Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Dataloader yang dipetakan memori
Overhead restart lainnya berasal dari pemuatan data: cluster pelatihan tetap menganggur sementara dataloader menginisialisasi, mengunduh data dari sistem file jarak jauh, dan memprosesnya menjadi batch.
Untuk mengatasi hal ini, kami memperkenalkan Dataloader Memory Mapped DataLoader (MMAP), yang menyimpan batch yang telah diambil sebelumnya dalam memori persisten, memastikan mereka tetap tersedia bahkan setelah restart yang disebabkan oleh kesalahan. Pendekatan ini menghilangkan waktu penyiapan dataloader dan memungkinkan pelatihan untuk segera dilanjutkan menggunakan batch yang di-cache, sementara pembuat data secara bersamaan menginisialisasi ulang dan mengambil data berikutnya di latar belakang. Cache data berada di setiap peringkat yang memerlukan data pelatihan dan memelihara dua jenis batch: batch yang baru dikonsumsi yang telah digunakan untuk pelatihan, dan batch yang telah diambil sebelumnya yang siap digunakan segera.
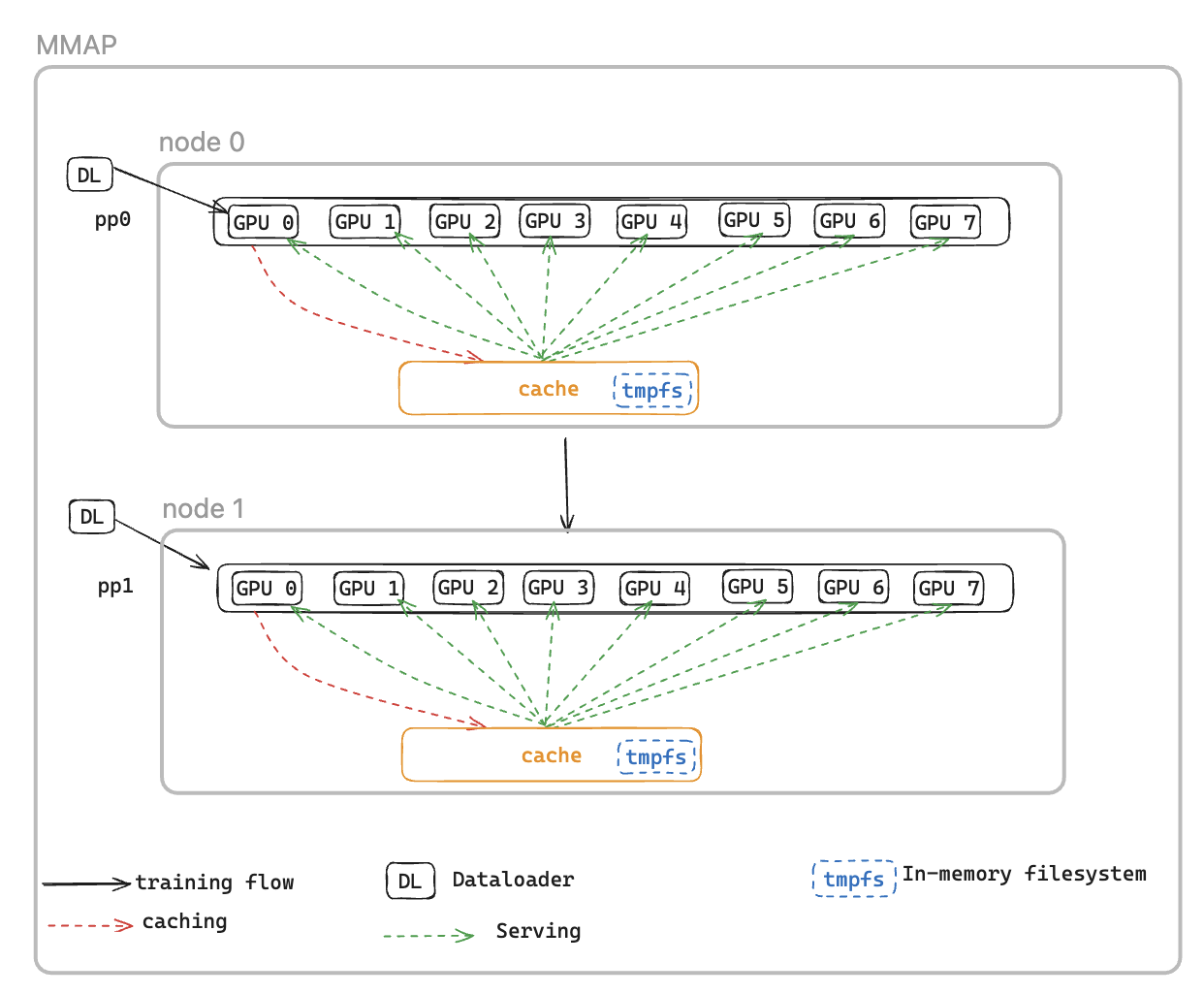
Dataloader MMAP menawarkan dua fitur berikut:
Data Prefetching - Secara proaktif mengambil dan menyimpan data yang dihasilkan oleh dataloader
Persistent Caching - Menyimpan batch yang dikonsumsi dan yang telah diambil sebelumnya dalam sistem file sementara yang bertahan dari proses restart
Menggunakan cache, pekerjaan pelatihan akan mendapat manfaat dari:
Reduced Memory Footprint - Memanfaatkan pemetaan memori I/O untuk mempertahankan satu salinan data bersama dalam memori CPU host, menghilangkan salinan berlebihan di seluruh proses GPU (misalnya, mengurangi dari 8 salinan menjadi 1 pada instance p5 dengan 8 GPU)
Pemulihan Lebih Cepat - Mengurangi Mean Time to Restart (MTTR) dengan mengaktifkan pelatihan untuk segera dilanjutkan dari batch yang di-cache, menghilangkan penantian untuk inisialisasi ulang dataloader dan generasi batch pertama
Konfigurasi MMAP
Untuk menggunakan MMAP, cukup masukkan modul data asli Anda ke MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: Parameter MMAP Dataloader mengontrol lokasi direktori cache, batas ukuran, dan delegasi pengambilan data. Secara default, hanya TP rank 0 per node yang mengambil data dari sumber, sementara peringkat lain dalam grup replikasi data yang sama dibaca dari cache bersama, menghilangkan transfer berlebihan.
MMAPDataModule: Ini membungkus modul data asli dan mengembalikan dataloader mmap untuk kereta dan validasi.
Lihat contoh
Referensi API
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
