Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Améliorations de l'initialisation de la communication collective
NCCL et Gloo sont des bibliothèques de communication fondamentales qui permettent des opérations collectives (telles que la réduction complète et la diffusion) dans le cadre de processus de formation distribués. Cependant, l'initialisation traditionnelle de NCCL et de Gloo peut créer des goulots d'étranglement lors de la restauration des défaillances.
Le processus de restauration standard exige que tous les processus soient connectés à un TCPStore centralisé et coordonnés par le biais d'un processus racine, ce qui entraîne une surcharge coûteuse qui devient particulièrement problématique lors des redémarrages. Cette conception centralisée crée trois problèmes critiques : la surcharge de coordination liée aux connexions TCPStore obligatoires, les délais de restauration, car chaque redémarrage doit répéter la séquence d'initialisation complète, et un point de défaillance unique dans le processus racine lui-même. Cela impose des étapes de coordination coûteuses et centralisées chaque fois que la formation est initialisée ou redémarrée.
HyperPod la formation sans point de contrôle élimine ces problèmes de coordination, permettant ainsi une reprise plus rapide en cas de panne en rendant l'initialisation « sans root » et « TCPStoreless ».
Configurations sans racines
Pour activer Rootless, il suffit d'exposer les variables d'environnement suivantes.
export HPCT_USE_ROOTLESS=1 && \ sysctl -w net.ipv4.ip_local_port_range="20000 65535" && \
HPCT_USE_ROOTLESS : 0 ou 1. À utiliser pour activer et désactiver Rootless
sysctl -w net.ipv4.ip_local_port_range="20000 65535" : définit la plage de ports du système
Consultez l'exemple
Sans racines
HyperPod checkpoint training propose de nouvelles méthodes d'initialisation, Rootless et TCPStoreless, pour les groupes de processus NCCL et Gloo.
La mise en œuvre de ces optimisations implique de modifier NCCL, Gloo et : PyTorch
Extension des API de bibliothèques tierces pour permettre les optimisations NCCL et Gloo sans rootless et Storeless tout en maintenant la rétrocompatibilité
Mettre à jour les backends des groupes de processus pour utiliser de manière conditionnelle des chemins optimisés et gérer les problèmes de restauration en cours de processus
Contourner la création coûteuse de TCPStore au niveau de la couche PyTorch distribuée tout en conservant des modèles d'adresses symétriques grâce à des compteurs de groupes globaux
Le graphique suivant montre l'architecture des bibliothèques de formation distribuées et les modifications apportées à la formation sans point de contrôle.
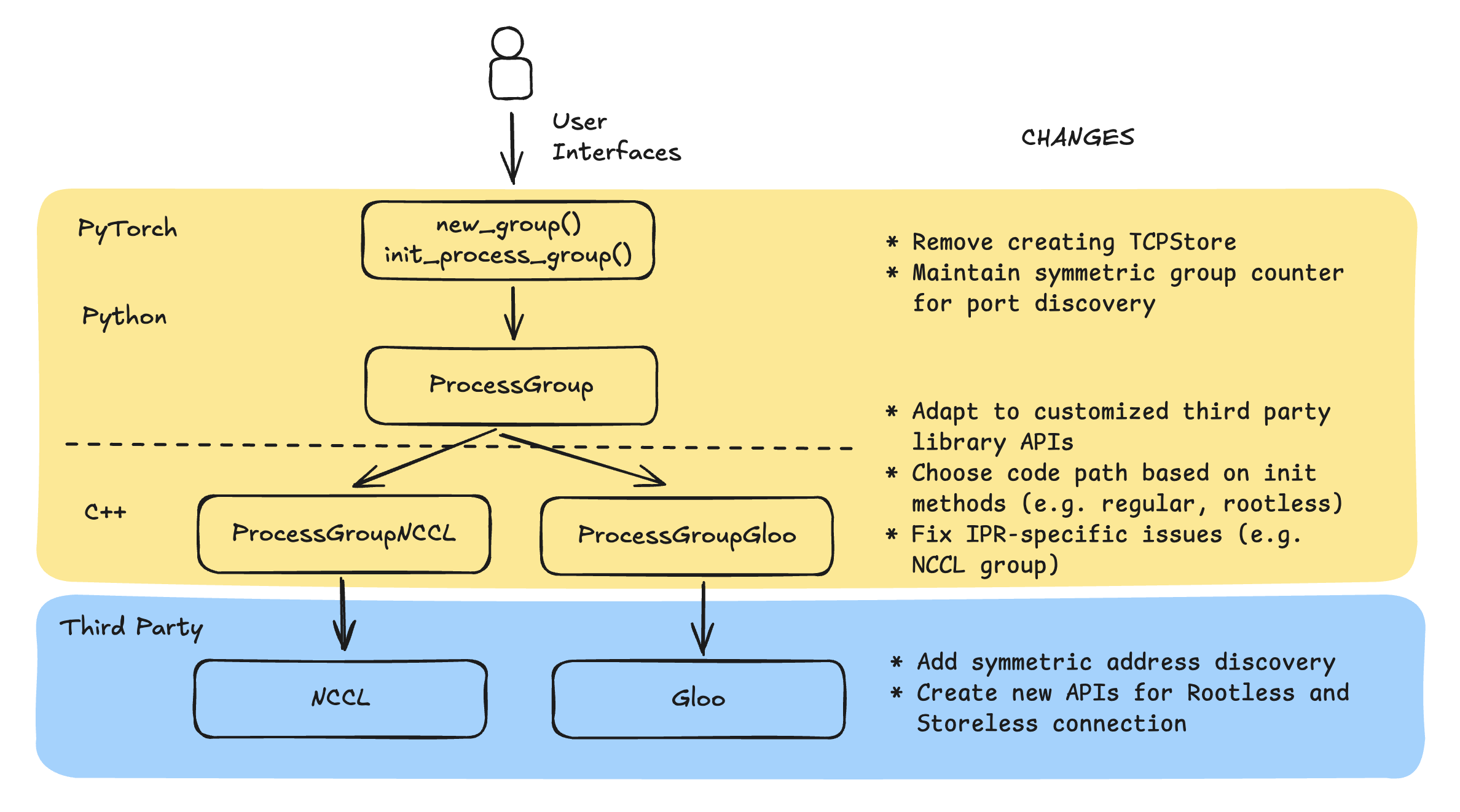
NCCL et Gloo
Il s'agit de packages indépendants qui exécutent les fonctionnalités de base des communications collectives. Ils fournissent des API clés, telles que ncclCommInitRank, pour initialiser les réseaux de communication, gérer les ressources sous-jacentes et effectuer des communications collectives. Après avoir apporté des modifications personnalisées dans NCCL et Gloo, Rootless et Storeless optimisent (par exemple, en évitant de se connecter au TCPStore) l'initialisation du réseau de communication. Vous pouvez alterner entre l'utilisation des chemins de code d'origine ou des chemins de code optimisés de manière flexible.
PyTorch backend de groupe de processus
Les backends du groupe de processus, en particulier ProcessGroup NCCL et NCCL ProcessGroupGloo, implémentent les ProcessGroup API en invoquant les API de leurs bibliothèques sous-jacentes correspondantes. Comme nous étendons les API des bibliothèques tierces, nous devons les invoquer correctement et effectuer des changements de chemin de code en fonction des configurations des clients.
Outre les chemins de code d'optimisation, nous modifions également le backend du groupe de processus pour prendre en charge la restauration en cours de processus.
