Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de la détection des discours toxiques
Utilisation de la détection des discours toxiques dans une transcription par lots
Pour utiliser la détection des discours toxiques avec une transcription par lots, consultez les exemples suivants :
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Tâches de transcription, puis sélectionnez Créer une tâche (en haut à droite). La page Spécifier les détails de la tâche s’ouvre.
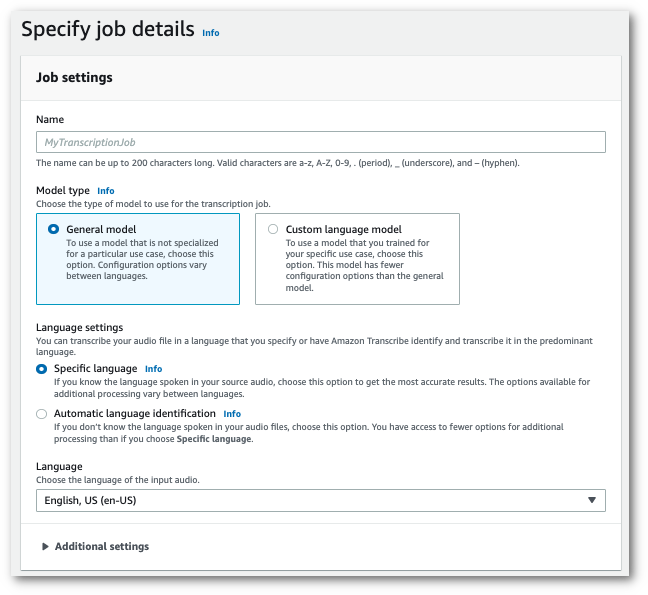
-
Sur la page Spécifier les détails de la tâche, vous pouvez également activer l’expurgation des données d’identification personnelle (PII) si vous le souhaitez. Notez que les autres options répertoriées ne sont pas prises en charge avec Toxicity Detection. Sélectionnez Suivant. Vous accédez alors à la page Configurer la tâche - facultatif. Dans le volet Paramètres audio, sélectionnez Toxicity Detection.
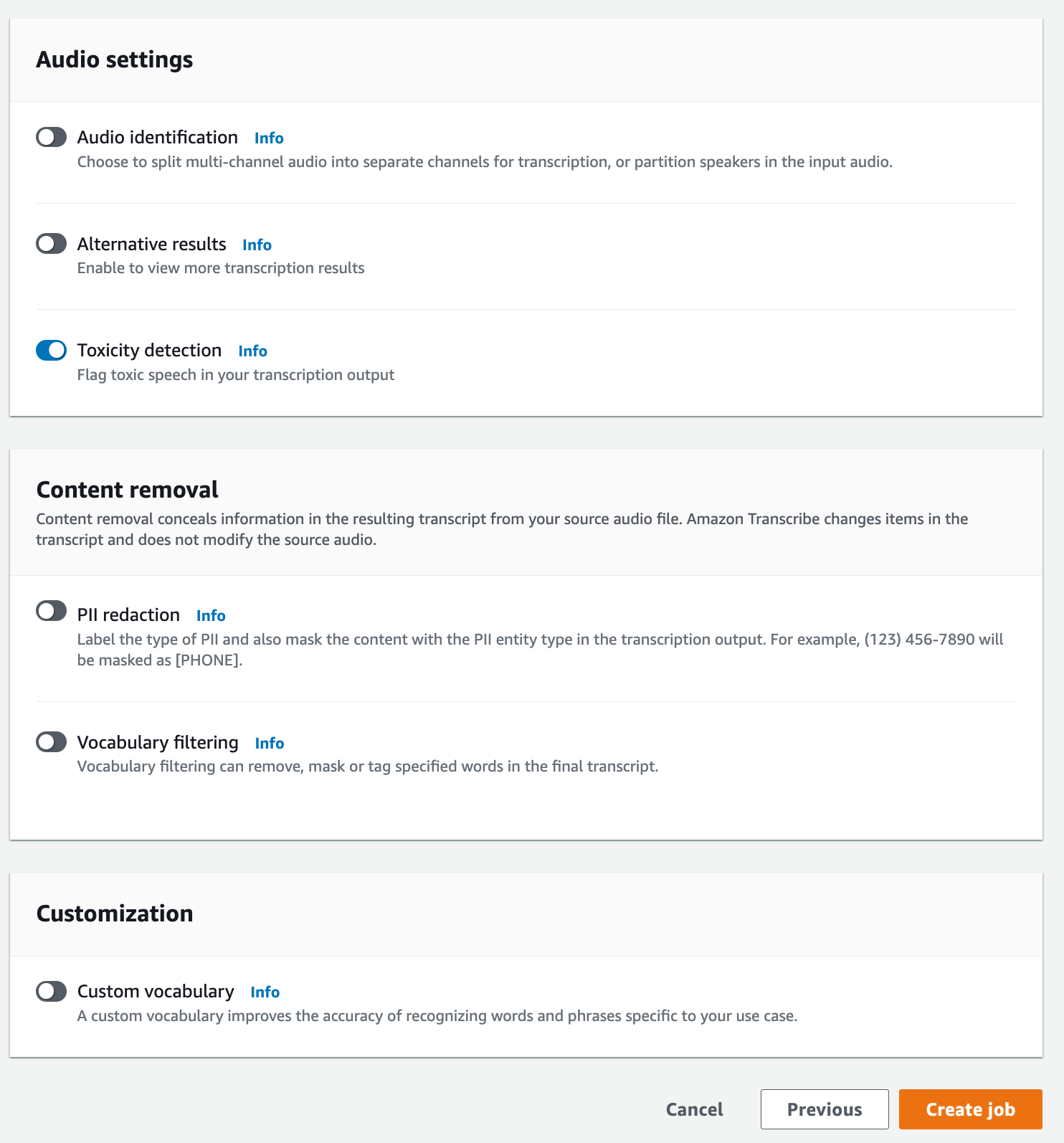
-
Sélectionnez Créer une tâche pour exécuter votre tâche de transcription.
-
Une fois votre tâche de transcription terminée, vous pouvez télécharger votre transcription depuis le menu déroulant Télécharger de la page détaillée de la tâche de transcription.
Cet exemple utilise la commande start-transcription-jobToxicityDetection. Pour plus d’informations, consultez StartTranscriptionJob et ToxicityDetection.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/\ --language-code en-US \ --toxicity-detection ToxicityCategories=ALL
Voici un autre exemple utilisant la commande start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-jsonfile://filepath/my-first-toxicity-job.json
Le fichier my-first-toxicity-job.json contient le corps de requête suivant.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ToxicityDetection": [ { "ToxicityCategories": [ "ALL" ] } ] }
Cet exemple utilise le AWS SDK pour Python (Boto3) to enable ToxicityDetection pour la méthode start_transcription_jobStartTranscriptionJob et ToxicityDetection.
