Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
# Koneksi Redshift
Anda dapat menggunakan AWS Glue for Spark untuk membaca dan menulis ke tabel di database Amazon Redshift. Saat menghubungkan ke database Amazon Redshift, AWS Glue memindahkan data melalui Amazon S3 untuk mencapai throughput maksimum, menggunakan Amazon Redshift SQL dan perintah. `COPY` `UNLOAD` Di AWS Glue 4.0 dan yang lebih baru, Anda dapat menggunakan [integrasi Amazon Redshift untuk Apache Spark](https://docs.aws.amazon.com/redshift/latest/mgmt/spark-redshift-connector.html) untuk membaca dan menulis dengan pengoptimalan dan fitur khusus untuk Amazon Redshift di luar yang tersedia saat menghubungkan melalui versi sebelumnya.
Pelajari tentang bagaimana AWS Glue mempermudah pengguna Amazon Redshift untuk bermigrasi ke AWS Glue untuk integrasi data tanpa server dan ETL.
[](http://www.youtube.com/watch?v=ZapycBq8TKU)
## Mengkonfigurasi koneksi Redshift
Untuk menggunakan cluster Amazon Redshift di AWS Glue, Anda memerlukan beberapa prasyarat:
+ Direktori Amazon S3 untuk digunakan untuk penyimpanan sementara saat membaca dari dan menulis ke database.
+ VPC Amazon yang memungkinkan komunikasi antara kluster Amazon Redshift, pekerjaan Glue, dan direktori Amazon AWS S3 Anda.
+ Izin IAM yang sesuai pada tugas AWS Glue dan cluster Amazon Redshift.
### Mengkonfigurasi peran IAM
**Siapkan peran untuk cluster Amazon Redshift**
Cluster Amazon Redshift Anda harus dapat membaca dan menulis ke Amazon S3 agar dapat berintegrasi dengan AWS pekerjaan Glue. Untuk mengizinkannya, Anda dapat mengaitkan peran IAM dengan cluster Amazon Redshift yang ingin Anda sambungkan. Peran Anda harus memiliki kebijakan yang mengizinkan baca dari dan tulis ke direktori sementara Amazon S3 Anda. Peran Anda harus memiliki hubungan kepercayaan yang memungkinkan `redshift.amazonaws.com` layanan untuk`AssumeRole`.
**Untuk mengaitkan peran IAM dengan Amazon Redshift**
1. **Prasyarat**: Bucket atau direktori Amazon S3 yang digunakan untuk penyimpanan sementara file.
1. Identifikasi izin Amazon S3 mana yang dibutuhkan cluster Amazon Redshift Anda. Saat memindahkan data ke dan dari klaster Amazon Redshift, AWS Glue jobs mengeluarkan pernyataan COPY dan UNLOAD terhadap Amazon Redshift. Jika pekerjaan Anda mengubah tabel di Amazon Redshift, AWS Glue juga akan mengeluarkan pernyataan CREATE LIBRARY. Untuk informasi tentang izin Amazon S3 tertentu yang diperlukan Amazon Redshift untuk menjalankan pernyataan ini, lihat dokumentasi Amazon Redshift: Amazon Redshift: Izin untuk mengakses Sumber [Daya lainnya](https://docs.aws.amazon.com/redshift/latest/dg/copy-usage_notes-access-permissions.html). AWS
1. Di konsol IAM, buat kebijakan IAM dengan izin yang diperlukan. Untuk informasi selengkapnya tentang membuat kebijakan [Membuat kebijakan IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies_create.html).
1. Di konsol IAM, buat hubungan peran dan kepercayaan yang memungkinkan Amazon Redshift untuk mengambil peran tersebut. Ikuti petunjuk dalam dokumentasi IAM [Untuk membuat peran untuk AWS layanan (konsol)](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-service.html#roles-creatingrole-service-console)
+ Ketika diminta untuk memilih kasus penggunaan AWS layanan, pilih “Redshift - Customizable”.
+ Saat diminta untuk melampirkan kebijakan, pilih kebijakan yang telah Anda tetapkan sebelumnya.
**catatan**
Untuk informasi selengkapnya tentang mengonfigurasi peran untuk Amazon Redshift, [lihat Mengotorisasi Amazon Redshift untuk AWS mengakses layanan lain atas](https://docs.aws.amazon.com/redshift/latest/mgmt/authorizing-redshift-service.html) nama Anda dalam dokumentasi Amazon Redshift.
