Amazon Redshift ne prendra plus en charge la création de nouveaux UDFs Python à partir du patch 198. Les fonctions Python définies par l’utilisateur existantes continueront de fonctionner normalement jusqu’au 30 juin 2026. Pour plus d’informations, consultez le billet de blog
Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Capacité de calcul pour Amazon Redshift sans serveur
Avec Amazon Redshift sans serveur, la capacité de calcul se met automatiquement à l’échelle pour répondre aux exigences de votre charge de travail. La capacité de calcul fait référence à la puissance de traitement et à la mémoire allouées à vos charges de travail Amazon Redshift sans serveur. Les cas d’utilisation courants incluent la gestion des périodes de pointe, l’exécution d’analyses complexes ou le traitement efficace de gros volumes de données. Les conditions suivantes fournissent des informations sur la manière dont Amazon Redshift gère la capacité de calcul.
RPU
Amazon Redshift sans serveur mesure la capacité de l’entrepôt des données en unités de traitement Redshift (RPU). Les RPU sont des ressources utilisées pour traiter les charges de travail. Une RPU fournit 16 Go de mémoire.
Capacité de base
Ce paramètre spécifie la capacité de l’entrepôt des données de base qu’Amazon Redshift utilise pour servir les requêtes. La capacité de base est spécifiée en RPU. Vous pouvez définir une capacité de base dans les unités de traitement Redshift (RPU). La définition d’une capacité de base plus élevée améliore les performances des requêtes, notamment pour les tâches de traitement des données qui exigent beaucoup de ressources. La capacité de base par défaut pour Amazon Redshift sans serveur est de 128 RPU. Vous pouvez régler le paramètre Capacité de base de 4 à 512 RPU. Vous pouvez définir cette valeur sur 4 RPU, ou en unités de 8 à 8 RPU ou plus (8, 16, 24... 512). Vous pouvez définir cette valeur à l'aide de la AWS console, de l'opération UpdateWorkgroup API ou de update-workgroup l'opération dans le AWS CLI.
Avec une capacité de base minimale de 8 RPU, vous disposez d’une certaine flexibilité pour exécuter des charges de travail plus simples ou plus complexes en fonction des coûts et des exigences de capacité de votre entrepôt de données. La capacité de base de 4 RPU est destinée aux entrepôts contenant moins de 32 To de données, et les capacités de base de 8, 16 et 24 RPU sont destinées aux charges de travail nécessitant moins de 128 To de données. Si vos besoins en données sont supérieurs à 128 To, vous devez utiliser un minimum de 32 RPU de base. Par ailleurs, pour les charges de travail comportant des tables avec un grand nombre de colonnes et une forte simultanéité, nous vous recommandons d’utiliser 32 RPU de base ou plus.
Les RPU de base maximum disponibles, 1 024, ajoutent le plus haut niveau de ressources informatiques à vos charges de travail. Cela offre une plus grande flexibilité pour prendre en charge des charges de travail très complexes et accélère le chargement et l’interrogation des données.
Note
Une capacité RPU de base maximale étendue de 1024 est disponible dans les versions suivantes Régions AWS. Dans les autres régions, la capacité de base maximale est de 512 RPU.
USA Est (Virginie du Nord)
USA Est (Ohio)
-
USA Ouest (Oregon)
-
Europe (Irlande)
-
Europe (Francfort)
Vous pouvez incrémenter ou décrémenter les RPU en unités de 32 lorsque vous définissez une capacité de base comprise entre 512 et 1 024 RPU.
Si vous gérez des charges de travail plus importantes et plus complexes, envisagez d’augmenter la taille de votre entrepôt de données Redshift sans serveur. Les grands entrepôts ont accès à davantage de ressources informatiques, ce qui leur permet de traiter les requêtes plus efficacement.
Voici quelques exemples dans lesquels il est avantageux de disposer d’une capacité de base plus élevée :
Vous avez des requêtes complexes dont l’exécution prend beaucoup de temps
Vos tableaux comportent un grand nombre de colonnes.
Vos requêtes comportent un nombre élevé de JOIN.
Vos requêtes regroupent ou analysent de grandes quantités de données provenant d’une source externe, telle qu’un lac de données.
Pour de plus amples informations sur les quotas et limites d’Amazon Redshift sans serveur, consultez Quotas pour les objets Amazon Redshift sans serveur.
Considérations et limitations relatives à la capacité d’Amazon Redshift sans serveur
Vous trouverez ci-après des considérations et des limitations concernant la capacité d’Amazon Redshift sans serveur. Pour les considérations générales relatives à Redshift sans serveur, consultez Considérations relatives à l’utilisation d’Amazon Redshift sans serveur.
