Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Sistem Pemantauan Kesehatan
SageMaker HyperPod Sistem pemantauan kesehatan mencakup dua komponen
-
Agen pemantauan dipasang di node Anda, yang mencakup Agen Pemantau Kesehatan (HMA) yang berfungsi sebagai monitor kesehatan on-host dan satu set monitor kesehatan out-of-node.
-
Sistem Pemulihan Node dikelola oleh SageMaker HyperPod. Sistem pemantauan kesehatan akan memantau status kesehatan node secara terus menerus melalui agen pemantauan dan kemudian mengambil tindakan secara otomatis ketika kesalahan terdeteksi menggunakan Sistem Pemulihan Node.

Pemeriksaan kesehatan dilakukan oleh agen SageMaker HyperPod pemantau kesehatan
Agen SageMaker HyperPod pemantau kesehatan memeriksa hal-hal berikut.
GPU NVIDIA
-
Kesalahan dalam
nvidia-smioutput -
Berbagai kesalahan dalam log yang dihasilkan oleh platform Amazon Elastic Compute Cloud (EC2)
-
Validasi Hitungan GPU — jika ada ketidakcocokan antara jumlah GPU yang diharapkan dalam jenis instance tertentu (misalnya: 8 GPU dalam tipe instans ml.p5.48xlarge) dan jumlah yang dikembalikan oleh, maka HMA me-reboot node
nvidia-smi
AWS Trainium
-
Kesalahan dalam output dari monitor AWS Neuron
-
Output yang dihasilkan oleh detektor masalah simpul Neuron (Untuk informasi lebih lanjut tentang detektor masalah simpul AWS Neuron, lihat Deteksi dan pemulihan masalah Node untuk node AWS Neuron dalam kluster Amazon EKS
.) -
Berbagai kesalahan dalam log yang dihasilkan oleh platform Amazon EC2
-
Validasi Hitungan Perangkat Neuron — jika ada ketidakcocokan antara jumlah aktual jumlah perangkat neuron dalam jenis instance tertentu dan jumlah yang dikembalikan oleh
neuron-ls, maka HMA me-reboot node
Pemeriksaan di atas bersifat pasif, pemeriksaan kesehatan latar belakang HyperPod berjalan terus menerus di node Anda. Selain pemeriksaan ini, HyperPod juga menjalankan pemeriksaan kesehatan mendalam (atau aktif) selama pembuatan dan pembaruan HyperPod cluster. Pelajari lebih lanjut tentang pemeriksaan kesehatan mendalam.
Deteksi Kesalahan
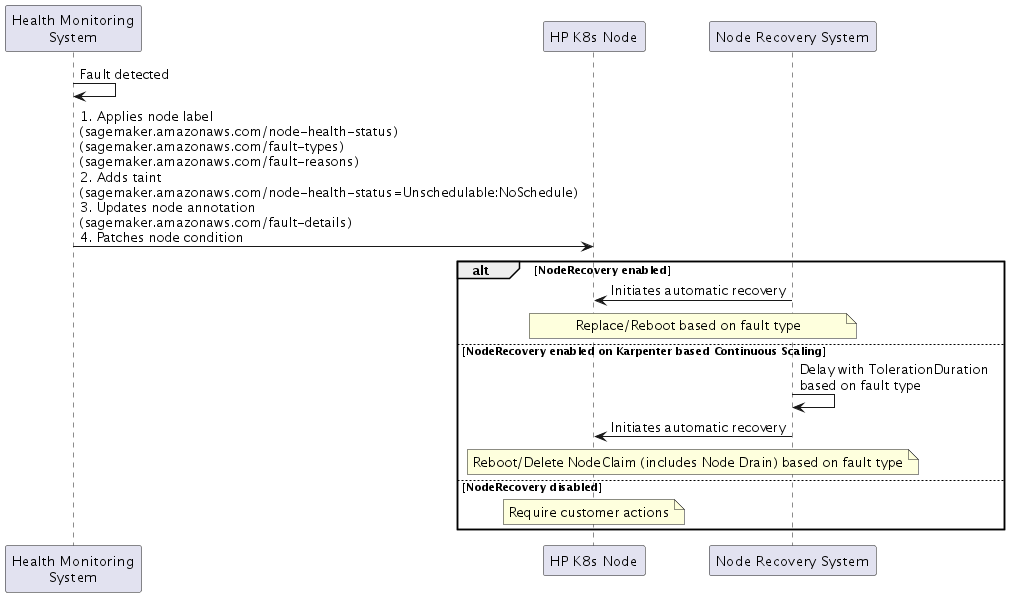
Ketika SageMaker HyperPod mendeteksi kesalahan, itu mengimplementasikan respons empat bagian:
-
Label Node
-
Status Kesehatan:
sagemaker.amazonaws.com/node-health-status -
Jenis Kesalahan:
sagemaker.amazonaws.com/fault-typeslabel untuk kategorisasi tingkat tinggi -
Alasan Kesalahan:
sagemaker.amazonaws.com/fault-reasonslabel untuk informasi kesalahan rinci
-
-
Noda Node
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
Anotasi Node
-
Detail kesalahan:
sagemaker.amazonaws.com/fault-details -
Merekam hingga 20 kesalahan dengan stempel waktu yang terjadi pada node
-
-
Kondisi Node (Kondisi Node Kubernetes)
-
Mencerminkan status kesehatan saat ini dalam kondisi simpul:
-
Jenis: Sama seperti jenis kesalahan
-
Status:
True -
Alasan: Sama seperti alasan kesalahan
-
LastTransitionTime: Waktu terjadinya kesalahan
-
-
Log yang dihasilkan oleh agen SageMaker HyperPod pemantauan kesehatan
Agen SageMaker HyperPod pemantauan kesehatan adalah fitur pemeriksaan kesehatan out-of-the-box dan terus berjalan di semua cluster. HyperPod Agen pemantauan kesehatan menerbitkan peristiwa kesehatan yang terdeteksi pada instans GPU atau Trn ke dalam grup log CloudWatch Cluster. /aws/sagemaker/Clusters/
Log deteksi dari agen pemantauan HyperPod kesehatan dibuat sebagai aliran log terpisah yang dinamai SagemakerHealthMonitoringAgent untuk setiap node. Anda dapat menanyakan log deteksi menggunakan wawasan CloudWatch log sebagai berikut.
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
Ini harus mengembalikan output yang mirip dengan yang berikut ini.
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}
