Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Pengayaan semantik otomatis untuk Layanan Amazon OpenSearch
Pengantar
Amazon OpenSearch Service menggunakan pencocokan kata ke kata (pencarian leksikal) untuk menemukan hasil, mirip dengan mesin pencari tradisional lainnya. Pendekatan ini bekerja dengan baik untuk kueri tertentu seperti kode produk atau nomor model, tetapi berjuang dengan pencarian abstrak di mana memahami maksud pengguna menjadi penting. Misalnya, ketika Anda mencari “sepatu untuk pantai,” pencarian leksikal cocok dengan kata-kata individual “sepatu,” “pantai,” “untuk,” dan “yang” dalam item katalog, yang berpotensi kehilangan produk relevan seperti “sandal kedap air” atau “alas kaki selancar” yang tidak mengandung istilah pencarian yang tepat.
Pengayaan Semantik Otomatis memecahkan batasan ini dengan mempertimbangkan kecocokan kata kunci dan makna kontekstual di balik pencarian. Fitur ini memahami maksud pencarian dan meningkatkan relevansi pencarian hingga 20%. Aktifkan fitur ini untuk bidang teks dalam indeks Anda untuk meningkatkan hasil pencarian.
catatan
Pengayaan semantik otomatis tersedia untuk domain OpenSearch Layanan yang menjalankan versi 2.19 atau yang lebih baru. Selain itu, domain dengan OpenSearch versi 2.19 juga harus ada di pembaruan versi perangkat lunak layanan terbaru. Saat ini, fitur tersedia untuk domain publik, dan domain VPC tidak didukung.
Detail model dan tolok ukur kinerja
Meskipun fitur ini menangani kompleksitas teknis di balik layar tanpa mengekspos model yang mendasarinya, kami memberikan transparansi melalui deskripsi model singkat dan hasil benchmark untuk membantu Anda membuat keputusan berdasarkan informasi tentang adopsi fitur dalam beban kerja penting Anda.
Pengayaan semantik otomatis menggunakan model sparse pra-terlatih yang dikelola layanan yang bekerja secara efektif tanpa memerlukan penyesuaian khusus. Model menganalisis bidang yang Anda tentukan, memperluasnya menjadi vektor jarang berdasarkan asosiasi yang dipelajari dari beragam data pelatihan. Istilah yang diperluas dan bobot signifikansinya disimpan dalam format indeks Lucene asli untuk pengambilan yang efisien. Kami telah mengoptimalkan proses ini menggunakan mode khusus dokumen, di mana pengkodean hanya
Validasi kinerja kami selama pengembangan fitur menggunakan kumpulan data pengambilan bagian MS MARCO
-
Bahasa Inggris - Peningkatan relevansi 20% dibandingkan pencarian leksikal. Ini juga menurunkan latensi pencarian P90 sebesar 7,7% dibandingkan pencarian leksikal (BM25 adalah 26 ms, dan pengayaan semantik otomatis adalah 24 ms).
-
Multi-lingual - Peningkatan relevansi 105% dibandingkan pencarian leksikal, sedangkan latensi pencarian P90 meningkat 38,4% dibandingkan pencarian leksikal (BM25 adalah 26 ms, dan pengayaan semantik otomatis adalah 36 ms).
Mengingat sifat unik dari setiap beban kerja, kami mendorong Anda untuk mengevaluasi fitur ini di lingkungan pengembangan Anda menggunakan kriteria benchmarking Anda sendiri sebelum membuat keputusan implementasi.
Bahasa yang Didukung
Fitur ini mendukung bahasa Inggris. Selain itu, model ini juga mendukung bahasa Arab, Bengali, China, Finlandia, Prancis, Hindi, Indonesia, Jepang, Korea, Persia, Rusia, Spanyol, Swahili, dan Telugu.
Siapkan indeks pengayaan semantik otomatis untuk domain
Menyiapkan indeks dengan pengayaan semantik otomatis yang diaktifkan untuk bidang teks Anda mudah, dan Anda dapat mengelolanya melalui konsol, API, dan CloudFormation templat selama pembuatan indeks baru. Untuk mengaktifkannya untuk indeks yang ada, Anda perlu membuat ulang indeks dengan pengayaan semantik otomatis diaktifkan untuk bidang teks.