1. Di konsol Amazon Redshift, kaitkan peran tersebut dengan cluster Amazon Redshift Anda. Ikuti petunjuk dalam [dokumentasi Amazon Redshift](https://docs.aws.amazon.com/redshift/latest/mgmt/copy-unload-iam-role.html).
Pilih opsi yang disorot di konsol Amazon Redshift untuk mengonfigurasi pengaturan ini:

**catatan**
Secara default, pekerjaan AWS Glue meneruskan kredenal sementara Amazon Redshift yang dibuat menggunakan peran yang Anda tentukan untuk menjalankan pekerjaan. Kami tidak menyarankan menggunakan kredensyal ini. Untuk tujuan keamanan, kredensyal ini kedaluwarsa setelah 1 jam.
**Siapkan peran untuk pekerjaan AWS Glue**
Pekerjaan AWS Glue membutuhkan peran untuk mengakses bucket Amazon S3. Anda tidak memerlukan izin IAM untuk klaster Amazon Redshift, akses Anda dikendalikan oleh konektivitas di Amazon VPC dan kredenal database Anda.
### Siapkan Amazon VPC
**Untuk menyiapkan akses untuk penyimpanan data Amazon Redshift**
1. Masuk ke Konsol Manajemen AWS dan buka konsol Amazon Redshift di. [https://console.aws.amazon.com/redshiftv2/](https://console.aws.amazon.com/redshiftv2/)
1. Di panel navigasi sebelah kiri, pilih **Klaster**.
1. Pilih nama klaster yang ingin Anda akses dari AWS Glue.
1. Di bagian **Properti Klaster**, pilih grup keamanan di **Grup keamanan VPC** untuk mengizinkan AWS Glue untuk digunakan. Catat nama grup keamanan yang Anda pilih untuk referensi di masa mendatang. Memilih grup keamanan membuka daftar **Grup Keamanan** konsol Amazon EC2.
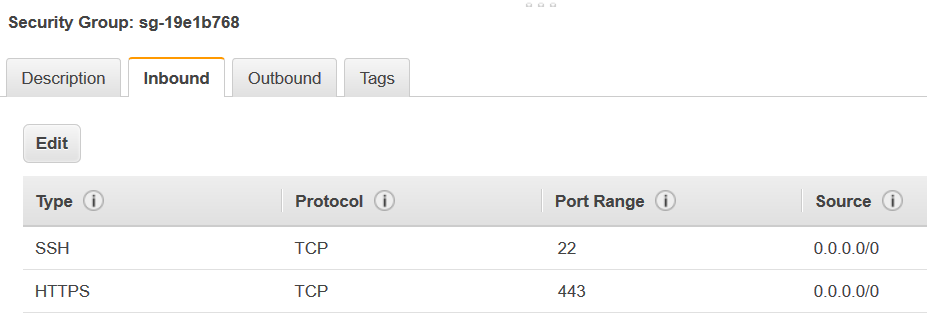
1. Memilih grup keamanan untuk memodifikasi dan menavigasi ke tab **Inbound**.
1. Tambahkan aturan self-referencing untuk mengizinkan komponen AWS Glue untuk berkomunikasi. Secara khusus, tambahkan atau konfirmasi bahwa ada aturan **Jenis** `All TCP`, **Protokol** adalah `TCP`, **Rentang Port** mencakup semua port, dan yang **Sumber** adalah nama grup keamanan yang sama seperti **ID Grup**.
Aturan inbound terlihat serupa dengan yang berikut ini:
****
[See the AWS documentation website for more details](http://docs.aws.amazon.com/id_id/glue/latest/dg/aws-glue-programming-etl-connect-redshift-home.html)
Contoh:
1. Menambahkan aturan untuk lalu lintas outbound juga. Baik dengan membuka lalu lintas outbound ke semua port, misalnya:
****
[See the AWS documentation website for more details](http://docs.aws.amazon.com/id_id/glue/latest/dg/aws-glue-programming-etl-connect-redshift-home.html)
Atau membuat aturan self-referencing di mana **Jenis** `All TCP`, **Protokol** adalah `TCP`, **Rentang Port** mencakup semua port, dan yang **Tujuan** adalah nama grup keamanan yang sama seperti **ID Grup**. Jika menggunakan VPC endpoint Amazon S3, maka tambahkan juga aturan HTTPS untuk akses Amazon S3. {{s3-prefix-list-id}}Diperlukan dalam aturan grup keamanan untuk mengizinkan lalu lintas dari VPC ke titik akhir VPC Amazon S3.
