Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Monitoraggio dell'applicazione
Il monitoraggio delle applicazioni fornisce una visione in tempo reale delle prestazioni dei servizi. Combina i dati topologici archiviati OpenSearch con le metriche RED di serie temporali (Rate, Errors, Duration) di Amazon Managed Service for Prometheus per far emergere informazioni su salute, latenza, velocità effettiva ed errore nel sistema distribuito.
Per accedere al monitoraggio delle applicazioni, nell'interfaccia utente accedi a Observability > Application Monitoring. OpenSearch La barra laterale mostra due visualizzazioni:
-
Mappa dell'applicazione: grafico topologico interattivo delle dipendenze dei servizi
-
Servizi: catalogo di tutti i servizi strumentati con filtri, visualizzazioni dettagliate e collegamenti di correlazione
Prerequisiti
Prima di poter utilizzare il monitoraggio delle applicazioni, è necessario aver configurato le seguenti risorse.
-
Uno spazio di lavoro dell'interfaccia utente con Observability abilitato OpenSearch
Come funziona
Il diagramma seguente mostra l'architettura end-to-end per il monitoraggio delle applicazioni.
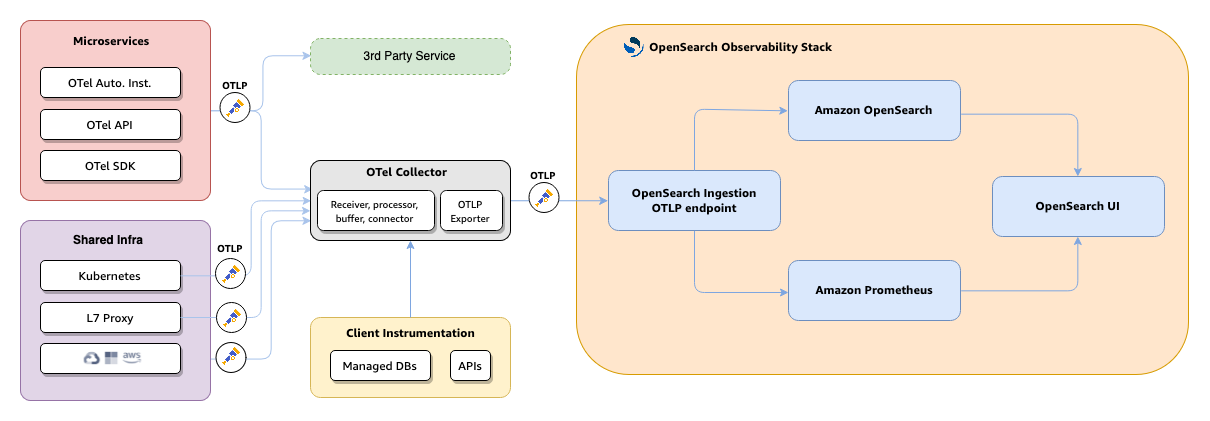
-
Le tue applicazioni e la tua infrastruttura trasmettono telemetria tramite OpenTelemetry SDK, strumentazione automatica o API OTel a Otel Collector.
-
L'Otel Collector inoltra i dati di tracciamento a Ingestion tramite OTLP. OpenSearch
-
Il
otel_apm_service_mapprocessore OpenSearch Ingestion estrae le relazioni da servizio a servizio e calcola le metriche RED. -
La topologia e i dati di traccia non elaborati vengono indicizzati in. OpenSearch Le metriche RED vengono esportate in Amazon Managed Service for Prometheus tramite scrittura remota.
-
OpenSearch L'interfaccia utente interroga entrambi gli store per visualizzare la mappa dell'applicazione, il catalogo dei servizi e le visualizzazioni dei dettagli del servizio.
Servizi
La visualizzazione Servizi fornisce un catalogo centralizzato di tutti i servizi strumentati, che mostra le metriche RED (Frequenza, Errori, Durata) a colpo d'occhio. Puoi utilizzare questa visualizzazione per identificare rapidamente i servizi non funzionanti e approfondire le visualizzazioni dettagliate per un'analisi più approfondita.
Per accedere alla vista Servizi, vai all'area di lavoro Observability nell' OpenSearch interfaccia utente e scegli APM > Servizi.
La home page dei Servizi mostra una tabella di tutti i servizi strumentati insieme a pannelli di riepilogo. L'immagine seguente mostra la home page dei Servizi.
