Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
In-process pemulihan dan pelatihan tanpa pemeriksaan
HyperPod pelatihan checkpointless menggunakan redundansi model untuk memungkinkan pelatihan toleran kesalahan. Prinsip intinya adalah bahwa status model dan pengoptimal sepenuhnya direplikasi di beberapa grup node, dengan pembaruan bobot dan perubahan status pengoptimal direplikasi secara sinkron dalam setiap grup. Ketika kegagalan terjadi, replika yang sehat menyelesaikan langkah pengoptimalnya dan mengirimkan model/optimizer status yang diperbarui ke replika pemulihan.
Pendekatan berbasis redundansi model ini memungkinkan beberapa mekanisme penanganan kesalahan:
-
In-process pemulihan: proses tetap aktif meskipun ada kesalahan, menjaga semua status model dan pengoptimal dalam memori GPU dengan nilai terbaru
-
Penanganan aborsi yang anggun: pengguguran terkontrol dan pembersihan sumber daya untuk operasi yang terpengaruh
-
Eksekusi ulang blok kode: menjalankan kembali hanya segmen kode yang terpengaruh dalam Blok Re-executable Kode (RCB)
-
Pemulihan tanpa pos pemeriksaan tanpa kemajuan pelatihan yang hilang: karena proses tetap ada dan status tetap dalam memori, tidak ada kemajuan pelatihan yang hilang; ketika kesalahan terjadi pelatihan dilanjutkan dari langkah sebelumnya, sebagai lawan dari melanjutkan dari pos pemeriksaan terakhir yang disimpan
Konfigurasi Checkpointless
Berikut adalah cuplikan inti dari pelatihan checkpointless.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: Semua peringkat akan menunggu informasi peringkat dari HyperpodTrainingOperator infrastruktur.HPWrapper: Pembungkus fungsi Python yang memungkinkan kemampuan restart untuk Blok Re-executable Kode (RCB). Implementasinya menggunakan manajer konteks daripada dekorator Python karena dekorator tidak dapat menentukan jumlah RCB yang akan dipantau saat runtime.CudaHealthCheck: Memastikan konteks CUDA untuk proses saat ini dalam keadaan sehat dengan menyinkronkan dengan GPU. Menggunakan perangkat yang ditentukan oleh variabel lingkungan LOCAL_RANK, atau default ke perangkat CUDA thread utama jika LOCAL_RANK tidak disetel.HPAgentK8sAPIFactory: API ini memungkinkan pelatihan checkpointless untuk menanyakan status pelatihan pod lain di klaster pelatihan Kubernetes. Ini juga menyediakan penghalang tingkat infrastruktur yang memastikan semua peringkat berhasil menyelesaikan aborsi dan memulai kembali operasi sebelum melanjutkan.CheckpointManager: Mengelola pos pemeriksaan dalam memori dan pemulihan peer-to-peer untuk toleransi kesalahan tanpa pemeriksaan. Ini memiliki tanggung jawab inti berikut:In-Memory Checkpoint Management: Menyimpan dan mengelola pos pemeriksaan NeMo model dalam memori untuk pemulihan cepat tanpa disk I/O selama skenario pemulihan checkpointless.
Validasi Kelayakan Pemulihan: Menentukan apakah pemulihan tanpa pemeriksaan dimungkinkan dengan memvalidasi konsistensi langkah global, kesehatan peringkat, dan integritas status model.
Peer-to-Peer Orkestrasi Pemulihan: Mengkoordinasikan transfer pos pemeriksaan antara peringkat sehat dan gagal menggunakan komunikasi terdistribusi untuk pemulihan cepat.
Manajemen Negara RNG: Mempertahankan dan mengembalikan status generator angka acak di seluruh Python,, NumPy PyTorch, dan Megatron untuk pemulihan deterministik.
[Opsional] Checkpoint Offload: Bongkar pos pemeriksaan memori ke CPU jika GPU tidak memiliki kapasitas memori yang cukup.
PEFTCheckpointManager: Ini meluasCheckpointManagerdengan menjaga bobot model dasar untuk finetuning PEFT.CheckpointlessAbortManager: Mengelola operasi abort di utas latar belakang saat terjadi kesalahan. Secara default, itu dibatalkan, Checkpointing TransformerEngine,, TorchDistributed dan. DataLoader Pengguna dapat mendaftarkan penangan abort khusus sesuai kebutuhan. Setelah pembatalan selesai, semua komunikasi harus dihentikan dan semua proses dan utas harus dihentikan untuk mencegah kebocoran sumber daya.CheckpointlessFinalizeCleanup: Menangani operasi pembersihan akhir di utas utama untuk komponen yang tidak dapat dibatalkan atau dibersihkan dengan aman di utas latar belakang.CheckpointlessMegatronStrategy: Ini mewarisi dariMegatronStrategydari di Nemo. Perhatikan bahwa pelatihan tanpa pemeriksaan membutuhkannum_distributed_optimizer_instancesminimal 2 sehingga akan ada replikasi pengoptimal. Strategi ini juga menangani pendaftaran atribut penting dan inisialisasi grup proses, misalnya, tanpa akar.CheckpointlessCallback: Panggilan balik kilat yang mengintegrasikan NeMo pelatihan dengan sistem toleransi kesalahan pelatihan tanpa pemeriksaan. Ini memiliki tanggung jawab inti berikut:Manajemen Siklus Hidup Langkah Pelatihan: Melacak kemajuan pelatihan dan berkoordinasi dengan ParameterUpdateLock pemulihan enable/disable tanpa pemeriksaan berdasarkan status pelatihan (langkah pertama vs langkah selanjutnya).
Koordinasi Status Pos Pemeriksaan: Mengelola pos pemeriksaan model dasar PEFT dalam memori. saving/restoring
CheckpointlessCompatibleConnector: PTLCheckpointConnectoryang mencoba memuat file pos pemeriksaan ke memori, dengan jalur sumber ditentukan dalam prioritas ini:coba pemulihan tanpa pemeriksaan
jika checkpointless mengembalikan None, mundur ke parent.resume_start ()
Lihat contoh
Konsep
Bagian ini memperkenalkan konsep pelatihan tanpa pemeriksaan. Pelatihan tanpa pos pemeriksaan di Amazon SageMaker HyperPod mendukung pemulihan dalam proses. Antarmuka API ini mengikuti format yang mirip dengan API NVRx.
Konsep - Blok Re-Executable Kode (RCB)
Ketika kegagalan terjadi, proses yang sehat tetap hidup, tetapi sebagian dari kode harus dieksekusi ulang untuk memulihkan status pelatihan dan tumpukan python. Blok Re-executable Kode (RCB) adalah segmen kode tertentu yang berjalan kembali selama pemulihan kegagalan. Dalam contoh berikut, RCB mencakup seluruh skrip pelatihan (yaitu, semua yang ada di bawah main ()), yang berarti bahwa setiap pemulihan kegagalan memulai ulang skrip pelatihan sambil mempertahankan model dalam memori dan status pengoptimal.