Contoh:
****
[See the AWS documentation website for more details](http://docs.aws.amazon.com/id_id/glue/latest/dg/aws-glue-programming-etl-connect-redshift-home.html)
### Mengatur AWS Glue
Anda perlu membuat koneksi AWS Glue Data Catalog yang menyediakan informasi koneksi Amazon VPC.
**Untuk mengonfigurasi konektivitas Amazon Redshift Amazon VPC ke Glue AWS di konsol**
1. Buat koneksi Katalog Data dengan mengikuti langkah-langkah di:[Menambahkan AWS Glue koneksi](console-connections.md). Setelah membuat koneksi, pertahankan nama koneksi,{{connectionName}}, untuk langkah selanjutnya.
+ Saat memilih **jenis Koneksi**, pilih **Amazon Redshift**.
+ Saat memilih klaster **Redshift, pilih klaster** Anda berdasarkan nama.
+ Berikan informasi koneksi default untuk pengguna Amazon Redshift di klaster Anda.
+ Pengaturan VPC Amazon Anda akan dikonfigurasi secara otomatis.
**catatan**
Anda harus menyediakan VPC Amazon Anda `PhysicalConnectionRequirements` secara manual saat membuat koneksi **Amazon Redshift melalui** SDK. AWS
1. Dalam konfigurasi pekerjaan AWS Glue Anda, berikan {{connectionName}} sebagai **koneksi jaringan Tambahan**.
## Contoh: Membaca dari tabel Amazon Redshift
Anda dapat membaca dari cluster Amazon Redshift dan lingkungan tanpa server Amazon Redshift.
**Prasyarat: Tabel Amazon** Redshift yang ingin Anda baca. Ikuti langkah-langkah di bagian sebelumnya [Mengkonfigurasi koneksi Redshift](#aws-glue-programming-etl-connect-redshift-configure) setelah itu Anda harus memiliki URI Amazon S3 untuk direktori sementara, {{temp-s3-dir}} dan peran IAM,{{rs-role-name}}, (dalam akun). {{role-account-id}}
------
#### [ Using the Data Catalog ]
**Prasyarat Tambahan:** Database Katalog Data dan Tabel untuk tabel Amazon Redshift yang ingin Anda baca. Untuk informasi selengkapnya tentang Katalog Data, lihat[Penemuan dan katalogisasi data di AWS Glue](catalog-and-crawler.md). Setelah membuat entri untuk tabel Amazon Redshift Anda, Anda akan mengidentifikasi koneksi Anda dengan {{redshift-dc-database-name}} dan. {{redshift-table-name}}
**Konfigurasi:** Dalam opsi fungsi Anda, Anda akan mengidentifikasi Tabel Katalog Data Anda dengan `table_name` parameter `database` dan. Anda akan mengidentifikasi direktori sementara Amazon S3 Anda dengan. `redshift_tmp_dir` Anda juga akan memberikan {{rs-role-name}} menggunakan `aws_iam_role` kunci dalam `additional_options` parameter.
```
glueContext.create_dynamic_frame.from_catalog(
database = "{{redshift-dc-database-name}}",
table_name = "{{redshift-table-name}}",
redshift_tmp_dir = args["{{temp-s3-dir}}"],
additional_options = {"aws_iam_role": "arn:aws:iam::{{role-account-id}}:role/{{rs-role-name}}"})
```
------
#### [ Connecting directly ]
**Prasyarat Tambahan:** Anda akan memerlukan nama tabel Amazon Redshift Anda (. {{redshift-table-name}} Anda akan memerlukan informasi koneksi JDBC untuk cluster Amazon Redshift yang menyimpan tabel itu. Anda akan memberikan informasi koneksi Anda dengan{{host}},{{port}},{{redshift-database-name}}, {{username}} dan{{password}}.
Anda dapat mengambil informasi koneksi dari konsol Amazon Redshift saat bekerja dengan klaster Amazon Redshift. Saat menggunakan Amazon Redshift tanpa server, lihat Menghubungkan ke [Amazon Redshift Tanpa Server di dokumentasi Amazon Redshift](https://docs.aws.amazon.com//redshift/latest/mgmt/serverless-connecting.html).
