anni sulla base dei dati acquisiti per i set di dati. È possibile specificare ulteriormente ProductID, CustomerId, years e altri parametri per l'analisi.
Usa Amazon Q per porre domande relative alla tua Catena di approvvigionamento istanza
Amazon Q in Catena di approvvigionamento è un assistente AI generativo interattivo che ti aiuta a gestire la catena di approvvigionamento in modo più efficiente. Amazon Q può fare quanto segue:
Analizza i dati nel tuo Catena di approvvigionamento data lake.
Fornisci informazioni operative e finanziarie.
Rispondi alle tue domande immediate sulla catena di fornitura.
Per ulteriori informazioni sull'uso di Amazon Q, consulta la sezione Attivazione di Amazon Q in Catena di approvvigionamento e Uso di Amazon Q Catena di approvvigionamento nella Catena di approvvigionamento documentazione.