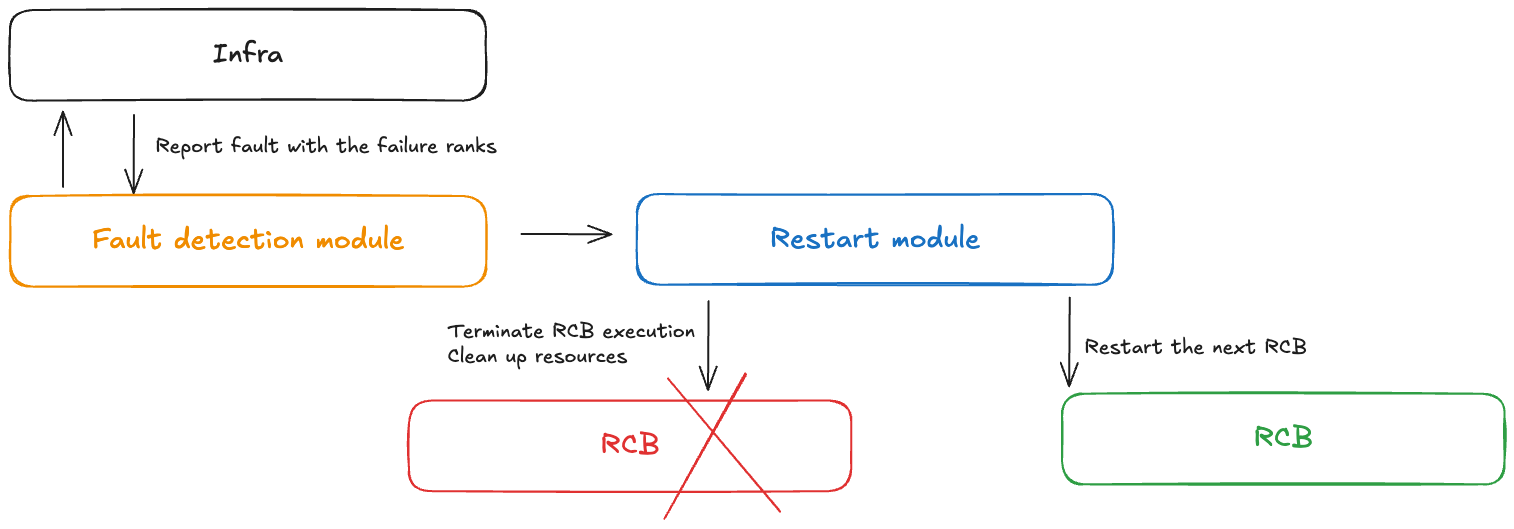
Konsep - Kontrol kesalahan
Modul pengontrol kesalahan menerima pemberitahuan ketika kegagalan terjadi selama pelatihan tanpa pemeriksaan. Pengontrol kesalahan ini mencakup komponen-komponen berikut:
Modul deteksi kesalahan: Menerima pemberitahuan kesalahan infrastruktur
API definisi RCB: Memungkinkan pengguna untuk menentukan blok kode yang dapat dieksekusi ulang (RCB) dalam kode mereka
Restart modul: Mengakhiri RCB, membersihkan sumber daya, dan memulai ulang RCB
Konsep - Redundansi model
Pelatihan model besar biasanya membutuhkan ukuran paralel data yang cukup besar untuk melatih model secara efisien. Dalam paralelisme data tradisional seperti PyTorch DDP dan Horovod, model ini sepenuhnya direplikasi. Teknik paralelisme data sharded yang lebih canggih seperti DeepSpeed Zero optimizer dan FSDP juga mendukung mode sharding hybrid, yang memungkinkan sharding model/optimizer status dalam grup sharding dan sepenuhnya mereplikasi di seluruh grup replikasi. NeMo juga memiliki fitur sharding hybrid ini melalui argumen num_distributed_optimizer_instances, yang memungkinkan redundansi.
Namun, menambahkan redundansi menunjukkan bahwa model tidak akan sepenuhnya dibagi di seluruh cluster, menghasilkan penggunaan memori perangkat yang lebih tinggi. Jumlah memori redundan akan bervariasi tergantung pada teknik sharding model spesifik yang diterapkan oleh pengguna. Bobot model presisi rendah, gradien, dan memori aktivasi tidak akan terpengaruh, karena mereka dipecah melalui paralelisme model. Model master presisi tinggi weights/gradients dan status pengoptimal akan terpengaruh. Menambahkan satu replika model redundan meningkatkan penggunaan memori perangkat kira-kira setara dengan satu ukuran pos pemeriksaan DCP.
Sharding hibrida memecah kolektif di seluruh kelompok DP menjadi kolektif yang relatif lebih kecil. Sebelumnya ada reduce-scatter dan all-gathering di seluruh kelompok DP. Setelah sharding hybrid, reduce-scatter hanya berjalan di dalam setiap replika model, dan akan ada all-reduce di seluruh grup replika model. All-gathering juga berjalan di dalam setiap replika model. Akibatnya, seluruh volume komunikasi secara kasar tetap tidak berubah, tetapi kolektif berjalan dengan kelompok yang lebih kecil, jadi kami mengharapkan latensi yang lebih baik.
Konsep - Jenis Kegagalan dan Mulai Ulang
Tabel berikut mencatat berbagai jenis kegagalan dan mekanisme pemulihan terkait. Pelatihan tanpa pemeriksaan pertama kali mencoba pemulihan kegagalan melalui pemulihan dalam proses, diikuti dengan restart tingkat proses. Ini kembali ke restart tingkat pekerjaan hanya jika terjadi kegagalan besar (misalnya, beberapa node gagal pada saat yang sama).
| Jenis Kegagalan | Penyebab | Jenis Pemulihan | Mekanisme Pemulihan |
|---|---|---|---|
| In-process kegagalan | Code-level kesalahan, pengecualian | In-Process Pemulihan (IPR) | Jalankan kembali RCB dalam proses yang ada; proses sehat tetap aktif |
| Kegagalan proses restart | Konteks CUDA yang rusak, proses yang dihentikan | Tingkat Proses Mulai Ulang (PLR) | SageMaker HyperPod operator pelatihan memulai ulang proses; melewatkan restart pod K8s |
| Kegagalan penggantian simpul | Kegagalan node/GPU perangkat keras permanen | Tingkat Pekerjaan Mulai Ulang (JLR) | Ganti node yang gagal; restart seluruh pekerjaan pelatihan |
Konsep - Perlindungan kunci atom untuk langkah pengoptimal
Eksekusi model dibagi menjadi tiga fase: propagasi maju, propagasi mundur, dan langkah pengoptimal. Perilaku pemulihan bervariasi berdasarkan waktu kegagalan:
Forward/backward propagasi: Putar kembali ke awal langkah pelatihan saat ini dan siarkan status model ke node pengganti
Langkah pengoptimal: Izinkan replika sehat untuk menyelesaikan langkah di bawah perlindungan kunci, lalu siarkan status model yang diperbarui ke node pengganti
Strategi ini memastikan pembaruan pengoptimal yang telah selesai tidak pernah dibuang, membantu mengurangi waktu pemulihan kesalahan.