**Konfigurasi:** Dalam opsi fungsi Anda, Anda akan mengidentifikasi parameter koneksi Anda dengan`url`,`dbtable`, `user` dan`password`. Anda akan mengidentifikasi direktori sementara Amazon S3 Anda dengan. `redshift_tmp_dir` Anda dapat menentukan peran IAM Anda menggunakan `aws_iam_role` saat Anda menggunakan`from_options`. Sintaksnya mirip dengan menghubungkan melalui Katalog Data, tetapi Anda meletakkan parameter di `connection_options` peta.
Ini adalah praktik yang buruk untuk membuat hardcode kata sandi ke dalam skrip AWS Glue. Pertimbangkan untuk menyimpan kata sandi Anda AWS Secrets Manager dan mengambilnya di skrip Anda dengan SDK for Python (Boto3).
```
my_conn_options = {
"url": "jdbc:redshift://{{host}}:{{port}}/{{redshift-database-name}}",
"dbtable": "{{redshift-table-name}}",
"user": "{{username}}",
"password": "{{password}}",
"redshiftTmpDir": args["{{temp-s3-dir}}"],
"aws_iam_role": "arn:aws:iam::{{account id}}:role/{{rs-role-name}}"
}
df = glueContext.create_dynamic_frame.from_options("redshift", my_conn_options)
```
------
## Contoh: Menulis ke tabel Amazon Redshift
Anda dapat menulis ke cluster Amazon Redshift dan lingkungan tanpa server Amazon Redshift.
**Prasyarat**: Cluster Amazon Redshift dan ikuti langkah-langkah di bagian sebelumnya [Mengkonfigurasi koneksi Redshift](#aws-glue-programming-etl-connect-redshift-configure) setelah itu Anda harus memiliki URI Amazon S3 untuk direktori sementara, {{temp-s3-dir}} dan peran IAM,, (dalam akun). {{rs-role-name}} {{role-account-id}} Anda juga akan membutuhkan konten `DynamicFrame` yang ingin Anda tulis ke database.
------
#### [ Using the Data Catalog ]
**Prasyarat Tambahan** Database Katalog Data untuk klaster Amazon Redshift dan tabel yang ingin Anda tulis. Untuk informasi selengkapnya tentang Katalog Data, lihat[Penemuan dan katalogisasi data di AWS Glue](catalog-and-crawler.md). Anda akan mengidentifikasi koneksi Anda dengan {{redshift-dc-database-name}} dan tabel target dengan{{redshift-table-name}}.
**Konfigurasi:** Dalam opsi fungsi Anda, Anda akan mengidentifikasi Database Katalog Data Anda dengan `database` parameter, lalu berikan tabel dengan`table_name`. Anda akan mengidentifikasi direktori sementara Amazon S3 Anda dengan. `redshift_tmp_dir` Anda juga akan memberikan {{rs-role-name}} menggunakan `aws_iam_role` kunci dalam `additional_options` parameter.
```
glueContext.write_dynamic_frame.from_catalog(
frame = {{input dynamic frame}},
database = "{{redshift-dc-database-name}}",
table_name = "{{redshift-table-name}}",
redshift_tmp_dir = args["{{temp-s3-dir}}"],
additional_options = {"aws_iam_role": "arn:aws:iam::{{account-id}}:role/{{rs-role-name}}"})
```
------
#### [ Connecting through a AWS Glue connection ]
Anda dapat terhubung ke Amazon Redshift secara langsung menggunakan metode ini`write_dynamic_frame.from_options`. Namun, daripada memasukkan detail koneksi Anda langsung ke skrip Anda, Anda dapat mereferensikan detail koneksi yang disimpan dalam koneksi Katalog Data dengan `from_jdbc_conf` metode ini. Anda dapat melakukan ini tanpa merayapi atau membuat tabel Katalog Data untuk database Anda. Untuk informasi selengkapnya tentang koneksi Katalog Data, lihat[Menghubungkan ke data](glue-connections.md).
**Prasyarat Tambahan:** Koneksi Katalog Data untuk database Anda, tabel Amazon Redshift yang ingin Anda baca
**Konfigurasi:** Anda akan mengidentifikasi koneksi Katalog Data Anda dengan{{dc-connection-name}}. Anda akan mengidentifikasi database dan tabel Amazon Redshift Anda dengan {{redshift-table-name}} dan. {{redshift-database-name}} Anda akan memberikan informasi koneksi Katalog Data Anda dengan `catalog_connection` dan informasi Amazon Redshift Anda dengan `dbtable` dan. `database` Sintaksnya mirip dengan menghubungkan melalui Katalog Data, tetapi Anda meletakkan parameter di `connection_options` peta.