-
Les configurations de 4 RPU de base prennent en charge une capacité de stockage allant jusqu’à 32 To. Si vous utilisez plus de 32 To de stockage géré, vous ne pouvez pas passer à moins de 8 RPU de base.
-
Les configurations de 8 ou 16 RPU de base prennent en charge une capacité de stockage gérée par Redshift allant jusqu’à 128 To. Si vous utilisez plus de 128 To de stockage géré, vous ne pouvez pas passer à moins de 32 RPU de base.
-
La modification de la capacité de base de votre groupe de travail peut annuler certaines requêtes exécutées sur votre groupe de travail.
Redshift sans serveur met à l’échelle les RPU pour votre entrepôt de données en utilisant les incréments suivants :
4 à 8 RPU : augmentation par paliers de 4 RPU.
8 à 512 RPU : augmentation par paliers de 8 RPU.
512 à 1 024 RPU : augmentation par paliers de 32 RPU.
-
Vacuum Boost n’est pris en charge que pour 8 RPU et plus. Pour 8 RPU ou moins, utilisez plutôt la commande suivante :
VACUUM [FULL | SORT ONLY | DELETE ONLY | REINDEX | RECLUSTER] [table_name] [TO threshold PERCENT]
Redshift sans serveur avec capacité de 4 unités de traitement Redshift (RPU)
Redshift sans serveur avec une capacité de 4 RPU de base est idéal pour les charges de travail plus petites ou moins exigeantes. Ce point d’entrée offre une solution flexible et rentable. Cette configuration d’entrée prend en charge les entrepôts de données dotés des ressources suivantes au maximum :
Jusqu’à 32 To de stockage géré par Redshift.
Un maximum de 100 colonnes par table
64 Go de mémoire
Si vous devez dépasser ces limites, vous devez augmenter votre capacité de base manuellement, plutôt que de vous fier à l’autoscaling. Une fois que vous aurez étendu votre entrepôt de données au-delà de 4 RPU, votre entrepôt de données continuera à utiliser davantage de RPU, et Amazon Redshift ne réduira pas votre entrepôt de données à 4 RPU.
Note
Vous pouvez créer des tables de plus de 100 colonnes lorsque vous utilisez 4 RPU de base, mais nous vous recommandons de limiter les tables à 100 colonnes. Le dépassement de cette limite peut entraîner l’épuisement de la mémoire de votre entrepôt de données lors de l’exécution des requêtes, ce qui réduit les performances.
Vous pouvez créer des entrepôts de données utilisant 4 RPU comme suit : Régions AWS
USA Est (Ohio)
USA Est (Virginie du Nord)
USA Ouest (Californie du Nord)
USA Ouest (Oregon)
Asie-Pacifique (Mumbai)
Asie-Pacifique (Singapour)
Asie-Pacifique (Sydney)
Asia Pacific (Tokyo)
Europe (Irlande)
Europe (Stockholm)
AI-driven mise à l'échelle et optimisation
La fonctionnalité de AI-driven dimensionnement et d'optimisation est disponible dans toutes les AWS régions où Amazon Redshift Serverless est disponible.
Amazon Redshift Serverless propose une fonctionnalité avancée de mise à AI-driven l'échelle et d'optimisation pour répondre aux diverses exigences en matière de charge de travail. Les entrepôts de données peuvent rencontrer les problèmes de provisionnement suivants :
Les entrepôts de données peuvent être suralloués pour améliorer les performances des requêtes gourmandes en ressources
Les entrepôts de données peuvent être sous-alloués pour réduire les coûts.
Il est difficile de trouver le juste équilibre entre performance et coût pour les charges de travail des entrepôts de données, en particulier en cas de requêtes ad hoc et de volumes de données croissants. Lorsque vous exécutez des charges de travail mixtes, comprenant à la fois des requêtes peu ou fortement gourmandes en ressources, une mise à l’échelle intelligente est nécessaire. La fonctionnalité de AI-driven dimensionnement et d'optimisation adapte automatiquement le calcul sans serveur ou les RPU en réponse à la croissance des données. Cette fonctionnalité permet également de maintenir les performances des requêtes dans le respect des objectifs de performance et de prix ciblés. La AI-driven mise à l'échelle et l'optimisation allouent dynamiquement les ressources de calcul à mesure que les volumes de données augmentent, garantissant ainsi que les requêtes continuent d'atteindre les objectifs de performance. AI-driven la mise à l'échelle et l'optimisation permettent au service de s'adapter facilement à l'évolution des exigences en matière de charge de travail, sans intervention manuelle ni planification complexe des capacités.