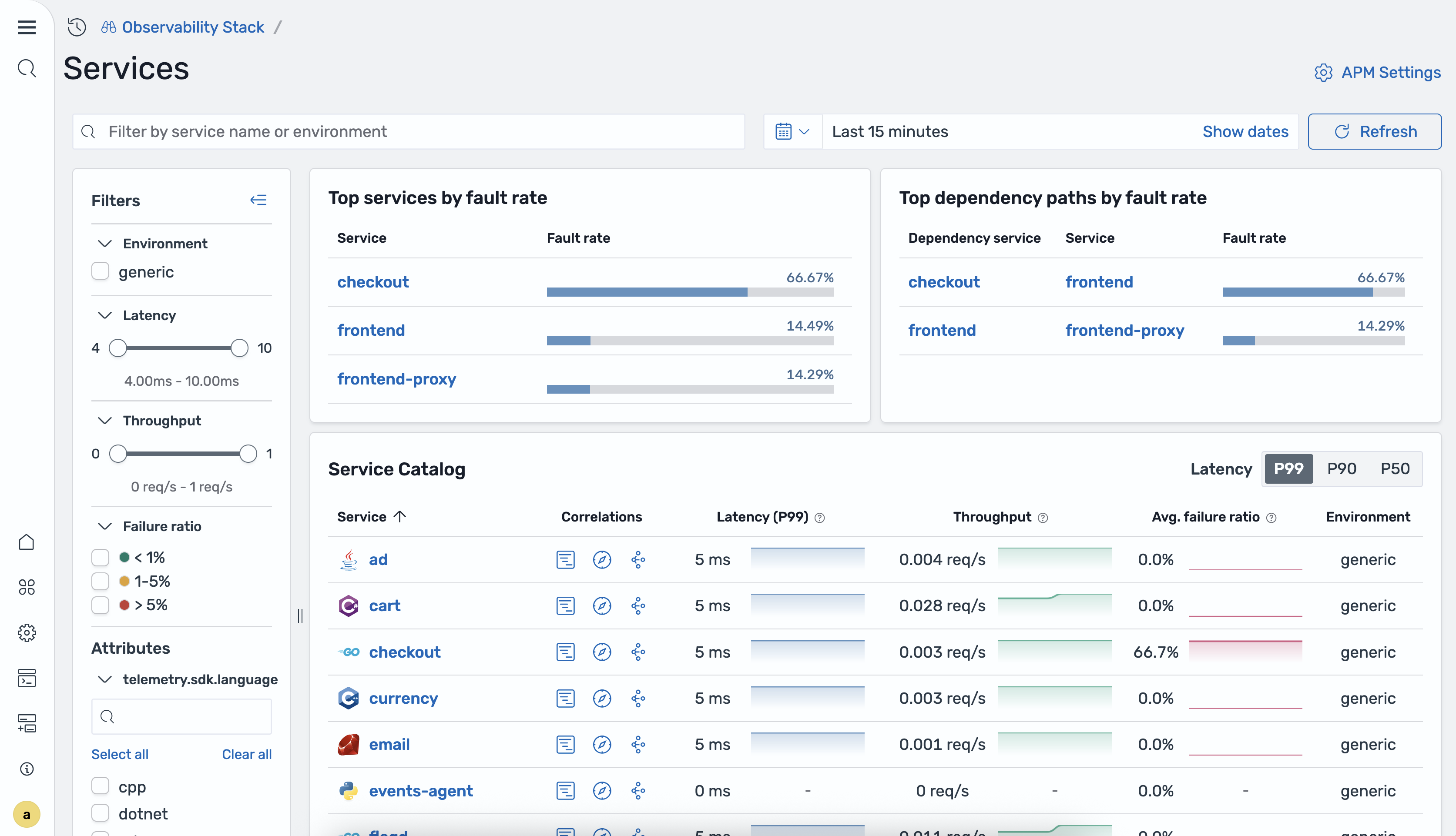
La tabella seguente descrive le colonne della tabella dei servizi.
| Colonna | Description |
|---|---|
| Nome del servizio | Il nome del servizio strumentato. |
| Latenza P99 | La latenza del 99° percentile per il servizio. |
| Latenza P90 | Latenza del 90° percentile per il servizio. |
| Latenza P50 | La latenza del 50° percentile (mediana) del servizio. |
| Total Requests (Richieste totali) | Il numero totale di richieste elaborate nell'intervallo di tempo selezionato. |
| Rapporto di fallimento | Il rapporto tra richieste non riuscite e richieste totali. |
| Ambiente | L'ambiente di distribuzione del servizio, ad esempio production ostaging. |
La home page include anche i seguenti pannelli di riepilogo:
-
I migliori servizi per percentuale di errore: servizi con la più alta percentuale di risposte 5xx.
-
Principali percorsi di dipendenza in base alla frequenza di errore: percorsi di Service-to-service dipendenza con i tassi di errore più elevati.
È possibile filtrare la tabella dei servizi utilizzando i seguenti filtri:
-
Ambiente: filtra per ambiente di distribuzione.
-
Latenza: filtra per intervallo di latenza.
-