```
my_conn_options = {
"dbtable": "{{redshift-table-name}}",
"database": "{{redshift-database-name}}",
"aws_iam_role": "arn:aws:iam::{{role-account-id}}:role/{{rs-role-name}}"
}
glueContext.write_dynamic_frame.from_jdbc_conf(
frame = {{input dynamic frame}},
catalog_connection = "{{dc-connection-name}}",
connection_options = my_conn_options,
redshift_tmp_dir = args["{{temp-s3-dir}}"])
```
------
## Referensi opsi koneksi Amazon Redshift
Opsi koneksi dasar yang digunakan untuk semua koneksi AWS Glue JDBC untuk mengatur informasi seperti`url`, `user` dan `password` konsisten di semua jenis JDBC. Untuk informasi selengkapnya tentang parameter JDBC standar, lihat. [Referensi opsi koneksi JDBC](aws-glue-programming-etl-connect-jdbc-home.md#aws-glue-programming-etl-connect-jdbc)
Jenis koneksi Amazon Redshift membutuhkan beberapa opsi koneksi tambahan:
+ `"redshiftTmpDir"`: (Wajib) Jalur Amazon S3 tempat data sementara dapat dipentaskan saat menyalin dari database.
+ `"aws_iam_role"`: (Opsional) ARN untuk peran IAM. Pekerjaan AWS Glue akan meneruskan peran ini ke klaster Amazon Redshift untuk memberikan izin klaster yang diperlukan untuk menyelesaikan instruksi dari pekerjaan tersebut.
### Opsi koneksi tambahan tersedia di AWS Glue 4.0\+
Anda juga dapat meneruskan opsi untuk konektor Amazon Redshift baru melalui opsi koneksi AWS Glue. Untuk daftar lengkap opsi konektor yang didukung, lihat bagian *Parameter Spark SQL* di [integrasi Amazon Redshift](https://docs.aws.amazon.com/redshift/latest/mgmt/spark-redshift-connector.html) untuk Apache Spark.
Untuk kenyamanan Anda, kami mengulangi opsi baru tertentu di sini:
| Nama | Diperlukan | Default | Deskripsi |
| --- | --- | --- | --- |
| autopushdown | Tidak | BETUL | Menerapkan pushdown predikat dan kueri dengan menangkap dan menganalisis rencana logis Spark untuk operasi SQL. Operasi diterjemahkan ke dalam kueri SQL, dan kemudian dijalankan di Amazon Redshift untuk meningkatkan kinerja. |
| autopushdown.s3\_result\_cache | Tidak | SALAH | Cache kueri SQL untuk membongkar data untuk pemetaan jalur Amazon S3 di memori sehingga kueri yang sama tidak perlu dijalankan lagi dalam sesi Spark yang sama. Hanya didukung saat `autopushdown` diaktifkan. |
| unload\_s3\_format | Tidak | PARQUET | PARQUET - Membongkar hasil kueri dalam format Parket.
TEKS - Membongkar hasil kueri dalam format teks yang dibatasi pipa. |
| sse\_kms\_key | Tidak | N/A | Kunci AWS SSE-KMS untuk digunakan untuk enkripsi selama `UNLOAD` operasi alih-alih enkripsi default untuk. AWS |
| ekstrakoopiopsi | Tidak | N/A | Daftar opsi tambahan untuk ditambahkan ke perintah Amazon `COPY` Redshift saat memuat data, `TRUNCATECOLUMNS` seperti `MAXERROR n` atau (untuk opsi lain [lihat COPY: Parameter opsional](https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html#r_COPY-syntax-overview-optional-parameters)).
Perhatikan bahwa karena opsi ini ditambahkan ke akhir `COPY` perintah, hanya opsi yang masuk akal di akhir perintah yang dapat digunakan. Itu harus mencakup sebagian besar kasus penggunaan yang mungkin. |
| csvnullstring (eksperimental) | Tidak | NULL | Nilai String untuk menulis untuk nulls saat menggunakan CSV. `tempformat` Ini harus menjadi nilai yang tidak muncul dalam data aktual Anda. |
Parameter baru ini dapat digunakan dengan cara-cara berikut.