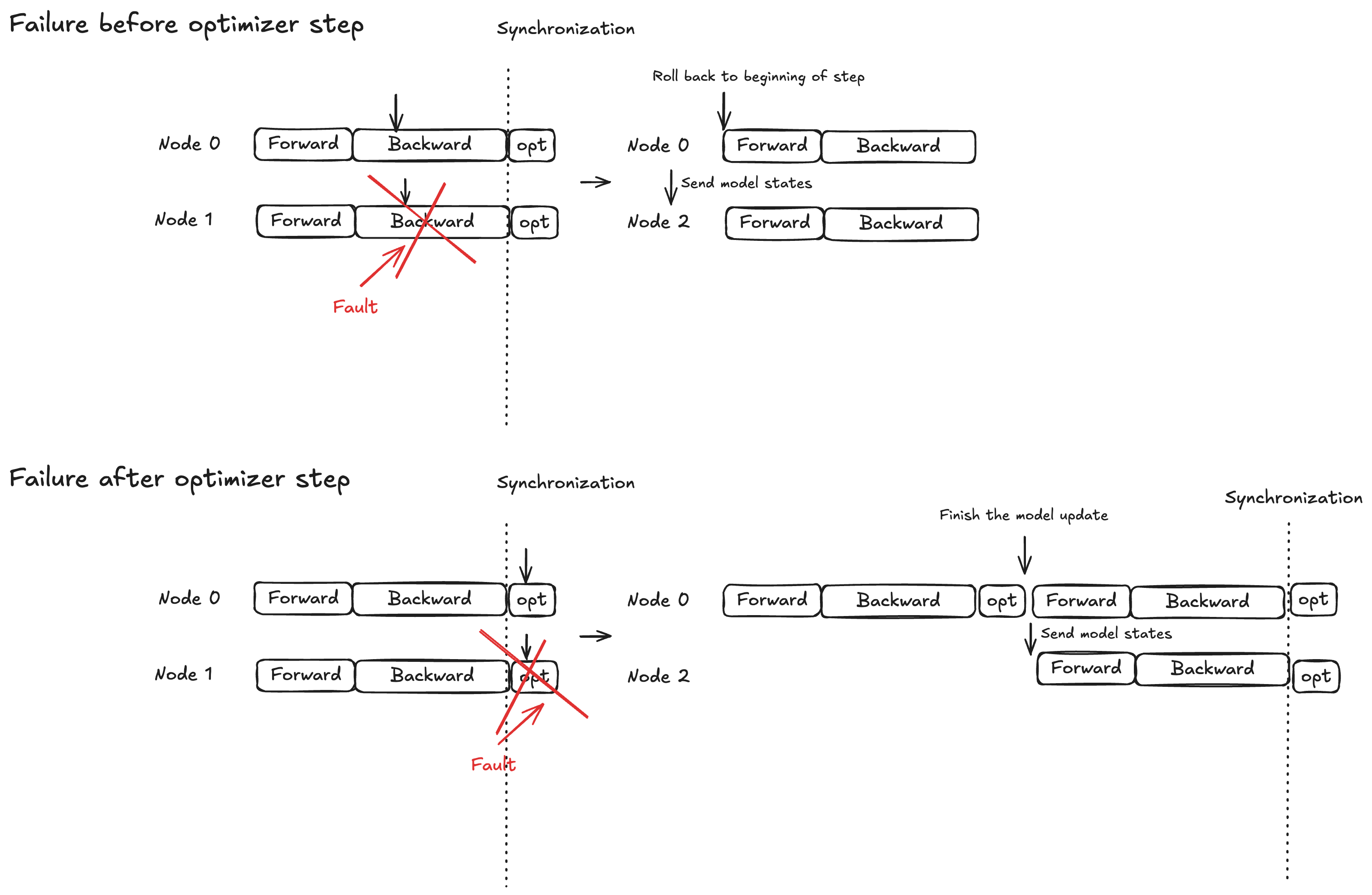
Diagram Alur Pelatihan Tanpa Pemeriksaan
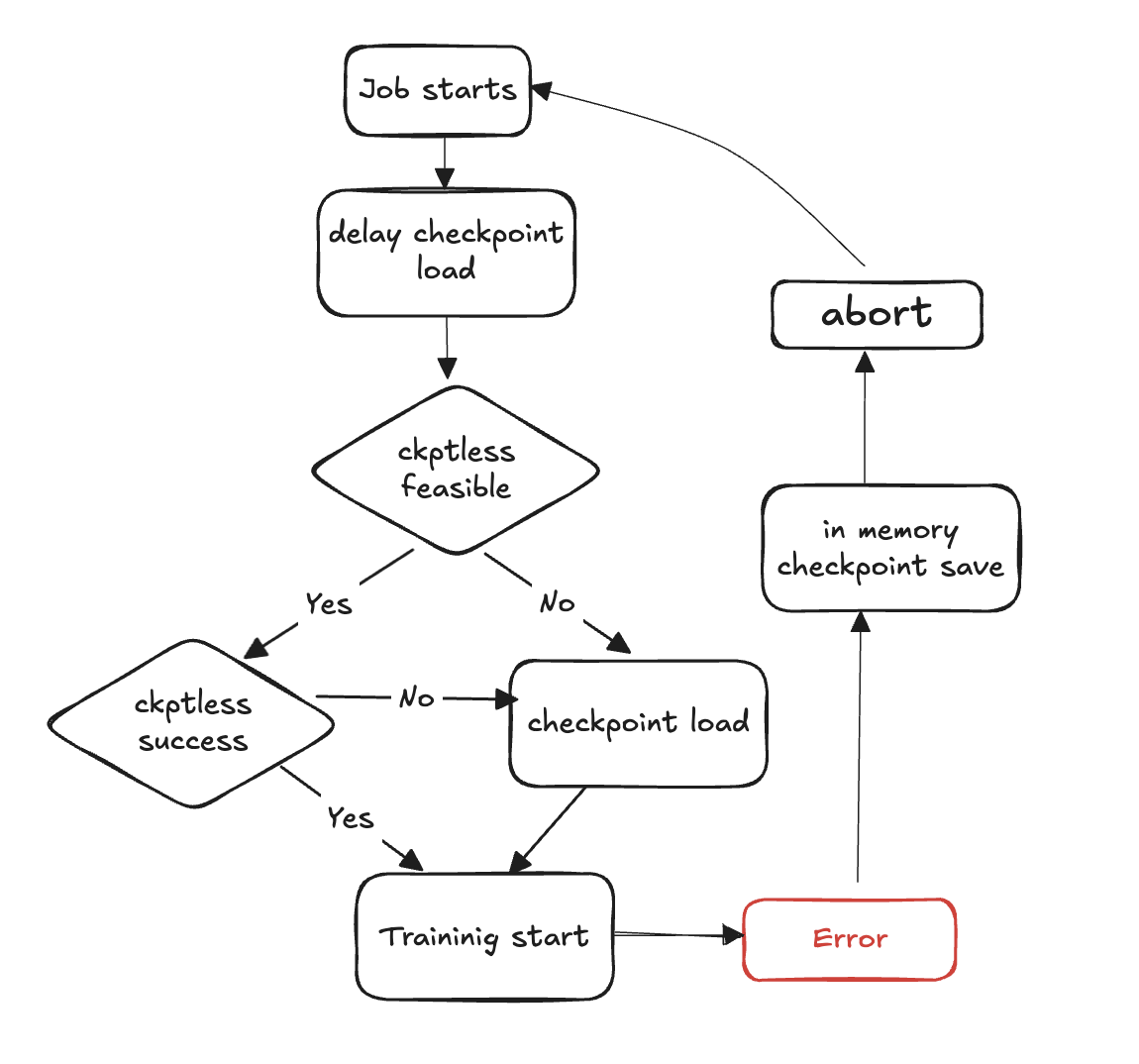
Langkah-langkah berikut menguraikan deteksi kegagalan dan proses pemulihan tanpa pemeriksaan:
Loop pelatihan dimulai
Kesalahan terjadi
Evaluasi kelayakan resume checkpointless
Periksa apakah layak untuk melakukan resume tanpa pemeriksaan
Jika memungkinkan, Coba checkpointless reusme
Jika resume gagal, mundur ke pemuatan pos pemeriksaan dari penyimpanan
Jika resume berhasil, pelatihan berlanjut dari keadaan pulih
Jika tidak memungkinkan, kembalilah ke pos pemeriksaan pemuatan dari penyimpanan
Bersihkan sumber daya - batalkan semua grup proses dan backend dan sumber daya gratis sebagai persiapan untuk memulai ulang.