Kelas konfigurasi untuk fungsionalitas dataloader cache resume memory-mapped (MMAP) dalam pelatihan checkpointless. HyperPod
Konfigurasi ini memungkinkan pemuatan data yang efisien dengan kemampuan caching dan prefetching, memungkinkan pelatihan dilanjutkan dengan cepat setelah kegagalan dengan mempertahankan batch data yang di-cache dalam file yang dipetakan memori.
Parameter
-
cache_dir (str, opsional) - Jalur direktori untuk menyimpan batch data yang di-cache. Default: “/dev/shm/pdl_cache”
-
prefetch_length (int, opsional) - Jumlah batch yang harus diambil sebelumnya selama pelatihan. Default: 10
-
val_prefetch_length (int, opsional) - Jumlah batch yang harus diambil sebelumnya selama validasi. Default: 10
-
lookback_length (int, opsional) - Jumlah batch yang digunakan sebelumnya untuk disimpan dalam cache untuk potensi penggunaan kembali. Default: 2
-
checkpoint_frequency (int, opsional) - Frekuensi langkah-langkah checkpointing model. Digunakan untuk optimasi kinerja cache. Default: Tidak Ada
-
model_parallel_group (objek, opsional) - Grup proses untuk paralelisme model. Jika tidak ada, akan dibuat secara otomatis. Default: Tidak Ada
-
enable_batch_encryption (bool, opsional) - Apakah akan mengaktifkan enkripsi untuk data batch cache. Default: Salah
Metode
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
Membuat dan mengembalikan instance dataloader MMAP yang dikonfigurasi.
Parameter
-
dataloader_init_callable (Callable) - Fungsi untuk menginisialisasi dataloader yang mendasarinya
-
parallel_state_util (object) - Utilitas untuk mengelola keadaan paralel di seluruh proses
-
step (int) - Langkah data untuk melanjutkan dari selama pelatihan
-
is_data_loading_rank (Callable) - Fungsi yang mengembalikan True jika peringkat saat ini harus memuat data
-
create_model_parallel_group_callable (Callable) - Fungsi untuk membuat grup proses paralel model
-
name (str, opsional) - Pengidentifikasi nama untuk dataloader. Default: “Kereta”
-
is_val (bool, opsional) - Apakah ini adalah dataloader validasi. Default: Salah
-
cached_len (int, opsional) - Panjang data cache jika dilanjutkan dari cache yang ada. Default: 0
Pengembalian CacheResumePrefetchedDataLoader atau CacheResumeReadDataLoader - Contoh dataloader MMAP yang dikonfigurasi
Naikkan ValueError jika parameter langkahnya. None
Contoh
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Catatan
-
Direktori cache harus memiliki ruang yang cukup dan I/O kinerja yang cepat (mis.,/dev/shm untuk penyimpanan dalam memori).