Throughput: filtra in base all'intervallo di throughput della richiesta.
-
Rapporto di guasto: filtra per intervallo del rapporto di guasto.
Panoramica del servizio
Per aprire la visualizzazione dettagliata del servizio, selezionare un nome di servizio nella tabella dei servizi. La scheda Panoramica mostra riquadri metrici e grafici delle serie temporali per il servizio selezionato.
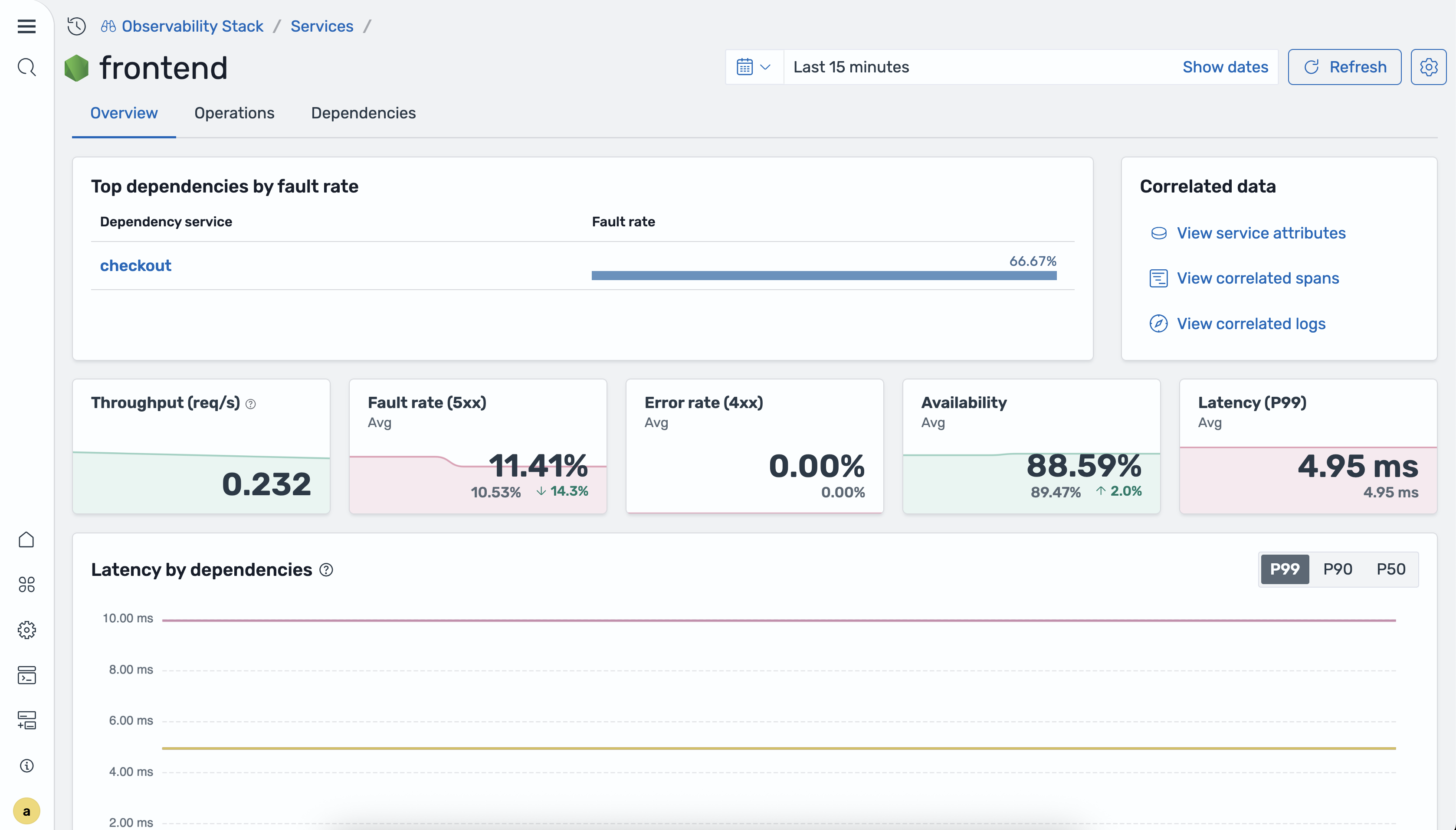
La scheda Panoramica include i seguenti grafici delle serie temporali:
-
Latenza per dipendenze del servizio: latenza P50, P90 e P99 suddivisa per dipendenze a valle.
-
Richieste per operazioni: volume delle richieste per ogni operazione del servizio.
-
Disponibilità per operazioni: percentuale di risposte riuscite per ciascuna operazione.
-
Percentuale di guasti e tasso di errore per operazione: percentuale di risposte 5xx e 4xx per ogni operazione.
Operazioni
La scheda Operazioni fornisce una suddivisione per operazione per il servizio selezionato. È possibile ordinare la tabella in base a qualsiasi colonna per identificare le operazioni problematiche.
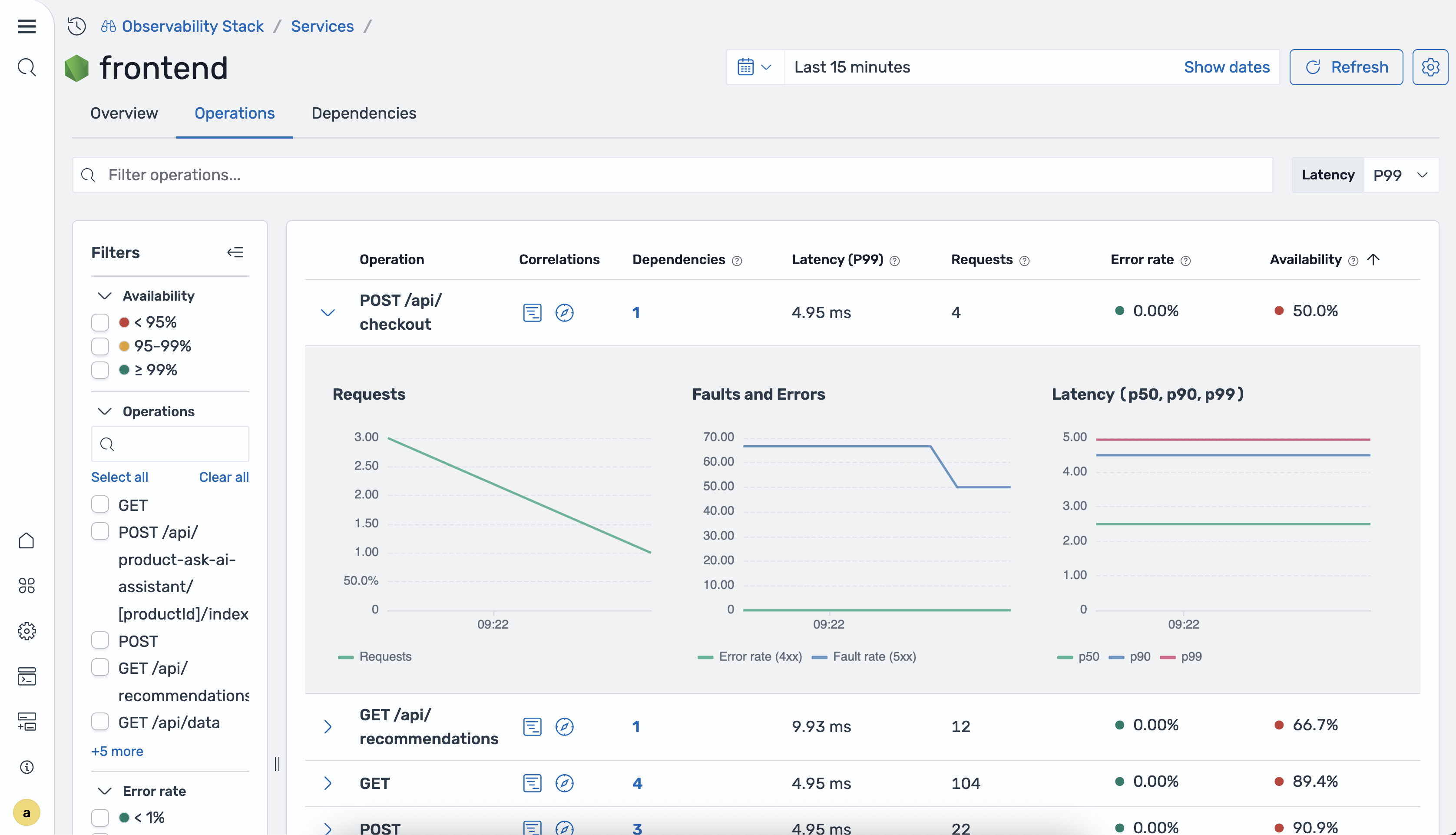
La tabella seguente descrive le colonne della tabella delle operazioni.