Amazon Redshift sans serveur fournit une solution de mise à l’échelle plus complète et plus réactive basée sur des facteurs tels que la complexité des requêtes et le volume de données. Cette fonctionnalité permet d’optimiser le rapport prix/performances des charges de travail tout en conservant la flexibilité nécessaire pour gérer efficacement des charges de travail variables et des jeux de données croissants. Amazon Redshift Serverless peut automatiquement AI-driven optimiser votre point de terminaison Amazon Redshift Serverless afin d'atteindre les objectifs de prix/performances que vous avez spécifiés pour votre groupe de travail sans serveur. Cette optimisation automatique du rapport prix/performances est particulièrement utile si vous ne savez pas quelle capacité de base définir pour vos charges de travail, ou si certaines parties de votre charge de travail peuvent profiter d’un plus grand nombre de ressources allouées.
Exemple
Si votre organisation exécute des charges de travail qui nécessitent uniquement 32 RPU mais qu’elle introduit soudainement une requête plus complexe, vous ne connaissez peut-être pas la capacité de base approprié. La définition d’une capacité de base plus élevée permet d’obtenir de meilleures performances, mais elle entraîne également des coûts plus élevés, de sorte que le coût risque de ne pas correspondre à vos attentes. Grâce AI-driven à la mise à l'échelle et à l'optimisation des ressources, Amazon Redshift Serverless ajuste automatiquement les RPU pour atteindre vos objectifs de prix/performances tout en optimisant les coûts pour votre entreprise. Cette optimisation automatique est utile quelle que soit la taille de la charge de travail. L’optimisation automatique peut vous aider à atteindre les rapports prix/performances cible de votre organisation en cas de requêtes complexes.
Note
Price-performance les cibles sont un paramètre spécifique au groupe de travail. Les différents groupes de travail peuvent avoir des rapports prix/performances cible différents.
Pour que les coûts restent prévisibles, définissez une limite de capacité maximale qu’Amazon Redshift sans serveur est autorisé à allouer à vos charges de travail.
Pour configurer les objectifs de rapport prix/performances, utilisez la AWS console. L'objectif prix-performance est activé par défaut pour tous les nouveaux groupes de travail sans serveur et est défini sur Équilibré. Vous pouvez modifier l'objectif de prix/performances après avoir créé le groupe de travail Serverless.
Pour modifier l’objectif prix/performances pour votre groupe de travail
Dans la console Amazon Redshift sans serveur, choisissez Configuration de groupe de travail.
Choisissez le groupe de travail pour lequel vous souhaitez modifier le rapport prix/performances cible. Choisissez l’onglet Performances, puis choisissez Modifier.
Choisissez Price-performancela cible et réglez le curseur selon le réglage souhaité.
Sélectionnez Enregistrer les modifications.
Pour mettre à jour le nombre maximal de RPU qu’Amazon Redshift sans serveur peut allouer à votre charge de travail, choisissez l’onglet Limites de la section Configuration du groupe de travail.
Vous pouvez utiliser le curseur Price-performance cible pour définir l'équilibre souhaité entre le coût et les performances. En déplaçant le curseur, vous pouvez choisir l’une des options suivantes :
Optimisation pour les coûts : ce paramètre donne la priorité aux économies de coûts. Amazon Redshift sans serveur tente d’augmenter automatiquement la capacité de calcul lorsque cela n’entraîne pas de frais supplémentaires. Amazon Redshift sans serveur tente également de réduire les ressources de calcul à moindre coût, ce qui peut augmenter le temps d’exécution des requêtes.
Équilibré : ce paramètre crée un équilibre entre les performances et les coûts. Amazon Redshift sans serveur met à l’échelle en fonction des performances et peut entraîner une augmentation ou une diminution modérée des coûts. Il s’agit du paramètre recommandé pour la plupart des entrepôts de données Amazon Redshift sans serveur.
Optimisation pour les performances : ce paramètre donne la priorité aux performances. Amazon Redshift met à l’échelle de manière agressive pour atteindre des performances élevées, ce qui peut entraîner des coûts plus élevés.
Positions intermédiaires : vous pouvez également placer le curseur sur l’une des deux positions intermédiaires entre Équilibré et Optimisation pour les coûts ou Optimisation pour les performances. Utilisez ces paramètres si l’optimisation complète pour les coûts ou de performances est trop extrême.
Considérations lors du choix de votre objectif prix/performances
Vous pouvez utiliser le curseur de prix/performance pour choisir l’objectif prix/performance souhaité pour votre charge de travail. L'algorithme de AI-driven dimensionnement et d'optimisation apprend au fil du temps à partir de l'historique de votre charge de travail et améliore la précision des prévisions et des décisions.