-
Pengaturan
checkpoint_frequencymeningkatkan kinerja cache dengan menyelaraskan manajemen cache dengan checkpointing model -
Untuk validasi dataloaders (
is_val=True), langkahnya diatur ulang ke 0 dan cold start dipaksa -
Implementasi dataloader yang berbeda digunakan berdasarkan apakah peringkat saat ini bertanggung jawab untuk pemuatan data
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
DataModule Pembungkus PyTorch Lightning yang menerapkan kemampuan pemuatan data yang dipetakan memori (MMAP) ke yang ada untuk pelatihan tanpa pemeriksaan. DataModules
Kelas ini membungkus PyTorch Lightning yang ada DataModule dan meningkatkannya dengan fungsionalitas MMAP, memungkinkan caching data yang efisien dan pemulihan cepat selama kegagalan pelatihan. Ini mempertahankan kompatibilitas dengan DataModule antarmuka asli sambil menambahkan kemampuan pelatihan tanpa pemeriksaan.
Parameter
- data_module (pl. LightningDataModule)
Yang mendasari DataModule untuk membungkus (misalnya, LLMDataModule)
- mmap_config (mmapConfig)
Objek konfigurasi MMAP yang mendefinisikan perilaku dan parameter caching
parallel_state_util(MegatronParallelStateUtil, opsional)Utilitas untuk mengelola keadaan paralel di seluruh proses terdistribusi. Default: MegatronParallelStateUtil ()
is_data_loading_rank(Dapat dipanggil, opsional)Fungsi yang mengembalikan Benar jika peringkat saat ini harus memuat data. Jika Tidak Ada, default ke parallel_state_util.is_tp_0. Default: Tidak Ada
Atribut
global_step(int)Langkah pelatihan global saat ini, digunakan untuk melanjutkan dari pos pemeriksaan
cached_train_dl_len(int)Panjang cache dari dataloader pelatihan
cached_val_dl_len(int)Panjang cache dari dataloader validasi
Metode
setup(stage=None)
Siapkan modul data yang mendasari untuk tahap pelatihan yang ditentukan.
stage(str, opsional)Tahap pelatihan ('fit', 'validate', 'test', atau 'predict'). Default: Tidak Ada
train_dataloader()
Buat pelatihan DataLoader dengan pembungkus MMAP.
Pengembalian: DataLoader — MMAP-wrapped pelatihan DataLoader dengan kemampuan caching dan prefetching
val_dataloader()
Buat validasi DataLoader dengan pembungkus MMAP.
Pengembalian: DataLoader - MMAP-wrapped validasi DataLoader dengan kemampuan caching
test_dataloader()
Buat pengujian DataLoader jika modul data yang mendasarinya mendukungnya.
Pengembalian: DataLoader atau Tidak Ada - Uji DataLoader dari modul data yang mendasarinya, atau Tidak Ada jika tidak didukung
predict_dataloader()
Buat prediksi DataLoader jika modul data yang mendasarinya mendukungnya.
Pengembalian: DataLoader atau Tidak Ada - Memprediksi DataLoader dari modul data yang mendasarinya, atau Tidak Ada jika tidak didukung
load_checkpoint(checkpoint)
Muat informasi pos pemeriksaan untuk melanjutkan pelatihan dari langkah tertentu.
- pos pemeriksaan (dict)
Kamus pos pemeriksaan yang berisi kunci 'global_step'
get_underlying_data_module()
Dapatkan modul data dibungkus yang mendasarinya.
Pengembalian: pl. LightningDataModule — Modul data asli yang dibungkus
state_dict()
Dapatkan kamus negara bagian MMAP DataModule untuk pos pemeriksaan.
Pengembalian: dict - Kamus yang berisi panjang dataloader cache
load_state_dict(state_dict)
Muat kamus negara untuk memulihkan DataModule status MMAP.
state_dict(dikte)Kamus negara untuk dimuat
Sifat-sifat
data_sampler
Paparkan sampler data modul data yang mendasarinya ke NeMo kerangka kerja.
Pengembalian: objek atau Tidak Ada - Sampler data dari modul data yang mendasarinya
Contoh
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Catatan
Pembungkus mendelegasikan sebagian besar akses atribut ke modul data yang mendasarinya menggunakan __getattr__
Hanya peringkat pemuatan data yang benar-benar menginisialisasi dan menggunakan modul data yang mendasarinya; peringkat lain menggunakan dataloader palsu
Panjang dataloader cache dipertahankan untuk mengoptimalkan kinerja selama dimulainya kembali pelatihan