| Colonna | Description |
|---|---|
| Nome operazione | Il nome dell'operazione. |
| P50/P90/P99 latenza | La latenza del 50°, 90° e 99° percentile per l'operazione. |
| Total Requests (Richieste totali) | Il numero totale di richieste per l'operazione nell'intervallo di tempo selezionato. |
| Tasso di errore | La percentuale di richieste che hanno restituito errori. |
| Disponibilità | La percentuale di risposte riuscite per l'operazione. |
Dipendenze
La scheda Dipendenze mostra i servizi a valle richiamati dal servizio selezionato.
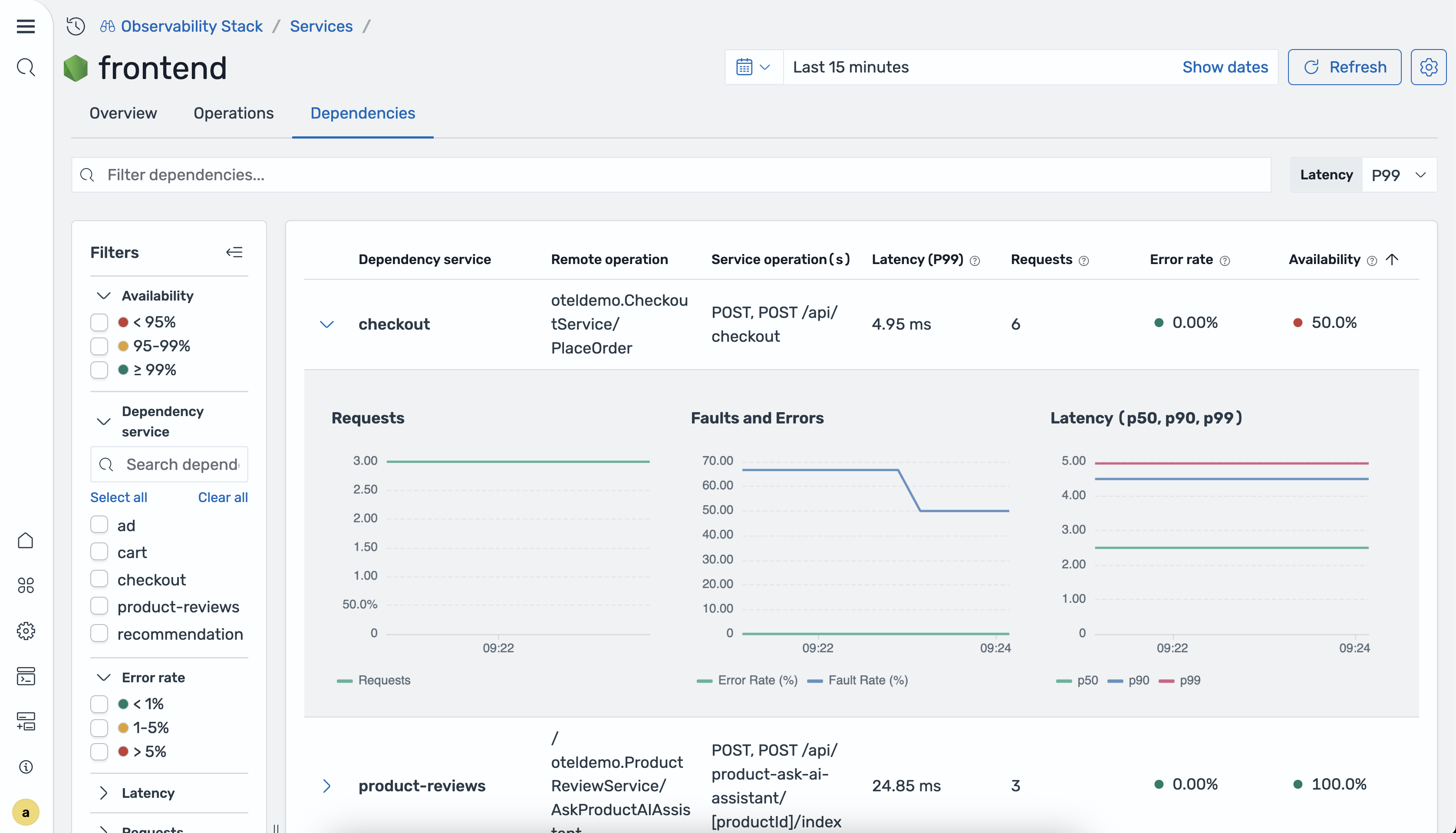
La tabella seguente descrive le colonne della tabella delle dipendenze.
| Colonna | Description |
|---|---|
| Servizio di dipendenza | Il nome del servizio downstream. |
| Funzionamento remoto | L'operazione richiamata dal servizio downstream. |
| Operazioni di servizio | Le operazioni sul servizio corrente che richiamano questa dipendenza. |
| P99/P90/P50 latenza | La latenza del 99°, 90° e 50° percentile per il percorso di dipendenza. |
| Total Requests (Richieste totali) | Il numero totale di richieste alla dipendenza durante l'intervallo di tempo selezionato. |
| Tasso di errore | La percentuale di richieste alla dipendenza che hanno restituito errori. |
| Disponibilità | La percentuale di risposte riuscite derivanti dalla dipendenza. |
Correlazioni
La visualizzazione dettagliata del servizio fornisce correlazioni contestuali che consentono di passare dalle metriche del servizio direttamente alle tracce e ai log correlati. È possibile utilizzare le correlazioni per analizzare la causa principale dei picchi di latenza o degli aumenti del tasso di errore.