Pengalaman konsol - AWS Konsol memungkinkan Anda untuk dengan mudah membuat indeks dengan bidang pengayaan semantik otomatis. Setelah Anda memilih domain, Anda akan menemukan tombol buat indeks di bagian atas konsol. Setelah Anda mengklik tombol buat indeks, Anda akan menemukan opsi untuk menentukan bidang pengayaan semantik otomatis. Dalam satu indeks, Anda dapat memiliki kombinasi pengayaan semantik otomatis untuk bahasa Inggris dan multibahasa, serta bidang leksikal.
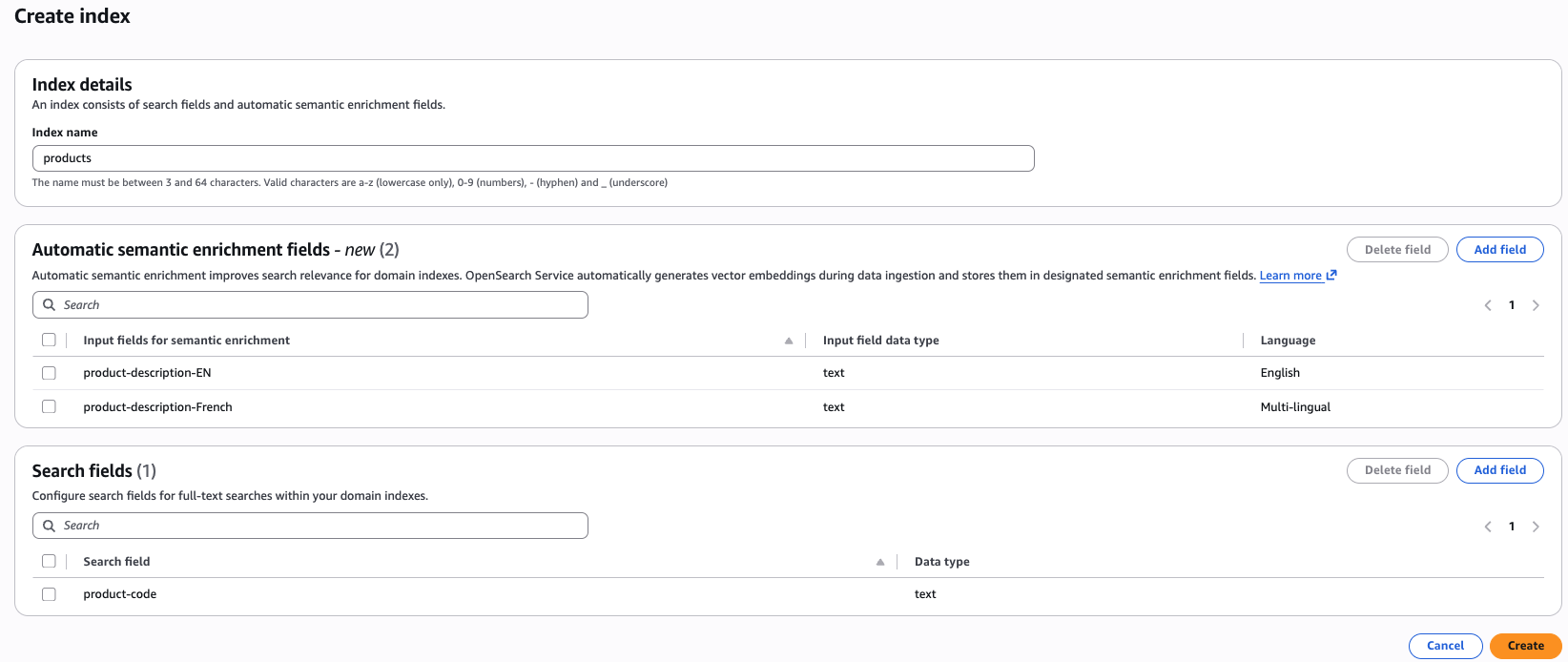
Pengalaman API - Untuk membuat indeks pengayaan semantik otomatis menggunakan AWS Command Line Interface (AWS CLI), gunakan perintah create-index:
aws opensearch create-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body] \
Dalam contoh skema indeks berikut, bidang title_semantik memiliki jenis bidang yang disetel ke teks dan memiliki parameter semantic_enrichment disetel ke status ENABLED. Menyetel parameter semantic_enrichment memungkinkan pengayaan semantik otomatis pada bidang title_semantic. Anda dapat menggunakan bidang language_options untuk menentukan bahasa Inggris atau. MULTI-LINGUAL
aws opensearch create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Untuk menggambarkan indeks yang dibuat, gunakan perintah berikut:
aws opensearch get-index \ --domain-name [domain_name] \ --index-name [index_name] \
Perbarui indeks yang ada
Anda dapat memperbarui indeks yang ada untuk menambahkan bidang pengayaan semantik baru, mengaktifkan atau menonaktifkan pengayaan semantik pada bidang yang ada, atau menambahkan bidang teks non-semantik. Gunakan update-index perintah dan berikan hanya bidang yang ingin Anda ubah diindex-schema. Bidang yang tidak termasuk dalam permintaan dibiarkan tidak berubah.