Lanjutkan loop pelatihan - loop pelatihan baru dimulai, dan proses kembali ke langkah 1.
Referensi API
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
Menunggu dan mengambil informasi peringkat dari HyperPod, kemudian memperbarui lingkungan proses saat ini dengan variabel pelatihan terdistribusi.
Fungsi ini memperoleh penugasan peringkat dan variabel lingkungan yang benar untuk pelatihan terdistribusi. Ini memastikan bahwa setiap proses mendapatkan konfigurasi yang sesuai untuk perannya dalam pekerjaan pelatihan terdistribusi.
Parameter
Tidak ada
Pengembalian
Tidak ada
Perilaku
Pemeriksaan Proses: Melewatkan eksekusi jika dipanggil dari subproses (hanya berjalan di) MainProcess
Pengambilan Lingkungan: Mendapat variabel arus
RANKdanWORLD_SIZEdari lingkunganHyperPod Komunikasi: Panggilan
hyperpod_wait_rank_info()untuk mengambil informasi peringkat dari HyperPodPembaruan Lingkungan: Memperbarui lingkungan proses saat ini dengan variabel lingkungan khusus pekerja yang diterima dari HyperPod
Variabel Lingkungan
Fungsi membaca variabel lingkungan berikut:
RANK (int) - Peringkat proses saat ini (default: -1 jika tidak disetel)
WORLD_SIZE (int) - Jumlah total proses dalam pekerjaan terdistribusi (default: 0 jika tidak disetel)
Menaikkan
AssertionError— Jika respons dari HyperPod tidak dalam format yang diharapkan atau jika bidang yang diperlukan tidak ada
Contoh
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Catatan
Hanya mengeksekusi dalam proses utama; panggilan subproses secara otomatis dilewati
Fungsi memblokir sampai HyperPod memberikan informasi peringkat
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Pembungkus fungsi Python yang memungkinkan kemampuan restart untuk Blok Re-executable Kode (RCB) dalam pelatihan tanpa pemeriksaan. HyperPod
Pembungkus ini memberikan toleransi kesalahan dan kemampuan pemulihan otomatis dengan memantau eksekusi pelatihan dan mengoordinasikan restart di seluruh proses terdistribusi ketika terjadi kegagalan. Ini menggunakan pendekatan manajer konteks daripada dekorator untuk mempertahankan sumber daya global sepanjang siklus hidup pelatihan.
Parameter
batalkan (Batalkan, opsional) — Menggugurkan eksekusi secara asinkron saat kegagalan terdeteksi. Default:
Compose(HPAbortTorchDistributed())finalize (Finalize, optional) — Rank-local finalisasi handler dieksekusi saat restart. Default:
Nonehealth_check (HealthCheck, opsional) - pemeriksaan Rank-local kesehatan dijalankan saat restart. Default:
Nonehp_api_factory (Dapat dipanggil, opsional) - Fungsi pabrik untuk membuat API untuk berinteraksi. HyperPod HyperPod Default:
Noneabort_timeout (float, opsional) - Batas waktu untuk membatalkan panggilan di thread pengendali kesalahan. Default:
Nonediaktifkan (bool, opsional) - Mengaktifkan fungsionalitas pembungkus. Kapan
False, pembungkus menjadi pass-through. Default:Truetrace_file_path (str, opsional) - Jalur ke file jejak untuk pembuatan profil. VizTracer Default:
Noneasync_raise_before_abort (bool, opsional) - Aktifkan kenaikan sebelum membatalkan di utas pengendali kesalahan. Default:
Trueearly_abort_communicator (bool, opsional) - Batalkan komunikator () sebelum membatalkan dataloader. NCCL/Gloo Default:
Falsecheckpoint_manager (Apa saja, opsional) - Manajer untuk menangani pos pemeriksaan selama pemulihan. Default:
Nonecheck_memory_status (bool, opsional) - Aktifkan pemeriksaan status memori dan logging. Default:
True
Metode
def __call__(self, fn)
Membungkus fungsi untuk mengaktifkan kemampuan restart.
Parameter:
fn (Callable) - Fungsi untuk membungkus dengan kemampuan restart
Pengembalian:
Callable - Fungsi dibungkus dengan kemampuan restart, atau fungsi asli jika dinonaktifkan
Contoh
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Catatan
Pembungkus
torch.distributedharus tersediaKapan
enabled=False, pembungkus menjadi pass-through dan mengembalikan fungsi asli tidak berubahPembungkus memelihara sumber daya global seperti memantau utas di seluruh siklus hidup pelatihan
Mendukung VizTracer pembuatan profil saat
trace_file_pathdisediakanTerintegrasi dengan HyperPod untuk penanganan kesalahan terkoordinasi di seluruh pelatihan terdistribusi
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
Memantau dan mengelola status Restart Code Block (RCB) selama eksekusi.
Kelas ini menangani siklus hidup eksekusi RCB, termasuk deteksi kegagalan, koordinasi dengan peringkat lain untuk memulai ulang, dan operasi pembersihan. Ini mengelola sinkronisasi terdistribusi dan memastikan pemulihan yang konsisten di semua proses pelatihan.