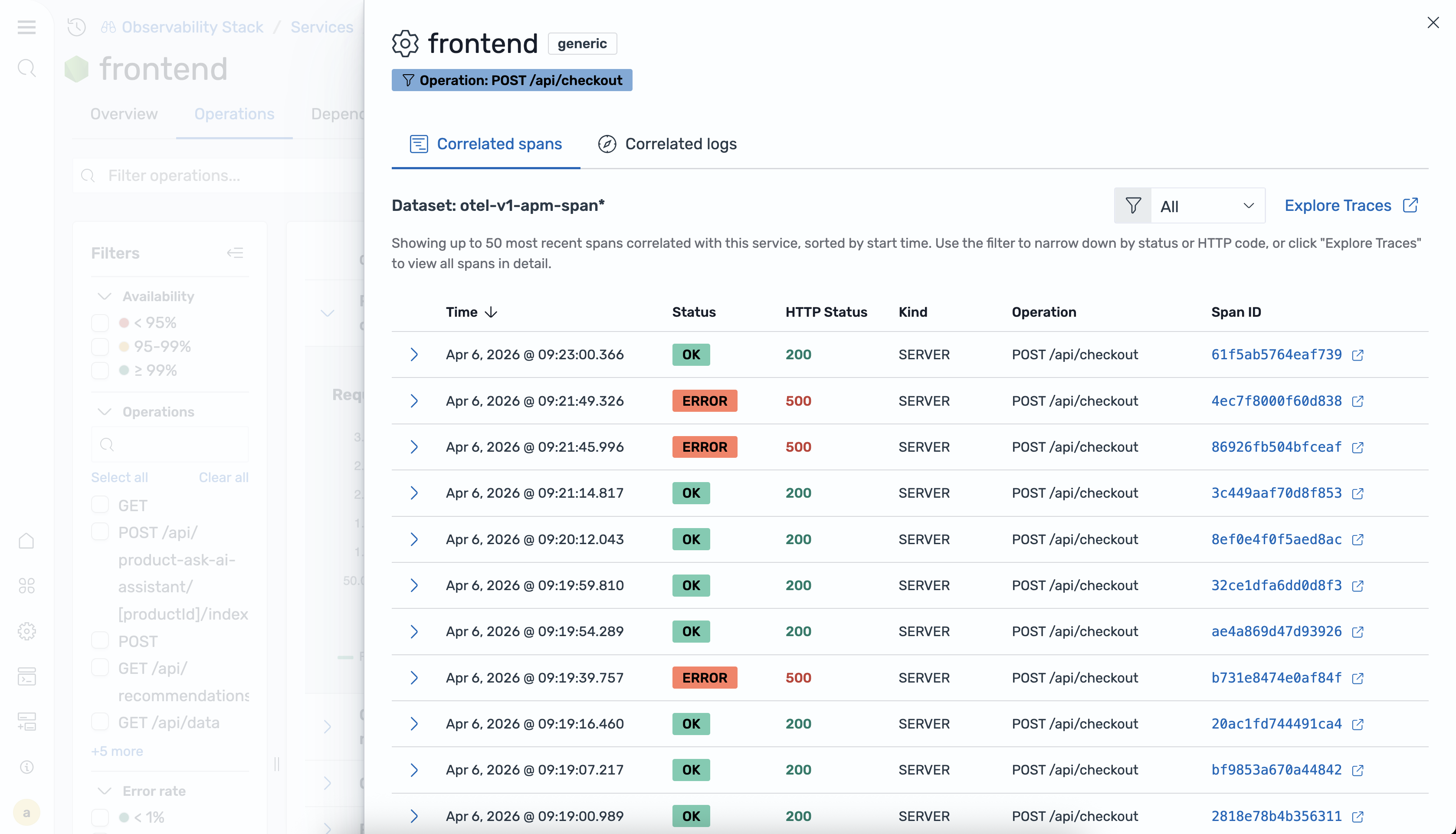
Sono disponibili le seguenti opzioni di correlazione:
-
Visualizza tracce correlate: apre una visualizzazione di traccia filtrata per il servizio o l'operazione selezionati.
-
Visualizza registri correlati: apre una visualizzazione di registro filtrata per il servizio o l'operazione selezionati.
-
Filtra per attributi: limita i risultati di correlazione in base a specifici attributi span.
Mappa dell'applicazione
L'Application Map è una visualizzazione topologica interattiva che OpenSearch Ingestion genera automaticamente dai dati di traccia utilizzando il processore. otel_apm_service_map La mappa mostra i servizi come nodi con bordi direzionali che mostrano schemi di comunicazione, sovrapposti a metriche RED (Rate, Errors, Duration).
Per accedere alla mappa dell'applicazione, vai all'area di lavoro Observability nell' OpenSearch interfaccia utente e scegli APM > Mappa dell'applicazione.
L'immagine seguente mostra la mappa dell'applicazione.