catatan
Indeks settings tidak dapat diperbarui. Jika Anda menyertakan settings blok dalam permintaan, operasi mengembalikan kesalahan validasi. Untuk mengubah pengaturan indeks, Anda harus menghapus dan membuat ulang indeks.
Untuk memperbarui indeks menggunakan AWS CLI, gunakan update-index perintah:
aws opensearch update-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body]
Tambahkan bidang pengayaan semantik baru
Anda dapat menambahkan text bidang baru dengan pengayaan semantik diaktifkan ke indeks yang ada. Layanan ini secara otomatis menyiapkan model ML yang diperlukan, pipa konsumsi, dan pipa pencarian. Dokumen baru yang diindeks setelah pembaruan diperkaya secara otomatis.
penting
Dokumen yang ada tidak diisi kembali. Untuk mengisi bidang pengayaan semantik pada dokumen yang ada, Anda harus menelannya kembali setelah pembaruan. Sampai dicerna kembali, dokumen yang ada tidak akan mendapat manfaat dari pencarian semantik di bidang baru.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Nonaktifkan pengayaan semantik di lapangan
Untuk menonaktifkan pengayaan semantik pada bidang yang saat ini mengaktifkannya, setel ke. status DISABLED Bidang dihapus dari pipa menelan dan mencari. Bidang teks yang mendasari dan bidang penyematannya tetap berada dalam indeks tetapi tidak lagi diperkaya.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Perbarui batasan
Operasi berikut tidak didukung oleh update-index dan mengharuskan Anda untuk menghapus dan membuat ulang indeks:
-
language_optionsMengubah bidang yang saat ini mengaktifkan pengayaan semantik. Nonaktifkan bidang terlebih dahulu, lalu aktifkan kembali dengan opsi bahasa baru. -
Memperbarui bidang bersarang. Pengayaan semantik hanya didukung di bidang tingkat atas.
text -
Memperbarui indeks
settings.
catatan
Jika indeks memiliki saluran pencernaan atau pencarian khusus yang tidak dibuat oleh pengayaan semantik otomatis, operasi pembaruan diblokir. Hapus pipeline khusus sebelum menambahkan bidang pengayaan semantik.
Konsumsi dan pencarian data
Setelah Anda membuat indeks dengan pengayaan semantik otomatis diaktifkan, fitur ini bekerja secara otomatis selama proses penyerapan data, tidak diperlukan konfigurasi tambahan.
Penyerapan data: Saat Anda menambahkan dokumen ke indeks Anda, sistem secara otomatis:
-
Menganalisis bidang teks yang Anda tentukan untuk pengayaan semantik
-
Menghasilkan pengkodean semantik menggunakan OpenSearch model sparse yang dikelola Layanan
-
Menyimpan representasi yang diperkaya ini bersama data asli Anda
Proses ini menggunakan OpenSearch konektor HTML bawaan dan saluran pipa tertelan, yang dibuat dan dikelola secara otomatis di belakang layar.
Penelusuran: Data pengayaan semantik sudah diindeks, sehingga kueri berjalan secara efisien tanpa menjalankan model ML lagi. Ini berarti Anda mendapatkan relevansi penelusuran yang ditingkatkan tanpa overhead latensi penelusuran tambahan.
Mengkonfigurasi izin untuk pengayaan semantik otomatis
Sebelum membuat indeks dengan pengayaan semantik otomatis, Anda perlu mengonfigurasi izin yang diperlukan. Bagian ini menjelaskan izin yang diperlukan untuk operasi indeks yang berbeda dan cara mengaturnya untuk skenario kontrol akses AWS Identity and Access Management (IAM) dan halus.