Parameter
wrapper (HPWrapper) - Pembungkus induk yang berisi pengaturan pemulihan dalam proses global
Atribut
step_upon_restart (int) - Penghitung yang melacak langkah-langkah sejak restart terakhir, digunakan untuk menentukan strategi restart
Metode
def initialize_barrier()
Tunggu sinkronisasi HyperPod penghalang setelah menemukan pengecualian dari RCB.
def start_hp_fault_handling_thread()
Mulai utas penanganan kesalahan untuk memantau dan mengoordinasikan kegagalan.
def handle_fn_exception(call_ex)
Proses pengecualian dari fungsi eksekusi atau RCB.
Parameter:
call_ex (Exception) - Pengecualian dari fungsi pemantauan
def restart(term_ex)
Jalankan restart handler termasuk finalisasi, pengumpulan sampah, dan pemeriksaan kesehatan.
Parameter:
term_ex (RankShouldRestart) - Pengecualian penghentian memicu restart
def launch(fn, *a, **kw)
Jalankan RCB dengan penanganan pengecualian yang tepat.
Parameter:
fn (Callable) - Fungsi yang akan dieksekusi
a - Argumen fungsi
kw — Argumen kata kunci fungsi
def run(fn, a, kw)
Loop eksekusi utama yang menangani restart dan sinkronisasi penghalang.
Parameter:
fn (Callable) - Fungsi yang akan dieksekusi
a - Argumen fungsi
kw — Argumen kata kunci fungsi
def shutdown()
Shutdown penanganan kesalahan dan pemantauan thread.
Catatan
Secara otomatis menangani
RankShouldRestartpengecualian untuk pemulihan terkoordinasiMengelola pelacakan dan membatalkan memori, pengumpulan sampah selama restart
Mendukung strategi pemulihan dalam proses dan PLR (Process-Level Restart) berdasarkan waktu kegagalan
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
Memastikan bahwa konteks CUDA untuk proses saat ini dalam keadaan sehat selama pemulihan pelatihan tanpa pemeriksaan.
Pemeriksaan kesehatan ini disinkronkan dengan GPU untuk memverifikasi bahwa konteks CUDA tidak rusak setelah kegagalan pelatihan. Ini melakukan operasi sinkronisasi GPU untuk mendeteksi masalah apa pun yang mungkin mencegah dimulainya kembali pelatihan yang berhasil. Pemeriksaan kesehatan dilakukan setelah kelompok yang didistribusikan dihancurkan dan finalisasi selesai.
Parameter
batas waktu (datetime.timedelta, opsional) - Durasi batas waktu untuk operasi sinkronisasi GPU. Default:
datetime.timedelta(seconds=30)
Metode
__call__(state, train_ex=None)
Jalankan pemeriksaan kesehatan CUDA untuk memverifikasi integritas konteks GPU.
Parameter:
state (HPState) - Status saat ini HyperPod yang berisi peringkat dan informasi terdistribusi
train_ex (Pengecualian, opsional) - Pengecualian pelatihan asli yang memicu restart. Default:
None
Pengembalian:
Tupel — Tupel yang mengandung
(state, train_ex)tidak berubah jika pemeriksaan kesehatan berlalu
Meningkatkan:
TimeoutError— Jika waktu sinkronisasi GPU habis, menunjukkan konteks CUDA yang berpotensi rusak
Pelestarian Negara: Mengembalikan status asli dan pengecualian tidak berubah jika semua pemeriksaan lulus
Contoh
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Catatan
Menggunakan threading untuk menerapkan perlindungan batas waktu untuk sinkronisasi GPU
Dirancang untuk mendeteksi konteks CUDA yang rusak yang dapat mencegah dimulainya kembali pelatihan yang berhasil
Harus digunakan sebagai bagian dari pipa toleransi kesalahan dalam skenario pelatihan terdistribusi
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
Kelas pabrik untuk membuat instance HPAGentK8sapi yang berkomunikasi dengan HyperPod infrastruktur untuk koordinasi pelatihan terdistribusi.
Pabrik ini menyediakan cara standar untuk membuat dan mengkonfigurasi objek HPAGentK8SAPI yang menangani komunikasi antara proses pelatihan dan bidang kontrol. HyperPod Ini merangkum pembuatan klien soket yang mendasari dan instance API, memastikan konfigurasi yang konsisten di berbagai bagian sistem pelatihan.
Metode
__call__()
Buat dan kembalikan instance HPAGentK8SAPI yang dikonfigurasi untuk komunikasi. HyperPod
Pengembalian:
HPAGentK8SAPI — Instans API yang dikonfigurasi untuk berkomunikasi dengan infrastruktur HyperPod
Contoh
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Catatan
Dirancang untuk bekerja secara mulus dengan HyperPod Kubernetes-based infrastruktur. Hal ini penting untuk penanganan kesalahan terkoordinasi dan pemulihan dalam skenario pelatihan terdistribusi
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
Mengelola pos pemeriksaan dalam memori dan pemulihan peer-to-peer untuk toleransi kesalahan tanpa pemeriksaan dalam pelatihan terdistribusi.
Kelas ini menyediakan fungsionalitas inti untuk pelatihan HyperPod tanpa pemeriksaan dengan mengelola pos pemeriksaan NeMo model dalam memori, memvalidasi kelayakan pemulihan, dan mengatur transfer pos pemeriksaan peer-to-peer antara peringkat sehat dan gagal. Ini menghilangkan kebutuhan akan disk I/O selama pemulihan, secara signifikan mengurangi waktu rata-rata untuk pemulihan (MTTR).
Parameter
enable_checksum (bool, opsional) - Aktifkan validasi checksum status model untuk pemeriksaan integritas selama pemulihan. Default:
Falseenable_offload (bool, opsional) - Aktifkan pembongkaran pos pemeriksaan dari GPU ke memori CPU untuk mengurangi penggunaan memori GPU. Default:
False
Atribut
global_step (int atau None) - Langkah pelatihan saat ini terkait dengan pos pemeriksaan yang disimpan
rng_states (daftar atau Tidak Ada) - Status generator nomor acak yang disimpan untuk pemulihan deterministik
checksum_manager (MemoryChecksumManager) - Manajer untuk validasi checksum status model
parameter_update_lock (ParameterUpdateLock) - Kunci untuk mengoordinasikan pembaruan parameter selama pemulihan
Metode
save_checkpoint(trainer)
Simpan pos pemeriksaan NeMo model dalam memori untuk potensi pemulihan tanpa pos pemeriksaan.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Catatan:
Dipanggil oleh CheckpointlessCallback pada akhir batch atau selama penanganan pengecualian
Menciptakan titik pemulihan tanpa I/O overhead disk
Menyimpan status model, pengoptimal, dan penjadwal lengkap
delete_checkpoint()
Hapus pos pemeriksaan dalam memori dan lakukan operasi pembersihan.