Pour d'autres exemples d'utilisation AWS des SDK, notamment des exemples spécifiques aux fonctionnalités, des scénarios et des exemples multiservices, reportez-vous au chapitre. Exemples de code pour Amazon Transcribe à l'aide de AWS Kits SDK
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ToxicityDetection = [ { 'ToxicityCategories': ['ALL'] } ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Exemple de sortie
Le discours toxique est balisé et classé dans votre sortie de transcription. Chaque instance de discours toxique est classée et se voit attribuée un score de confiance (une valeur comprise entre 0 et 1). Une valeur de confiance plus élevée indique une plus grande probabilité que le contenu soit un discours toxique au sein de la catégorie spécifiée.
Voici un exemple de sortie au format JSON illustrant un discours toxique classé avec des scores de confiance associés.
{ "jobName": "my-toxicity-job", "accountId": "111122223333", "results": { "transcripts": [...], "items":[...], "toxicity_detection": [ { "text": "What the * are you doing man? That's why I didn't want to play with your * . man it was a no, no I'm not calming down * man. I well I spent I spent too much * money on this game.", "toxicity": 0.7638, "categories": { "profanity": 0.9913, "hate_speech": 0.0382, "sexual": 0.0016, "insult": 0.6572, "violence_or_threat": 0.0024, "graphic": 0.0013, "harassment_or_abuse": 0.0249 }, "start_time": 8.92, "end_time": 21.45 }, Items removed for brevity { "text": "What? Who? What the * did you just say to me? What's your address? What is your * address? I will pull up right now on your * * man. Take your * back to , tired of this **.", "toxicity": 0.9816, "categories": { "profanity": 0.9865, "hate_speech": 0.9123, "sexual": 0.0037, "insult": 0.5447, "violence_or_threat": 0.5078, "graphic": 0.0037, "harassment_or_abuse": 0.0613 }, "start_time": 43.459, "end_time": 54.639 }, ] }, ... "status": "COMPLETED" }