**Opsi baru untuk peningkatan kinerja**
Konektor baru memperkenalkan beberapa opsi peningkatan kinerja baru:
+ `autopushdown`: Diaktifkan secara default.
+ `autopushdown.s3_result_cache`: Dinonaktifkan secara default.
+ `unload_s3_format`: secara `PARQUET` default.
Untuk informasi tentang penggunaan opsi ini, lihat [Integrasi Amazon Redshift untuk Apache](https://docs.aws.amazon.com/redshift/latest/mgmt/spark-redshift-connector.html) Spark. Kami menyarankan agar Anda tidak mengaktifkan ` autopushdown.s3_result_cache` ketika Anda memiliki operasi baca dan tulis campuran karena hasil cache mungkin berisi informasi basi. Opsi `unload_s3_format` ini diatur ke secara `PARQUET` default untuk `UNLOAD` perintah, untuk meningkatkan kinerja dan mengurangi biaya penyimpanan. Untuk menggunakan perilaku default `UNLOAD` perintah, setel ulang opsi ke`TEXT`.
**Opsi enkripsi baru untuk membaca**
Secara default, data dalam folder sementara yang AWS Glue digunakan saat membaca data dari tabel Amazon Redshift dienkripsi menggunakan enkripsi. `SSE-S3` Untuk menggunakan kunci terkelola pelanggan from AWS Key Management Service (AWS KMS) untuk mengenkripsi data Anda, Anda dapat mengatur [dari `("sse_kms_key" → kmsKey)` mana KSMKey adalah ID kunci AWS KMS](https://docs.aws.amazon.com/kms/latest/developerguide/find-cmk-id-arn.html), bukan opsi `("extraunloadoptions" → s"ENCRYPTED KMS_KEY_ID '$kmsKey'")` pengaturan lama di versi 3.0. AWS Glue
```
datasource0 = glueContext.create_dynamic_frame.from_catalog(
database = "{{database-name}}",
table_name = "{{table-name}}",
redshift_tmp_dir = args["TempDir"],
additional_options = {"sse_kms_key":"<{{KMS_KEY_ID}}>"},
transformation_ctx = "datasource0"
)
```
**Mendukung URL JDBC berbasis IAM**
Konektor baru mendukung URL JDBC berbasis IAM sehingga Anda tidak perlu memasukkan atau rahasia. user/password Dengan URL JDBC berbasis IAM, konektor menggunakan peran runtime pekerjaan untuk mengakses sumber data Amazon Redshift.
Langkah 1: Lampirkan kebijakan minimal yang diperlukan berikut ke peran runtime AWS Glue pekerjaan Anda.
------
#### [ JSON ]
****
```
{
"Version":"2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "redshift:GetClusterCredentials",
"Resource": [
"arn:aws:redshift:{{us-east-1}}:{{111122223333}}:dbgroup:/*",
"arn:aws:redshift:*:{{111122223333}}:dbuser:*/*",
"arn:aws:redshift:{{us-east-1}}:{{111122223333}}:dbname:/"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "redshift:DescribeClusters",
"Resource": "*"
}
]
}
```
------
Langkah 2: Gunakan URL JDBC berbasis IAM sebagai berikut. Tentukan opsi baru `DbUser` dengan nama pengguna Amazon Redshift yang terhubung dengan Anda.
```
conn_options = {
// IAM-based JDBC URL
"url": "jdbc:redshift:iam://{{}}:/",
"dbtable": dbtable,
"redshiftTmpDir": redshiftTmpDir,
"aws_iam_role": aws_iam_role,
"DbUser": "" // required for IAM-based JDBC URL
}
redshift_write = glueContext.write_dynamic_frame.from_options(
frame=dyf,
connection_type="redshift",
connection_options=conn_options
)
redshift_read = glueContext.create_dynamic_frame.from_options(
connection_type="redshift",
connection_options=conn_options
)
```
**catatan**
A `DynamicFrame` saat ini hanya mendukung URL JDBC berbasis IAM dengan a dalam ` DbUser` alur kerja. `GlueContext.create_dynamic_frame.from_options`
## Bermigrasi dari AWS Glue versi 3.0 ke versi 4.0
Di AWS Glue 4.0, pekerjaan ETL memiliki akses ke konektor Amazon Redshift Spark baru dan driver JDBC baru dengan opsi dan konfigurasi yang berbeda. Konektor dan driver Amazon Redshift baru ditulis dengan mempertimbangkan kinerja, dan menjaga konsistensi transaksional data Anda. Produk-produk ini didokumentasikan dalam dokumentasi Amazon Redshift. Untuk informasi lebih lanjut, lihat:
+ [Integrasi Amazon Redshift untuk Apache Spark](https://docs.aws.amazon.com/redshift/latest/mgmt/spark-redshift-connector.html)
+ [Driver Amazon Redshift JDBC, versi 2.1](https://docs.aws.amazon.com/redshift/latest/mgmt/jdbc20-download-driver.html)
**Pembatasan nama tabel/kolom dan pengidentifikasi**
Konektor dan driver Amazon Redshift Spark yang baru memiliki persyaratan yang lebih terbatas untuk nama tabel Redshift. Untuk informasi selengkapnya, lihat [Nama dan pengidentifikasi](https://docs.aws.amazon.com/redshift/latest/dg/r_names.html) untuk menentukan nama tabel Amazon Redshift Anda. Alur kerja bookmark pekerjaan mungkin tidak berfungsi dengan nama tabel yang tidak cocok dengan aturan dan karakter tertentu, seperti spasi.