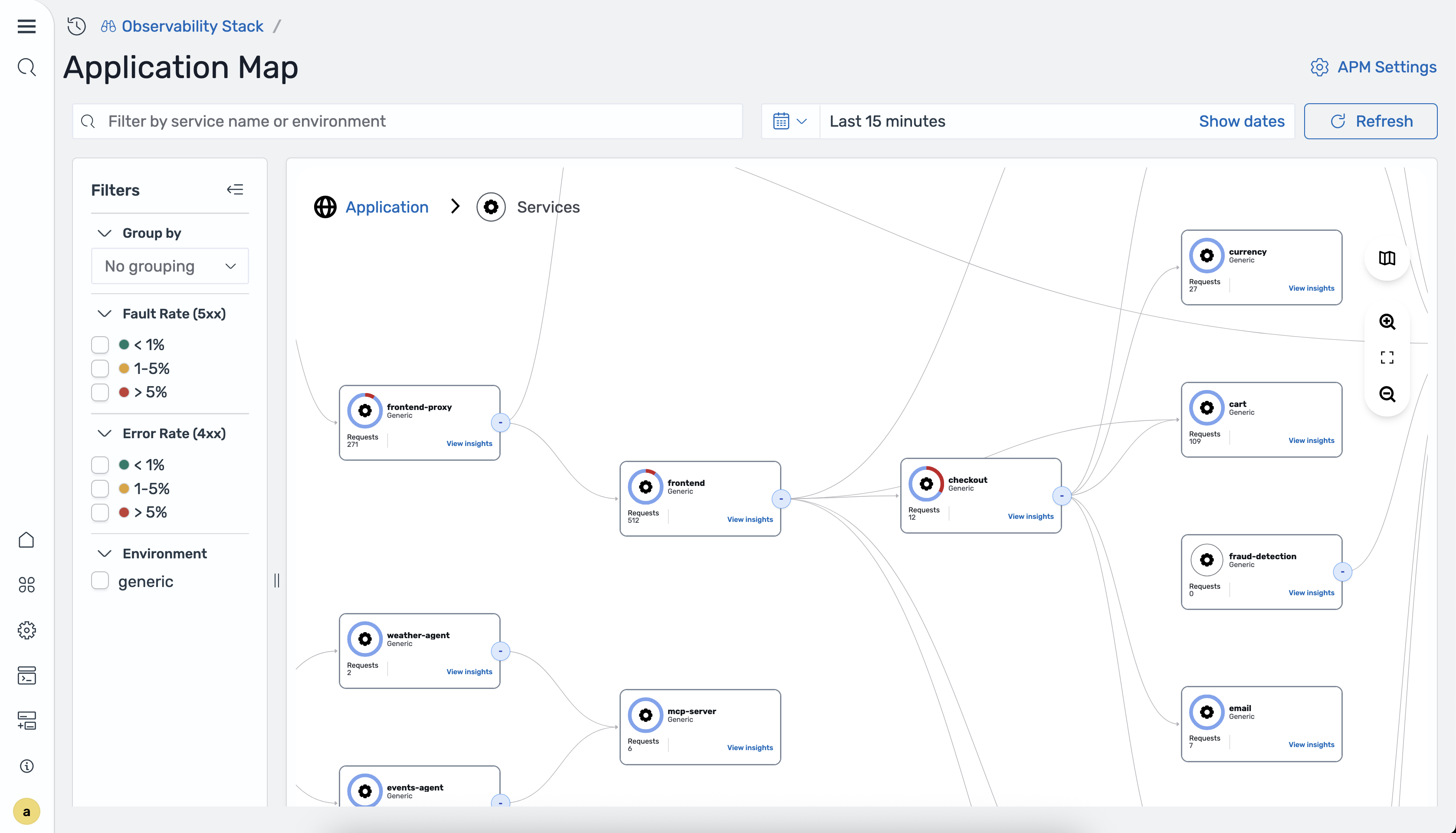
La mappa mostra le seguenti metriche ROSSE per ogni servizio:
-
Frequenza: richieste al secondo elaborate dal servizio.
-
Errori: percentuale di risposte 4xx e 5xx.
-
Durata: latenza P50 e P99 per il servizio.
Il otel_apm_service_map processore genera queste metriche e le archivia in Amazon Managed Service for Prometheus tramite scrittura remota.
La visualizzazione della topologia rappresenta i servizi come nodi e la direzione della comunicazione come bordi. La codifica a colori indica lo stato di salute di ogni servizio. La mappa si aggiorna automaticamente non appena OpenSearch Ingestion acquisisce nuovi dati di traccia.
Servizi di raggruppamento
È possibile raggruppare i servizi in base ad attributi quali linguaggio di programmazione, team o ambiente. Quando si seleziona un attributo raggruppato per, la mappa passa da un grafico della topologia a una visualizzazione a griglia a schede. Ogni scheda rappresenta un gruppo di servizi che condividono lo stesso valore di attributo.
