Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo del CloudWatch rilevamento delle anomalie
Quando abiliti il rilevamento delle anomalie per una metrica, CloudWatch applica algoritmi statistici e di apprendimento automatico. Questi algoritmi analizzano continuamente i parametri di sistemi e applicazioni, determinano le normali linee di base e le anomalie superficiali con un intervento minimo dell'utente.
Gli algoritmi generano un modello di rilevamento delle anomalie. Il modello genera un intervallo di valori previsti che rappresentano il normale comportamento del parametro.
Puoi abilitare il rilevamento delle anomalie utilizzando l' Console di gestione AWS, l'o l' AWS CLI SDK CloudFormation. AWS Puoi abilitare il rilevamento delle anomalie sulle metriche fornite da AWS e anche sulle metriche personalizzate. In un account configurato come account di monitoraggio per l'osservabilità tra più CloudWatch account, puoi creare rilevatori di anomalie sulle metriche degli account di origine oltre alle metriche dell'account di monitoraggio.
Puoi utilizzare il modello di valori previsti in due modi:
Crea allarmi basati sul rilevamento delle anomalie, ovvero allarmi basati sul valore previsto di un parametro. Questi tipi di allarmi non hanno una soglia statica per determinare lo stato dell'allarme. Confrontano invece il valore del parametro con il valore previsto, in base al modello di rilevamento delle anomalie.
Puoi decidere se l'allarme viene attivato quando il valore del parametro è al di sopra dell'intervallo di valori previsti, si trova al di sotto di tale intervallo oppure in entrambi i casi.
Per ulteriori informazioni, consulta Crea un CloudWatch allarme basato sul rilevamento delle anomalie.
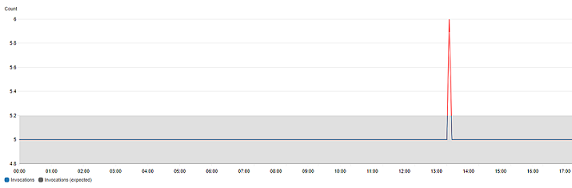
Quando si visualizza un grafico di dati di parametri, i valori previsti vengono sovrapposti nel grafico sotto forma di intervallo. Ciò rende visivamente chiaro quali valori nel grafico non sono compresi nell'intervallo normale. Per ulteriori informazioni, consulta Creazione di un grafico.
Puoi anche recuperare i valori superiore e inferiore dell'intervallo del modello mediante la richiesta API
GetMetricDatacon la funzione matematicaANOMALY_DETECTION_BANDdel parametro. Per ulteriori informazioni, consulta GetMetricData.
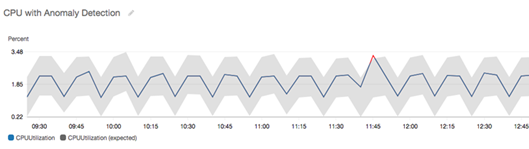
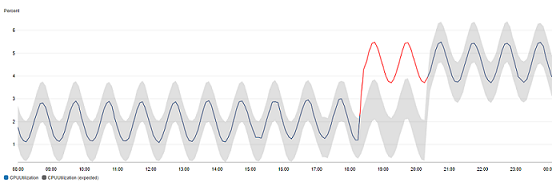
In un grafico con rilevamento di anomalie, l'intervallo di valori previsto viene mostrato come un intervallo grigio. Se il valore effettivo del parametro va oltre questo intervallo, viene visualizzato in rosso per tale periodo.
Gli algoritmi di rilevamento delle anomalie tengono conto delle variazioni di stagionalità e di tendenza dei parametri. Le variazioni di stagionalità potrebbero essere orarie, giornaliere o settimanali, come mostrato negli esempi seguenti.
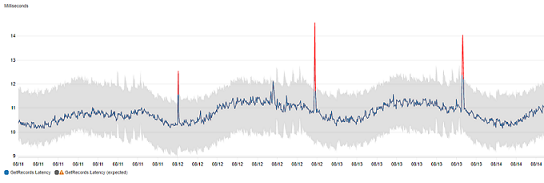
Le tendenze con intervallo più lungo possono essere al ribasso o al rialzo.
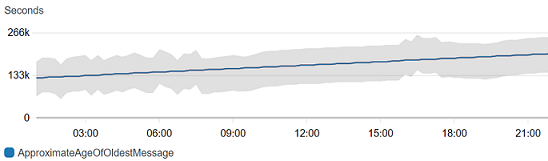
Il rilevamento delle anomalie funziona bene anche con metriche con pattern piatti.
Come funziona il rilevamento CloudWatch delle anomalie
Quando abiliti il rilevamento delle anomalie per una metrica, CloudWatch applica algoritmi di apprendimento automatico ai dati passati della metrica per creare un modello dei valori previsti della metrica. Il modello valuta sia le tendenze che i pattern orari, giornalieri e settimanali del parametro. L'algoritmo esegue l'apprendimento in base a due settimane di dati del parametro, ma puoi abilitare il rilevamento di anomalie per un parametro anche se il parametro non dispone di tale intervallo di dati.
Specificate un valore per la soglia di rilevamento delle anomalie che CloudWatch viene utilizzato insieme al modello per determinare l'intervallo di valori «normale» per la metrica. Un valore più alto per la soglia del rilevamento delle anomalie produce un intervallo più ampio di valori "normali".
Il modello di machine learning è specifico di un parametro o di una funzione statistica. Ad esempio, se abiliti il rilevamento di anomalie per un parametro mediante la funzione statistica AVG, il modello fa riferimento specifico alla funzione statistica AVG.