Catatan:
Menghapus data pos pemeriksaan, status RNG, dan tensor yang di-cache
Melakukan pengumpulan sampah dan pembersihan cache CUDA
Dipanggil setelah pemulihan berhasil atau ketika pos pemeriksaan tidak lagi diperlukan
try_checkpointless_load(trainer)
Mencoba pemulihan checkpointless dengan memuat status dari peringkat rekan.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Pengembalian:
dict atau None - Pos pemeriksaan yang dipulihkan jika berhasil, Tidak ada jika mundur ke disk diperlukan
Catatan:
Titik masuk utama untuk pemulihan tanpa pemeriksaan
Memvalidasi kelayakan pemulihan sebelum mencoba transfer P2P
Selalu membersihkan pos pemeriksaan dalam memori setelah upaya pemulihan
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
Tentukan apakah pemulihan tanpa pemeriksaan dimungkinkan untuk skenario kegagalan saat ini.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
include_checksum_verification (bool, opsional) - Apakah akan menyertakan validasi checksum. Default:
True
Pengembalian:
bool - Benar jika pemulihan checkpointless layak, False sebaliknya
Kriteria Validasi:
Konsistensi langkah global di seluruh jajaran sehat
Replika sehat yang cukup tersedia untuk pemulihan
Integritas checksum status model (jika diaktifkan)
store_rng_states()
Simpan semua status generator angka acak untuk pemulihan deterministik.
Catatan:
Menangkap status Python NumPy,, PyTorch CPU/GPU, dan Megatron RNG
Penting untuk mempertahankan determinisme pelatihan setelah pemulihan
load_rng_states()
Kembalikan semua status RNG untuk kelanjutan pemulihan deterministik.
Catatan:
Mengembalikan semua status RNG yang disimpan sebelumnya
Memastikan pelatihan berlanjut dengan urutan acak yang identik
maybe_offload_checkpoint()
Bongkar pos pemeriksaan dari GPU ke memori CPU jika offload diaktifkan.
Catatan:
Mengurangi penggunaan memori GPU untuk model besar
Hanya mengeksekusi jika
enable_offload=TrueMempertahankan aksesibilitas pos pemeriksaan untuk pemulihan
Contoh
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
Validasi: Memverifikasi integritas pos pemeriksaan menggunakan checksum (jika diaktifkan)
Catatan
Menggunakan primitif komunikasi terdistribusi untuk transfer P2P yang efisien
Secara otomatis menangani konversi tensor dtype dan penempatan perangkat
MemoryChecksumManager— Menangani validasi integritas status model
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
Mengelola pos pemeriksaan untuk PEFT (Parameter-Efficient Fine-Tuning) dengan penanganan basis dan adaptor terpisah untuk pemulihan checkpointless yang dioptimalkan.
Manajer pos pemeriksaan khusus ini memperluas CheckpointManager untuk mengoptimalkan alur kerja PEFT dengan memisahkan bobot model dasar dari parameter adaptor.
Parameter
Mewarisi semua parameter dari CheckpointManager:
enable_checksum (bool, opsional) - Aktifkan validasi checksum status model. Default:
Falseenable_offload (bool, opsional) - Aktifkan pembongkaran pos pemeriksaan ke memori CPU. Default:
False
Atribut Tambahan
params_to_save (set) - Set nama parameter yang harus disimpan sebagai parameter adaptor
base_model_weights (dict atau None) - Bobot model dasar cache, disimpan sekali dan digunakan kembali
base_model_keys_to_extract (list atau None) - Kunci untuk mengekstrak tensor model dasar selama transfer P2P
Metode
maybe_save_base_model(trainer)
Simpan bobot model dasar sekali, saring parameter adaptor.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Catatan:
Hanya menyimpan bobot model dasar pada panggilan pertama; panggilan berikutnya adalah no-ops
Menyaring parameter adaptor untuk menyimpan hanya bobot model dasar beku
Bobot model dasar dipertahankan di beberapa sesi pelatihan
save_checkpoint(trainer)
Simpan pos pemeriksaan model adaptor NeMo PEFT di memori untuk potensi pemulihan tanpa pos pemeriksaan.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Catatan:
Secara otomatis memanggil
maybe_save_base_model()jika model dasar belum disimpanFilter pos pemeriksaan untuk menyertakan hanya parameter adaptor dan status pelatihan
Secara signifikan mengurangi ukuran pos pemeriksaan dibandingkan dengan pos pemeriksaan model penuh
try_base_model_checkpointless_load(trainer)
Mencoba pemulihan tanpa pemeriksaan bobot model dasar PEFT dengan memuat status dari peringkat sejawat.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Pengembalian:
dict atau None - Pos pemeriksaan model dasar yang dipulihkan jika berhasil, Tidak ada jika fallback diperlukan
Catatan:
Digunakan selama inisialisasi model untuk memulihkan bobot model dasar
Tidak membersihkan bobot model dasar setelah pemulihan (diawetkan untuk digunakan kembali)
Dioptimalkan untuk skenario pemulihan model-bobot saja
try_checkpointless_load(trainer)
Mencoba pemberat adaptor PEFT checkpointless recovery dengan memuat status dari peringkat rekan.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Pengembalian:
dict atau None - Pos pemeriksaan adaptor yang dipulihkan jika berhasil, Tidak ada jika fallback diperlukan
Catatan:
Memulihkan hanya parameter adaptor, status pengoptimal, dan penjadwal
Secara otomatis memuat status pengoptimal dan penjadwal setelah pemulihan berhasil
Membersihkan pos pemeriksaan adaptor setelah upaya pemulihan
is_adapter_key(key)
Periksa apakah kunci dict status milik parameter adaptor.
Parameter:
kunci (str atau tuple) — Kunci dict negara untuk memeriksa
Pengembalian:
bool - Benar jika kunci adalah parameter adaptor, Salah jika parameter model dasar
Logika Deteksi:
Memeriksa apakah kunci sudah
params_to_savediaturMengidentifikasi kunci yang berisi “.adapter.” substring
Mengidentifikasi kunci yang diakhiri dengan “.adapters”
Untuk tombol Tuple, periksa apakah parameter membutuhkan gradien
maybe_offload_checkpoint()
Bongkar bobot model dasar dari GPU ke memori CPU.
Catatan:
Memperluas metode induk untuk menangani pembongkaran bobot model dasar
Bobot adaptor biasanya kecil dan tidak memerlukan pembongkaran
Menetapkan bendera internal untuk melacak status pembongkaran
Catatan
Dirancang khusus untuk Parameter-Efficient Fine-Tuning skenario (LoRa, Adaptor, dll.)
Secara otomatis menangani pemisahan model dasar dan parameter adaptor
Contoh
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
Kelas pabrik untuk membuat dan mengelola komposisi komponen abort untuk toleransi kesalahan tanpa pemeriksaan.