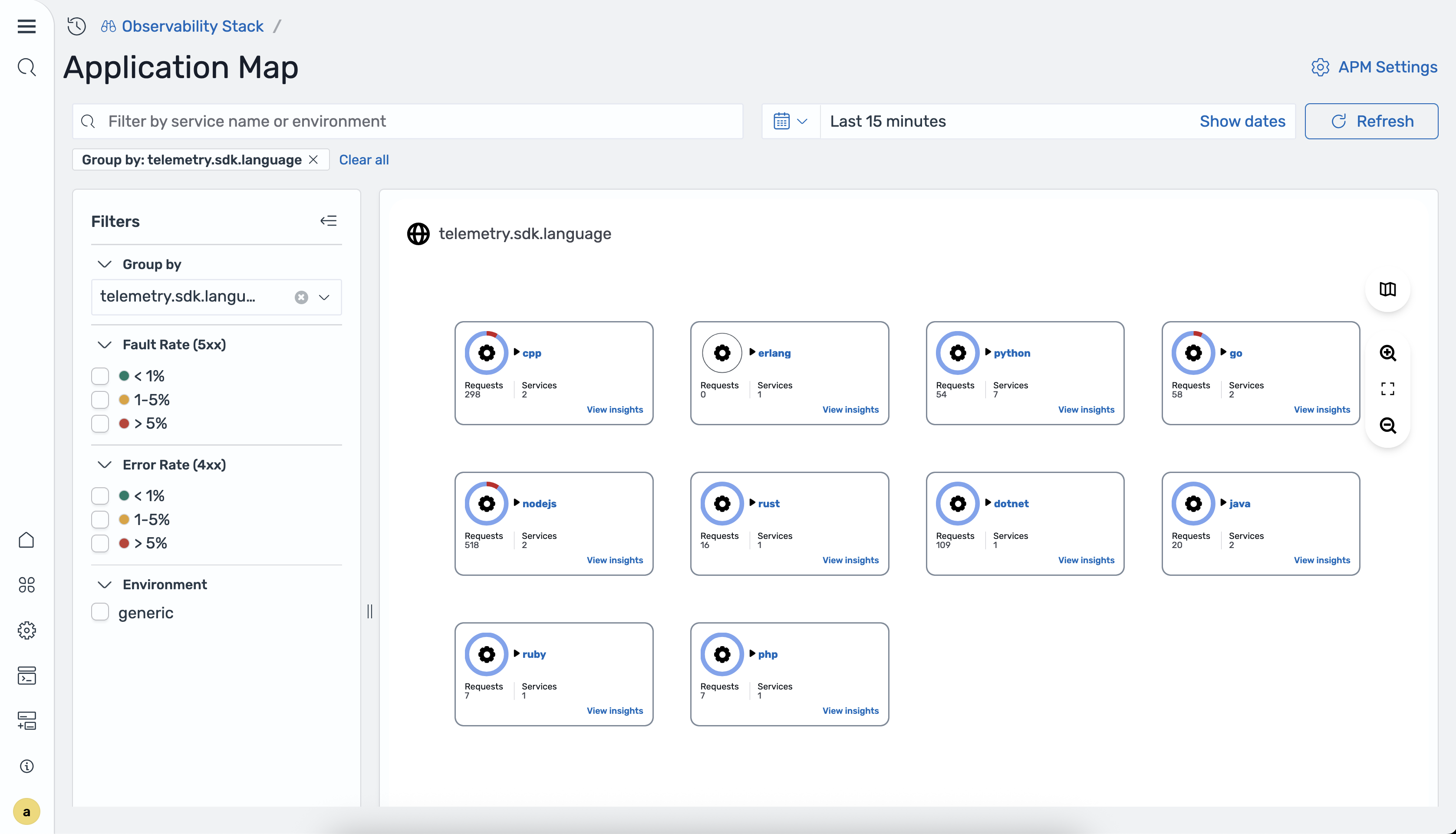
Gli attributi raggruppati per disponibili sono determinati dall'impostazione nella configurazione del processore in Ingestion. group_by_attributes otel_apm_service_map OpenSearch
Visualizzazione dei dettagli dei nodi
Per visualizzare i dettagli di un servizio, selezionare un nodo sulla mappa. Si apre un pannello di dettaglio con le seguenti sezioni.
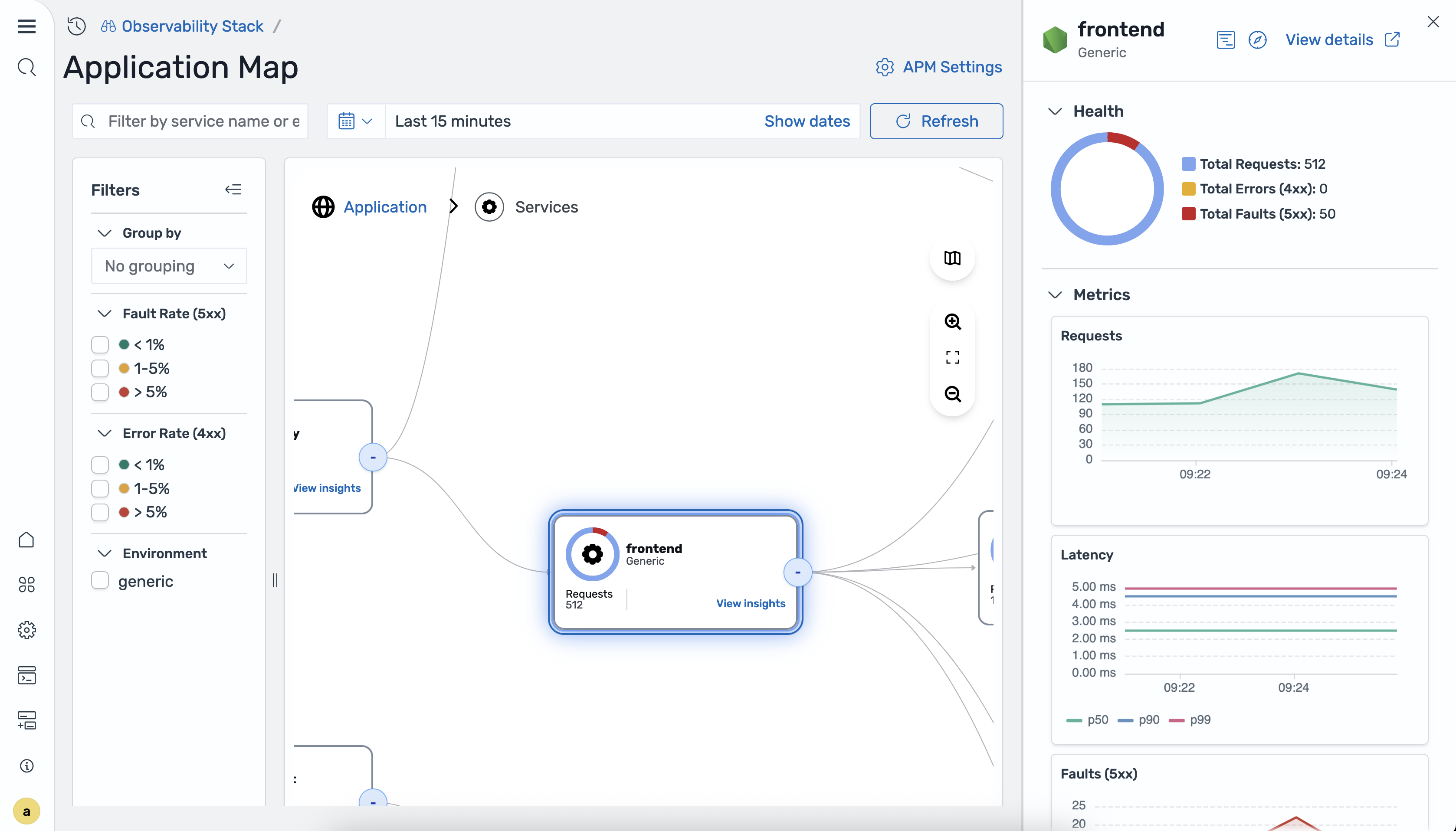
La sezione Health mostra le seguenti metriche di riepilogo:
-
Total Requests (Richieste totali)
-
Errori totali 4xx
-
Difetti totali 5xx
La sezione Metriche mostra i seguenti grafici delle serie temporali:
-
Richieste
-
Latenza P50/P90/P99
-
Guasti 5xx
-
Errori 4xx
Scegli Visualizza dettagli per accedere alla visualizzazione dei dettagli dei servizi per il servizio selezionato.