Jika Anda memiliki tabel lama dengan nama yang tidak sesuai dengan aturan [Nama dan pengenal dan](https://docs.aws.amazon.com/redshift/latest/dg/r_names.html) melihat masalah dengan bookmark (pekerjaan memproses ulang data tabel Amazon Redshift lama), sebaiknya ganti nama nama tabel Anda. Untuk informasi selengkapnya, lihat [contoh ALTER TABLE](https://docs.aws.amazon.com/redshift/latest/dg/r_ALTER_TABLE_examples_basic.html).
**Perubahan tempformat default di Dataframe**
Konektor Spark AWS Glue versi 3.0 default `tempformat` ke CSV saat menulis ke Amazon Redshift. Agar konsisten, di AWS Glue versi 3.0, yang ` DynamicFrame` masih default untuk digunakan. `tempformat` `CSV` Jika sebelumnya Anda pernah menggunakan Spark Dataframe APIs secara langsung dengan konektor Amazon Redshift Spark, Anda dapat secara eksplisit menyetel ke CSV di opsi/. `tempformat` `DataframeReader` `Writer` Jika tidak, `tempformat` default ke konektor `AVRO` Spark baru.
**Perubahan perilaku: petakan tipe data Amazon Redshift REAL ke Spark tipe data FLOAT, bukan DOUBLE**
Di AWS Glue versi 3.0, Amazon Redshift `REAL` dikonversi ke tipe Spark` DOUBLE`. Konektor Amazon Redshift Spark yang baru telah memperbarui perilaku sehingga jenis Amazon Redshift dikonversi ke, dan kembali dari, ` REAL` tipe Spark. `FLOAT` Jika Anda memiliki kasus penggunaan lama di mana Anda masih ingin jenis Amazon `REAL` Redshift dipetakan ke tipe `DOUBLE` Spark, Anda dapat menggunakan solusi berikut:
+ Untuk a`DynamicFrame`, petakan `Float` tipe ke `Double` tipe dengan`DynamicFrame.ApplyMapping`. Untuk a`Dataframe`, Anda perlu menggunakan`cast`.
Contoh kode:
```
dyf_cast = dyf.apply_mapping([('a', 'long', 'a', 'long'), ('b', 'float', 'b', 'double')])
```
**Penanganan Jenis Data VARBYTE**
Saat bekerja dengan tipe data AWS Glue 3.0 dan Amazon Redshift, AWS Glue 3.0 mengonversi Amazon `VARBYTE` Redshift ke tipe Spark. `STRING` Namun, konektor Amazon Redshift Spark terbaru tidak mendukung tipe data. `VARBYTE` Untuk mengatasi batasan ini, Anda dapat [membuat tampilan Redshift](https://docs.aws.amazon.com/redshift/latest/dg/r_CREATE_VIEW.html) yang mengubah `VARBYTE` kolom menjadi tipe data yang didukung. Kemudian, gunakan konektor baru untuk memuat data dari tampilan ini alih-alih tabel asli, yang memastikan kompatibilitas sambil mempertahankan akses ke `VARBYTE` data Anda.
Contoh untuk kueri Redshift:
```
CREATE VIEW {{view_name}} AS SELECT FROM_VARBYTE({{varbyte_column}}, 'hex') FROM {{table_name}}
```