Kelas utilitas ini menyediakan metode statis untuk membuat, menyesuaikan, dan mengelola komposisi komponen abort yang digunakan selama penanganan kesalahan dalam pelatihan HyperPod checkpointless. Ini menyederhanakan konfigurasi urutan abort yang menangani pembersihan komponen pelatihan terdistribusi, pemuat data, dan sumber daya khusus kerangka kerja selama pemulihan kegagalan.
Parameter
Tidak ada (semua metode statis)
Metode Statis
get_default_checkpointless_abort()
Dapatkan instance compose abort default yang berisi semua komponen abort standar.
Pengembalian:
Compose - Instance abort tersusun default dengan semua komponen abort
Komponen Default:
AbortTransformerEngine() — Membersihkan sumber daya TransformerEngine
HPCheckpointingAbort() — Menangani pembersihan sistem checkpointing
HPAbortTorchDistributed() — Menghentikan operasi PyTorch terdistribusi
HPDataLoaderAbort() - Menghentikan dan membersihkan pemuat data
create_custom_abort(abort_instances)
Buat penulisan abort khusus hanya dengan instance abort yang ditentukan.
Parameter:
abort_instances (Abort) — Jumlah variabel instance abort yang akan disertakan dalam penulisan
Pengembalian:
Compose - Instance abort tersusun baru yang hanya berisi komponen tertentu
Meningkatkan:
ValueError— Jika tidak ada instance abort yang disediakan
override_abort(abort_compose, abort_type, new_abort)
Ganti komponen abort tertentu dalam instance Compose dengan komponen baru.
Parameter:
abort_compose (Compose) — Instance Compose asli untuk dimodifikasi
abort_type (type) — Jenis komponen abort yang akan diganti (misalnya,)
HPCheckpointingAbortnew_abort (Abort) - Instance abort baru untuk digunakan sebagai pengganti
Pengembalian:
Compose — Instance Compose baru dengan komponen yang ditentukan diganti
Meningkatkan:
ValueError— Jika abort_compose tidak memiliki atribut 'instance'
Contoh
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Catatan
Konfigurasi khusus memungkinkan kontrol yang disetel dengan baik atas perilaku pembersihan
Operasi batal sangat penting untuk pembersihan sumber daya yang tepat selama pemulihan kesalahan
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
Melakukan pembersihan menyeluruh setelah deteksi kesalahan untuk mempersiapkan pemulihan dalam proses selama pelatihan tanpa pemeriksaan.
Handler finalisasi ini menjalankan operasi pembersihan khusus kerangka kerja termasuk Megatron/TransformerEngine abort, pembersihan DDP, pemuatan ulang modul, dan pembersihan memori dengan menghancurkan referensi komponen pelatihan. Ini memastikan bahwa lingkungan pelatihan diatur ulang dengan benar untuk pemulihan dalam proses yang berhasil tanpa memerlukan penghentian proses penuh.
Parameter
Tidak ada
Atribut
pelatih (Pytorch_Lightning.trainer atau None) - Referensi ke instance pelatih Lightning PyTorch
Metode
__call__(*a, **kw)
Jalankan operasi pembersihan komprehensif untuk persiapan pemulihan dalam proses.
Parameter:
a — Argumen posisi variabel (diwarisi dari antarmuka Finalize)
kw - Argumen kata kunci variabel (diwarisi dari antarmuka Finalize)
Operasi Pembersihan:
Megatron Framework Cleanup - Panggilan
abort_megatron()untuk membersihkan sumber daya Megatron-specificTransformerEngine Pembersihan - Panggilan
abort_te()untuk membersihkan sumber daya TransformerEngineRope Cleanup - Panggilan
cleanup_rope()untuk membersihkan sumber daya penyematan posisi putarDDP Cleanup — Panggilan
cleanup_ddp()untuk membersihkan sumber daya DistributedDataParallelModul Reloading - Panggilan
reload_megatron_and_te()untuk memuat ulang modul kerangka kerjaLightning Module Cleanup - Secara opsional membersihkan modul Lightning untuk mengurangi memori GPU
Memory Cleanup — Menghancurkan referensi komponen pelatihan ke memori bebas
register_attributes(trainer)
Daftarkan instance pelatih untuk digunakan selama operasi pembersihan.
Parameter:
pelatih (PyTorch_Lightning.trainer) - Contoh pelatih petir untuk mendaftar PyTorch
Integrasi dengan CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Catatan
Operasi pembersihan dijalankan dalam urutan tertentu untuk menghindari masalah ketergantungan
Pembersihan memori menggunakan introspeksi pengumpulan sampah untuk menemukan objek target
Semua operasi pembersihan dirancang agar idempoten dan aman untuk dicoba lagi
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Strategi Megatron dengan kemampuan pemulihan tanpa pemeriksaan terintegrasi untuk pelatihan terdistribusi yang toleran terhadap kesalahan.
Perhatikan bahwa pelatihan tanpa pemeriksaan membutuhkan num_distributed_optimizer_instances minimal 2 sehingga akan ada replikasi pengoptimal. Strategi ini juga menangani pendaftaran atribut penting dan inisialisasi grup proses.
Parameter
Mewarisi semua parameter dari MegatronStrategy:
Parameter NeMo MegatronStrategy inisialisasi standar
Opsi konfigurasi pelatihan terdistribusi
Pengaturan paralelisme model
Atribut
base_store (torch.distributed.tcpstore atau None) - Toko terdistribusi untuk koordinasi kelompok proses
Metode
setup(trainer)
Inisialisasi strategi dan daftarkan komponen toleransi kesalahan dengan pelatih.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Operasi Pengaturan:
Pengaturan Induk - Memanggil MegatronStrategy pengaturan induk
Pendaftaran Injeksi Kesalahan - Mendaftarkan HPFaultInjectionCallback kait jika ada
Selesaikan Pendaftaran — Mendaftarkan pelatih dengan menyelesaikan penangan pembersihan
Batalkan Pendaftaran — Mendaftarkan pelatih dengan penangan batal yang mendukungnya
setup_distributed()
Inisialisasi grup proses menggunakan TCPStore dengan awalan atau koneksi tanpa akar.
load_model_state_dict(checkpoint, strict=True)
Muat dict status model dengan kompatibilitas pemulihan tanpa pemeriksaan.
Parameter:
pos pemeriksaan (Pemetaan [str, Apa Saja]) - Kamus pos pemeriksaan yang berisi status model
strict (bool, opsional) - Apakah akan secara ketat menegakkan pencocokan kunci dict status. Default:
True
get_wrapper()
Dapatkan HPCallWrapper contoh untuk koordinasi toleransi kesalahan.
Pengembalian:
HPCallWrapper— Contoh pembungkus yang dilampirkan ke pelatih untuk toleransi kesalahan
is_peft()
Periksa apakah PEFT (Parameter-Efficient Fine-Tuning) diaktifkan dalam konfigurasi pelatihan dengan memeriksa callback PEFT
Pengembalian:
bool - Benar jika panggilan balik PEFT hadir, False sebaliknya
teardown()
Ganti PyTorch pembongkaran asli Lightning untuk mendelegasikan pembersihan untuk membatalkan penangan.