Izin IAM
Izin IAM berikut diperlukan untuk operasi pengayaan semantik otomatis. Izin ini bervariasi tergantung pada operasi indeks tertentu yang ingin Anda lakukan.
CreateIndex Izin API
Untuk membuat indeks dengan pengayaan semantik otomatis, Anda memerlukan izin IAM berikut:
-
es:CreateIndex— Buat indeks dengan kemampuan pengayaan semantik. -
es:ESHttpHead— Lakukan permintaan HEAD untuk memeriksa keberadaan indeks. -
es:ESHttpPut— Lakukan permintaan PUT untuk pembuatan indeks. -
es:ESHttpPost— Lakukan permintaan POST untuk operasi indeks.
UpdateIndex Izin API
Untuk memperbarui indeks yang ada dengan pengayaan semantik otomatis, Anda memerlukan izin IAM berikut:
-
es:UpdateIndex— Perbarui pengaturan indeks dan pemetaan. -
es:ESHttpPut— Lakukan permintaan PUT untuk pembaruan indeks. -
es:ESHttpGet— Lakukan permintaan GET untuk mengambil informasi indeks. -
es:ESHttpPost— Lakukan permintaan POST untuk operasi indeks.
GetIndex Izin API
Untuk mengambil informasi tentang indeks dengan pengayaan semantik otomatis, Anda memerlukan izin IAM berikut:
-
es:GetIndex— Ambil informasi indeks dan pengaturan. -
es:ESHttpGet— Lakukan permintaan GET untuk mengambil data indeks.
DeleteIndex Izin API
Untuk menghapus indeks dengan pengayaan semantik otomatis, Anda memerlukan izin IAM berikut:
-
es:DeleteIndex— Hapus indeks dan komponen pengayaan semantiknya. -
es:ESHttpDelete— Lakukan permintaan DELETE untuk penghapusan indeks.
Contoh kebijakan IAM
Contoh kebijakan akses berbasis identitas berikut memberikan izin yang diperlukan bagi pengguna untuk mengelola indeks dengan pengayaan semantik otomatis:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSemanticEnrichmentIndexOperations", "Effect": "Allow", "Action": [ "es:CreateIndex", "es:UpdateIndex", "es:GetIndex", "es:DeleteIndex", "es:ESHttpHead", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost", "es:ESHttpDelete" ], "Resource": "arn:aws:es:aws-region:111122223333:domain/domain-name" } ] }
Ganti aws-region111122223333,, dan domain-name dengan nilai spesifik Anda. Anda dapat membatasi akses lebih lanjut dengan menentukan pola indeks tertentu di ARN sumber daya.
Fine-grained izin kontrol akses
Jika domain OpenSearch Layanan Amazon Anda mengaktifkan kontrol akses berbutir halus, Anda memerlukan izin tambahan di luar izin IAM. Izin berikut diperlukan untuk setiap operasi indeks.
CreateIndex Izin API
Ketika kontrol akses halus diaktifkan, izin tambahan berikut diperlukan untuk membuat indeks dengan pengayaan semantik otomatis:
-
indices:admin/create— Buat operasi indeks. -
indices:admin/mapping/put— Buat dan perbarui pemetaan indeks. -
cluster:admin/opensearch/ml/create_connector— Buat konektor pembelajaran mesin untuk pemrosesan semantik. -
cluster:admin/opensearch/ml/register_model— Daftarkan model pembelajaran mesin untuk pengayaan semantik. -
cluster:admin/ingest/pipeline/put— Buat pipeline ingest untuk pemrosesan data. -
cluster:admin/search/pipeline/put— Buat pipeline pencarian untuk pemrosesan kueri.
UpdateIndex Izin API
Ketika kontrol akses halus diaktifkan, izin tambahan berikut diperlukan untuk memperbarui indeks dengan pengayaan semantik otomatis:
-
indices:admin/get— Ambil informasi indeks. -
indices:admin/settings/update— Perbarui pengaturan indeks. -
indices:admin/mapping/put— Perbarui pemetaan indeks. -
cluster:admin/opensearch/ml/create_connector— Buat konektor pembelajaran mesin. -
cluster:admin/opensearch/ml/register_model— Daftarkan model pembelajaran mesin. -
cluster:admin/ingest/pipeline/put— Buat saluran pipa tertelan. -
cluster:admin/search/pipeline/put— Buat pipeline pencarian. -
cluster:admin/ingest/pipeline/get— Ambil informasi pipa ingest. -
cluster:admin/search/pipeline/get— Ambil informasi pipa pencarian.