Quando CloudWatch crea un modello per molte metriche comuni a partire dai AWS servizi, assicura che la banda non si estenda al di fuori dei valori logici. Ad esempio, la banda MemoryUtilization di un'istanza EC2 rimarrà compresa tra 0 e 100 e il tracciamento delle bande, che non può essere negativo CloudFront Requests, non si estenderà mai al di sotto dello zero.
Dopo aver creato un modello, il rilevamento delle CloudWatch anomalie valuta continuamente il modello e lo aggiusta per garantire che sia il più preciso possibile. Ciò include riaddestrare il modello per regolare se i valori dei parametri si evolvono nel tempo o presentano cambiamenti improvvisi, e include anche i predittori per migliorare i modelli di parametri stagionali, variabili o sparse.
Dopo aver abilitato il rilevamento di anomalie per un parametro, per l'apprendimento automatico del modello puoi scegliere di escludere l'uso di periodi di tempo specifici relativi al parametro in questione. In questo modo, puoi escludere l'uso di distribuzioni o di altri eventi insoliti durante l'apprendimento automatico del modello in modo da garantire la creazione di un modello più preciso.
L'utilizzo di modelli di rilevamento delle anomalie per gli allarmi comporta addebiti sull'account. AWS Per ulteriori informazioni, consulta Prezzi di Amazon CloudWatch
Rilevamento di anomalie sulla matematica del parametro
Il rilevamento di anomalie sulla matematica del parametro è una funzione che è possibile utilizzare per creare allarmi di rilevamento anomalie sull'output di espressioni matematiche dei parametri. È possibile utilizzare queste espressioni per creare grafici che visualizzano le bande di rilevamento delle anomalie. La funzione supporta funzioni aritmetiche di base, operatori logici e confronto e la maggior parte delle altre funzioni. Per informazioni sulle funzioni che non sono supportate, consulta Using metric Math nella Amazon CloudWatch User Guide.
È possibile creare modelli di rilevamento anomalie basati su espressioni matematiche dei parametri simili a come si creano già modelli di rilevamento delle anomalie. Dalla CloudWatch console, puoi applicare il rilevamento delle anomalie alle espressioni matematiche metriche e selezionare il rilevamento delle anomalie come tipo di soglia per queste espressioni.
Nota
Il rilevamento delle anomalie solo sulla matematica dei parametri può essere abilitato e modificato nell'ultima versione dell'interfaccia utente dei parametri. Quando si creano rilevatori di anomalie basati su espressioni matematiche dei parametri nella nuova versione dell'interfaccia, è possibile visualizzarli nella versione precedente, ma non modificarli.
Per informazioni su come creare, modificare ed eliminare allarmi e modelli per il rilevamento delle anomalie e la matematica metrica, consulta le seguenti sezioni:
Puoi anche creare, eliminare e scoprire modelli di rilevamento delle anomalie basati su espressioni matematiche metriche utilizzando l' CloudWatch API con, e. PutAnomalyDetector DeleteAnomalyDetector DescribeAnomalyDetectors Per informazioni su queste azioni API, consulta le seguenti sezioni in Amazon CloudWatch API Reference.
Rilevamento delle anomalie tramite PromQL
È possibile creare bande di rilevamento delle anomalie per qualsiasi metrica compatibile con Prometheus utilizzando funzioni PromQL standard come, e. quantile_over_time stddev_over_time avg_over_time Questo approccio calcola una linea di base e aggiunge o sottrae una deviazione standard scalata per definire limiti superiori e inferiori che si adattano ai modelli naturali della metrica.
Questo funziona per qualsiasi metrica che restituisce un valore float, come l'utilizzo della CPU, la latenza delle richieste o il conteggio degli errori. Per informazioni sull'acquisizione di metriche utilizzando, consulta. OpenTelemetry OpenTelemetry
Definizione dei limiti superiore e inferiore
Per definire un intervallo previsto per una metrica, calcola una linea di base utilizzando la mediana o la media su una finestra temporale, quindi aggiungi e sottrai un multiplo della deviazione standard. Il moltiplicatore controlla la sensibilità: valori più alti producono bande più ampie con meno falsi positivi, mentre valori più bassi catturano deviazioni più piccole.
L'esempio seguente crea un limite superiore per una metrica di richiesta di annuncio utilizzando una finestra di 60 minuti e un moltiplicatore di 3:
quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) + 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m)
L'esempio seguente crea il limite inferiore corrispondente. La clamp_min funzione impedisce che il limite inferiore diventi negativo per le metriche che non possono avere valori negativi:
clamp_min( quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) - 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m), 0)
Puoi rappresentare graficamente entrambi i limiti in CloudWatch Query Studio per visualizzare l'intervallo previsto per la tua metrica. Per ulteriori informazioni, consulta Esecuzione di query ProMQL in Query Studio.
Rilevamento delle violazioni
Per rilevare quando una metrica non rientra nell'intervallo previsto, combina entrambi i limiti in un'unica query. L'espressione seguente restituisce solo i punti dati in cui il valore della metrica supera il limite superiore o scende al di sotto del limite inferiore:
1 * {"app.ads.ad_requests"} > quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) + 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m) or 1 * {"app.ads.ad_requests"} < clamp_min( quantile_over_time(0.5, {"app.ads.ad_requests"}[60m] offset 1m) - 3 * stddev_over_time({"app.ads.ad_requests"}[60m] offset 1m), 0)
Questa query funziona su più valori di etichetta, quindi puoi rilevare anomalie nell'intera flotta in un'unica query. È possibile utilizzare questa espressione per creare un allarme ProMQL che si attiva quando una serie temporale supera l'intervallo previsto. Per ulteriori informazioni, consulta Creazione di un CloudWatch allarme utilizzando PromQL per il rilevamento delle anomalie.