Contoh
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
Panggilan balik kilat yang mengintegrasikan NeMo pelatihan dengan sistem toleransi kesalahan pelatihan tanpa pemeriksaan.
Callback ini mengelola pelacakan langkah, penyimpanan pos pemeriksaan, dan koordinasi pembaruan parameter untuk kemampuan pemulihan dalam proses. Ini berfungsi sebagai titik integrasi utama antara loop pelatihan PyTorch Lightning dan mekanisme pelatihan HyperPod tanpa pemeriksaan, mengoordinasikan operasi toleransi kesalahan di seluruh siklus hidup pelatihan.
Parameter
enable_inprocess (bool, opsional) - Aktifkan kemampuan pemulihan dalam proses. Default:
Falseenable_checkpointless (bool, opsional) - Aktifkan pemulihan tanpa pemeriksaan (membutuhkan).
enable_inprocess=TrueDefault:Falseenable_checksum (bool, opsional) - Aktifkan validasi checksum status model (membutuhkan).
enable_checkpointless=TrueDefault:Falseclean_tensor_hook (bool, opsional) - Hapus kait tensor dari semua tensor GPU selama pembersihan (operasi mahal). Default:
Falseclean_lightning_module (bool, opsional) - Aktifkan pembersihan modul Lightning untuk membebaskan memori GPU setelah setiap restart. Default:
False
Atribut
tried_adapter_checkpointless (bool) - Tandai untuk melacak apakah pemulihan checkpointless adaptor telah dicoba
Metode
get_wrapper_from_trainer(trainer)
Dapatkan HPCallWrapper contoh dari pelatih untuk koordinasi toleransi kesalahan.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Pengembalian:
HPCallWrapper- Contoh pembungkus untuk operasi toleransi kesalahan
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
Dipanggil di awal setiap batch pelatihan untuk mengelola pelacakan dan pemulihan langkah.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
pl_module (pytorch_lightning. LightningModule) - Modul petir sedang dilatih
batch — Data batch pelatihan saat ini
batch_idx (int) — Indeks dari batch saat ini
args — Argumen posisi tambahan
kwargs - Argumen kata kunci tambahan
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
Lepaskan kunci pembaruan parameter di akhir setiap batch pelatihan.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
pl_module (pytorch_lightning. LightningModule) - Modul petir sedang dilatih
output (STEP_OUTPUT) - Keluaran langkah pelatihan
batch (Apa saja) - Data batch pelatihan saat ini
batch_idx (int) — Indeks dari batch saat ini
Catatan:
Waktu rilis kunci memastikan pemulihan tanpa pemeriksaan dapat dilanjutkan setelah pembaruan parameter selesai
Hanya mengeksekusi ketika keduanya
enable_inprocessdanenable_checkpointlessBenar
get_peft_callback(trainer)
Ambil callback PEFT dari daftar callback pelatih.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
Pengembalian:
PEFT atau None - contoh panggilan balik PEFT jika ditemukan, Tidak ada sebaliknya
_try_adapter_checkpointless_restore(trainer, params_to_save)
Mencoba pemulihan checkpointless untuk parameter adaptor PEFT.
Parameter:
pelatih (Pytorch_Lightning.trainer) - Contoh pelatih petir PyTorch
params_to_save (set) - Set nama parameter untuk disimpan sebagai parameter adaptor
Catatan:
Hanya mengeksekusi sekali per sesi pelatihan (dikendalikan oleh
tried_adapter_checkpointlessbendera)Mengkonfigurasi manajer pos pemeriksaan dengan informasi parameter adaptor
Contoh
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
Manajemen Memori
clean_tensor_hook: Menghapus kait tensor selama pembersihan (mahal tapi menyeluruh)
clean_lightning_module: Membebaskan memori GPU modul Lightning selama restart
Kedua opsi membantu mengurangi jejak memori selama pemulihan kesalahan
Berkoordinasi dengan ParameterUpdateLock untuk pelacakan pembaruan parameter aman utas
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Konektor pos pemeriksaan petir yang mengintegrasikan pemulihan tanpa pemeriksaan dengan pemuatan pos pemeriksaan berbasis disk tradisional.
Konektor ini memperluas PyTorch Lightning _CheckpointConnector untuk memberikan integrasi yang mulus antara pemulihan tanpa pemeriksaan dan restorasi pos pemeriksaan standar. Ini mencoba pemulihan tanpa pemeriksaan terlebih dahulu, kemudian kembali ke pemuatan pos pemeriksaan berbasis disk jika pemulihan tanpa pemeriksaan tidak layak atau gagal.
Parameter
Mewarisi semua parameter dari _ CheckpointConnector
Metode
resume_start(checkpoint_path=None)
Cobalah untuk memuat pos pemeriksaan terlebih dahulu dengan prioritas pemulihan tanpa pemeriksaan.
Parameter:
checkpoint_path (str atau None, opsional) - Jalur ke pos pemeriksaan disk untuk fallback. Default:
None
resume_end()
Selesaikan proses pemuatan pos pemeriksaan dan lakukan operasi pasca-beban.
Catatan
Memperluas
_CheckpointConnectorkelas internal PyTorch Lightning dengan dukungan pemulihan tanpa pemeriksaanMempertahankan kompatibilitas penuh dengan alur kerja pos pemeriksaan PyTorch Lightning standar
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
Memperluas AutoResume dengan pengaturan NeMo yang tertunda untuk mengaktifkan validasi pemulihan tanpa pemeriksaan sebelum resolusi jalur pos pemeriksaan.
Kelas ini mengimplementasikan strategi inisialisasi dua fase yang memungkinkan validasi pemulihan tanpa pemeriksaan terjadi sebelum kembali ke pemuatan pos pemeriksaan berbasis disk tradisional. Ini menunda AutoResume pengaturan secara kondisional untuk mencegah resolusi jalur pos pemeriksaan prematur, memungkinkan untuk memvalidasi terlebih dahulu apakah pemulihan CheckpointManager peer-to-peer tanpa pemeriksaan layak dilakukan.
Parameter
Mewarisi semua parameter dari AutoResume
Metode
setup(trainer, model=None, force_setup=False)
Tunda AutoResume pengaturan secara kondisional untuk mengaktifkan validasi pemulihan tanpa pemeriksaan.
Parameter:
pelatih (Pytorch_Lightning.Trainer atau Lightning.Fabric.Fabric) - Pelatih petir atau contoh Fabric PyTorch
model (opsional) - Contoh model untuk pengaturan. Default:
Noneforce_setup (bool, opsional) - Jika Benar, lewati penundaan dan jalankan penyiapan segera. AutoResume Default:
False
Contoh
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Catatan
Memperluas NeMo AutoResume kelas dengan mekanisme penundaan untuk mengaktifkan pemulihan tanpa pemeriksaan
Bekerja bersama dengan alur
CheckpointlessCompatibleConnectorkerja pemulihan lengkap