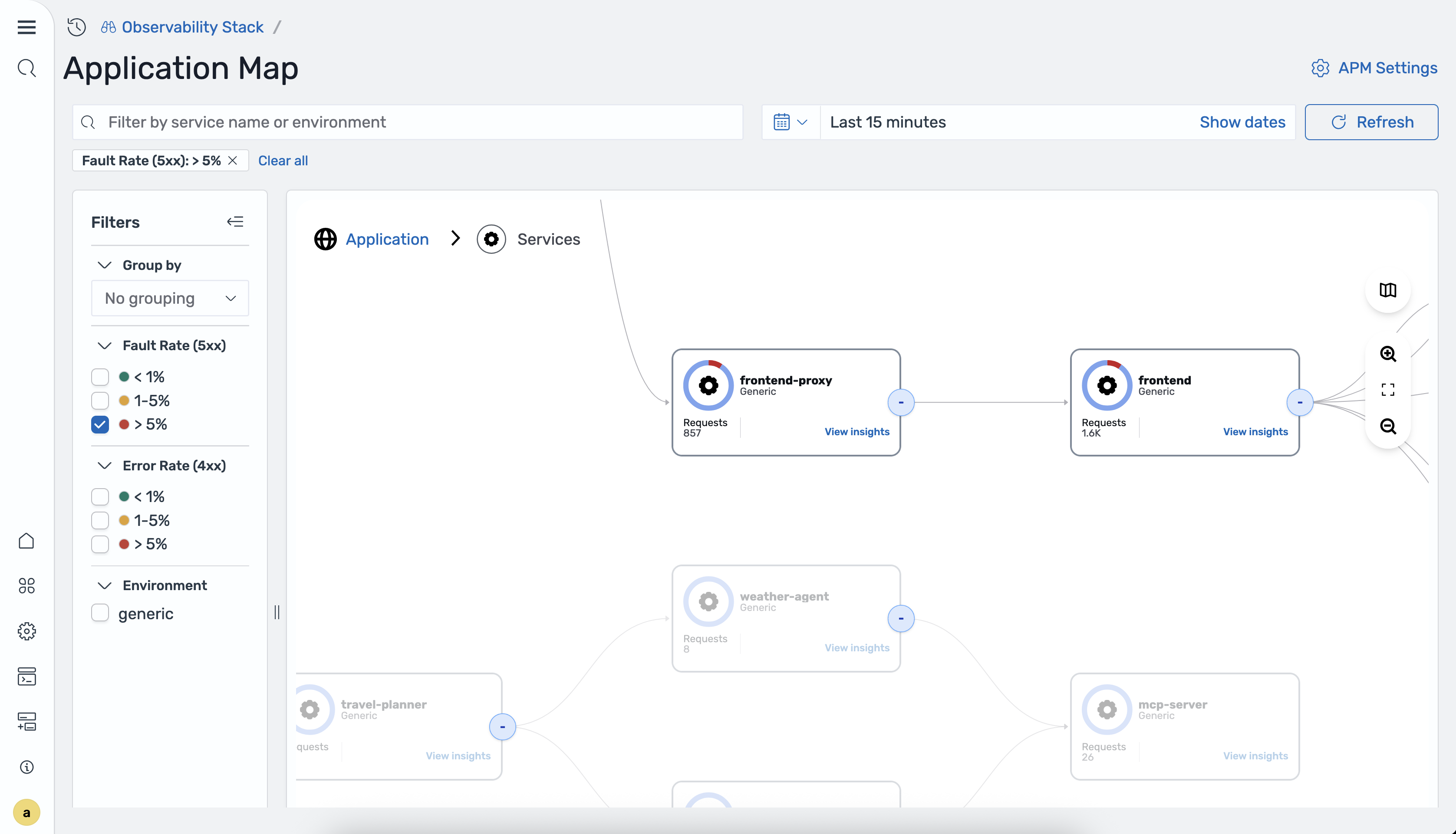
Filtrare la mappa
È possibile filtrare la mappa dell'applicazione utilizzando i seguenti filtri:
-
Frequenza di errore: filtra i servizi in base alla frequenza di errore lato server (5xx).
-
Frequenza di errore: filtra i servizi in base alla frequenza di errore lato client (4xx).
-
Ambiente: filtra i servizi per ambiente di distribuzione.
L'immagine seguente mostra la mappa filtrata per tasso di errore.
In-context correlazioni
È possibile passare dalla vista topologica direttamente alle tracce e ai log correlati. Da qualsiasi nodo di servizio, sono disponibili le seguenti opzioni di correlazione:
-
Visualizza tracce correlate: apre una visualizzazione di traccia filtrata per il servizio selezionato.
-
Visualizza log correlati: apre una visualizzazione di log filtrata per il servizio selezionato.