GetIndex Izin API
Ketika kontrol akses halus diaktifkan, izin tambahan berikut diperlukan untuk mengambil informasi tentang indeks dengan pengayaan semantik otomatis:
-
indices:admin/get— Ambil informasi indeks. -
cluster:admin/ingest/pipeline/get— Ambil informasi pipa ingest. -
cluster:admin/search/pipeline/get— Ambil informasi pipa pencarian.
DeleteIndex Izin API
Ketika kontrol akses halus diaktifkan, izin tambahan berikut diperlukan untuk menghapus indeks dengan pengayaan semantik otomatis:
-
indices:admin/delete— Hapus operasi indeks.
Penulisan Ulang Kueri
Pengayaan semantik otomatis secara otomatis mengonversi kueri “kecocokan” yang ada menjadi kueri penelusuran semantik tanpa memerlukan modifikasi kueri. Jika kueri pencocokan adalah bagian dari kueri gabungan, sistem akan melintasi struktur kueri Anda, menemukan kueri kecocokan, dan menggantinya dengan kueri jarang saraf. Saat ini, fitur tersebut hanya mendukung penggantian kueri “match”, apakah itu kueri mandiri atau bagian dari kueri gabungan. “multi_match” tidak didukung. Selain itu, fitur ini mendukung semua kueri gabungan untuk menggantikan kueri pencocokan bersarang mereka. Kueri majemuk meliputi: bool, boosting, constant_score, dis_max, function_score, dan hybrid.
Keterbatasan pengayaan semantik otomatis
Pencarian semantik otomatis paling efektif bila diterapkan pada bidang berukuran kecil hingga menengah yang berisi konten bahasa alami, seperti judul film, deskripsi produk, ulasan, dan ringkasan. Meskipun pencarian semantik meningkatkan relevansi untuk sebagian besar kasus penggunaan, itu mungkin tidak optimal untuk skenario tertentu. Pertimbangkan batasan berikut saat memutuskan apakah akan menerapkan pengayaan semantik otomatis untuk kasus penggunaan spesifik Anda.
-
Dokumen yang sangat panjang — Model sparse saat ini hanya memproses 8.192 token pertama dari setiap dokumen untuk bahasa Inggris. Untuk dokumen multibahasa, itu 512 token. Untuk artikel yang panjang, pertimbangkan untuk menerapkan potongan dokumen untuk memastikan pemrosesan konten lengkap.
-
Beban kerja analisis log — Pengayaan semantik secara signifikan meningkatkan ukuran indeks, yang mungkin tidak diperlukan untuk analisis log di mana pencocokan yang tepat biasanya cukup. Konteks semantik tambahan jarang meningkatkan efektivitas pencarian log yang cukup untuk membenarkan peningkatan persyaratan penyimpanan.
-
Pengayaan semantik otomatis tidak kompatibel dengan fitur Sumber Derived.
-
Throttling — Permintaan inferensi pengindeksan saat ini dibatasi pada 200 TPS untuk domain Layanan. OpenSearch Ini adalah batas lunak; menjangkau AWS Support untuk batas yang lebih tinggi.
Harga
Amazon OpenSearch Service menagih pengayaan semantik otomatis berdasarkan OpenSearch Compute Units (OCU) yang dikonsumsi selama pembuatan vektor jarang pada waktu pengindeksan. Anda dikenakan biaya hanya untuk penggunaan aktual selama pengindeksan untuk bidang teks tempat Anda mengaktifkan pengayaan semantik otomatis. One Semantic Search OCU dapat memproses 11,1 juta token untuk konten bahasa Inggris. Untuk memproses 2,4 miliar token, Anda membutuhkan sekitar 216 Pencarian Semantik OCU-hours (2,4 miliar/11,10 juta). Dengan harga $0,24 per Pencarian Semantik OCU-hour, biaya untuk memproses 10 GB data untuk pencarian semantik otomatis adalah $51 (216 x $0. OCU-hours 24/OCU-jam). Tidak ada biaya OCU Pencarian Semantik tambahan selama operasi pencarian atau untuk penyimpanan data.
Anda dapat memantau konsumsi ini menggunakan CloudWatch metrik AmazonSemanticSearchOCU. Untuk detail spesifik tentang batas token model, throughput volume per OCU, dan contoh perhitungan sampel, kunjungi Harga OpenSearch Layanan
