Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta [Cos'è Amazon Machine Learning](https://docs.aws.amazon.com/machine-learning/latest/dg/what-is-amazon-machine-learning.html).
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
# Cross-Validation
Cross-validation è una tecnica per valutare i modelli ML addestrando diversi modelli ML su sottoinsiemi dei dati di input disponibili e valutandoli sul sottoinsieme complementare di dati. Per rilevare l'overfitting, ossia la mancata generalizzazione di un modello, usare la convalida incrociata.
In Amazon ML, puoi utilizzare il metodo di convalida incrociata k-fold per eseguire la convalida incrociata. Nella convalida incrociata k-fold, dividi i dati di input in k sottoinsiemi di dati (noti anche come pieghe). Si addestra un modello di machine learning su tutti i sottoinsiemi tranne uno (k-1), quindi si valuta il modello sul sottoinsieme che non è stato utilizzato per l'addestramento. Questo processo viene ripetuto k volte, ogni volta con un diverso sottoinsieme riservato per la valutazione (ed escluso dall'addestramento).
Il seguente diagramma mostra un esempio dei sottoinsiemi di addestramento e dei sottoinsiemi di valutazione complementari generati per ciascuno dei quattro modelli che vengono creati e addestrati durante una convalida incrociata per 4 volte. Il modello uno utilizza il primo 25% dei dati per la valutazione e il restante 75% per l'addestramento. Il modello due usa il secondo sottoinsieme, pari al 25% (dal 25% al 50%), per la valutazione, mentre i restanti tre sottoinsiemi dei dati sono utilizzati per l'addestramento e così via.
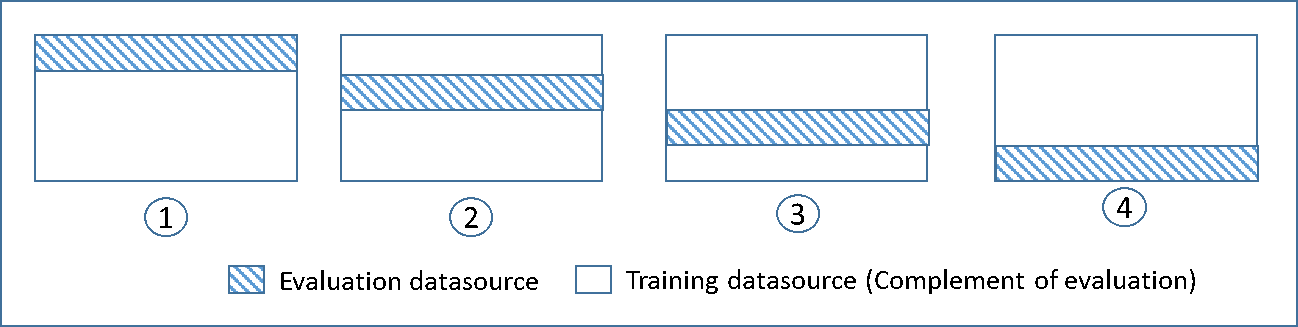
Ogni modello è addestrato e valutato utilizzando origini dati complementari: i dati dell'origine dati di valutazione includono e sono limitati a tutti i dati che non fanno parte dell'origine dati di addestramento. È possibile creare origini dati per ciascuno di questi sottoinsiemi con il parametro `DataRearrangement` nel `createDatasourceFromS3`, `createDatasourceFromRedShift`e nelle API `createDatasourceFromRDS`. Nel parametro `DataRearrangement`, si specifica il sottoinsieme di dati da includere in un'origine dati indicando dove iniziare e terminare ogni segmento. Per creare le origini dati complementari richieste per una 4k-fold cross-validation, si specifica il parametro `DataRearrangement` come nell'esempio seguente:
**Modello uno:**
Origine dati per la valutazione:
```
{"splitting":{"percentBegin":0, "percentEnd":25}}
```
Origine dati per l'addestramento:
```
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
```
**Modello due:**
Origine dati per la valutazione:
```
{"splitting":{"percentBegin":25, "percentEnd":50}}
```
Origine dati per l'addestramento:
```
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
```
**Modello tre:**
Origine dati per la valutazione:
```
{"splitting":{"percentBegin":50, "percentEnd":75}}
```
Origine dati per l'addestramento:
```
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
```
**Modello quattro:**
Origine dati per la valutazione:
```
{"splitting":{"percentBegin":75, "percentEnd":100}}
```
Origine dati per l'addestramento:
```
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
```
L'esecuzione di una convalida incrociata quadrupla genera quattro modelli, quattro origini dati per addestrare i modelli, quattro fonti di dati per valutare i modelli e quattro valutazioni, una per ogni modello. Amazon ML genera una metrica prestazionale del modello per ogni valutazione. Ad esempio, in una 4-fold cross-validation per un problema di classificazione binaria, ciascuna delle valutazioni segnala un parametro AUC (Area Under Curve). È possibile ottenere le prestazioni complessive misurate calcolando la media dei quattro parametri AUC. Per ulteriori informazioni sul parametro AUC, consultare [Misurazione dell'accuratezza del modello ML](binary-model-insights.md#measuring-ml-model-accuracy).
Per un codice di esempio che mostra come creare una convalida incrociata e calcolare la media dei punteggi del modello, consulta il codice di [esempio di Amazon ML](https://github.com/awslabs/machine-learning-samples).
## Regolazione dei modelli
Dopo aver effettuato la convalida incrociata dei modelli, è possibile regolare le impostazioni per il modello successivo se le prestazioni del modello non sono all'altezza delle aspettative. Per ulteriori informazioni sull'overfitting, consultare [Fitting del modello: underfitting e overfitting](model-fit-underfitting-vs-overfitting.md). Per ulteriori informazioni sulla regolarizzazione, consultare [Regolarizzazione](training-parameters1.md#regularization). Per ulteriori informazioni sulla modifica delle impostazioni di regolarizzazione, consultare [Creazione di un modello ML con opzioni personalizzate](creating-ml-model-on-the-amazon-ml-console.md#creating-ml-model-using-custom-settings).