Exemple
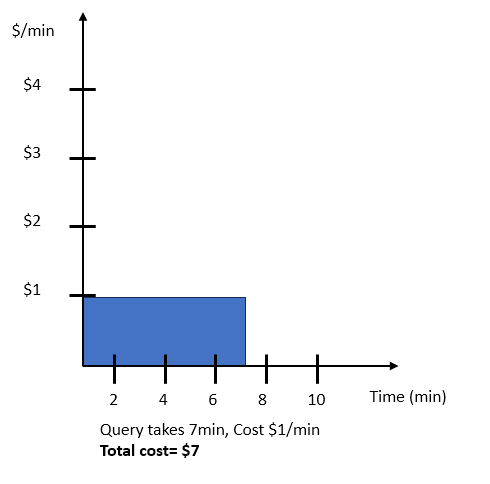
Pour cet exemple, supposons une requête qui prend sept minutes et coûte 7 $. La figure suivante montre les temps d’exécution et le coût des requêtes sans mise à l’échelle.
Une requête donnée peut être mise à l’échelle de différentes manières, comme indiqué ci-dessous. En fonction de l'objectif prix/performance que vous avez choisi, le AI-driven dimensionnement prédit la manière dont la requête équilibre les performances et les coûts, et l'adapte en conséquence. Le choix des différentes options du curseur donne les résultats suivants :
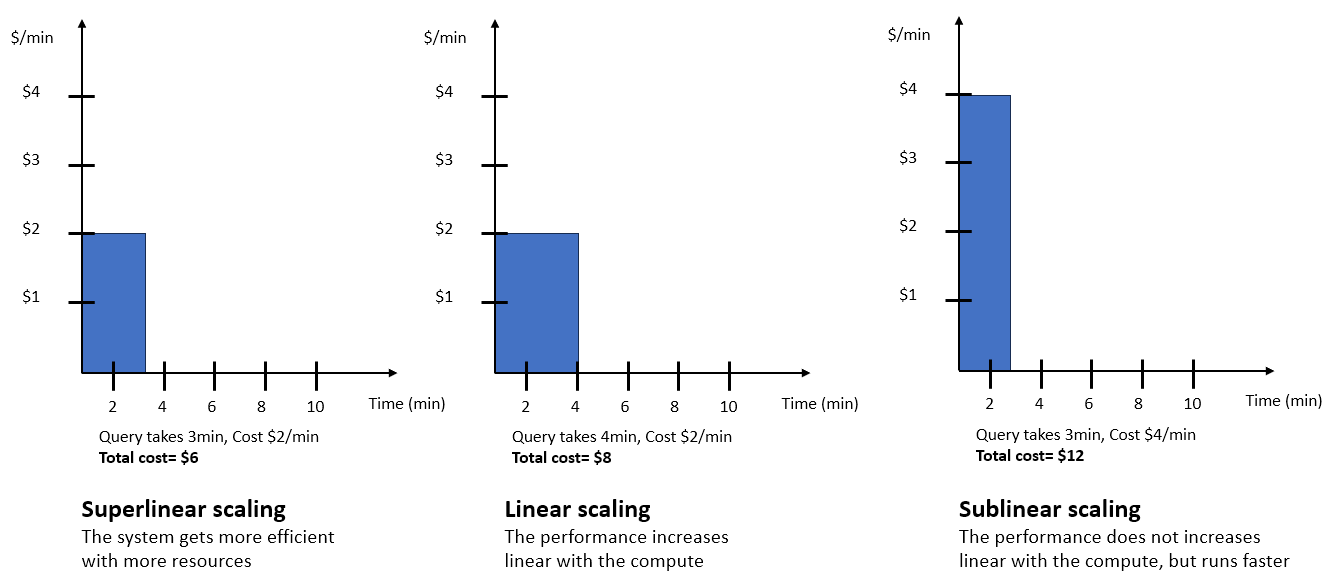
Optimisation pour les coûts : avec l’option Optimisation pour les coûts, votre entrepôt de données évolue en privilégiant les choix qui réduisent vos coûts. Dans l’exemple précédent, l’approche de mise à l’échelle super linéaire montre ce comportement. La mise à l’échelle n’aura lieu que si elle peut être réalisée de manière rentable conformément aux prédictions modélisées de mise à l’échelle. Si les modèles de mise à l’échelle prédisent qu’une mise à l’échelle optimisée pour les coûts n’est pas possible pour une charge de travail donnée, l’entrepôt de données ne sera pas évolutif.
Équilibré : avec l’option Équilibré, le système met à l’échelle tout en équilibrant les considérations de coût et de performance, avec une augmentation potentielle limitée des coûts. L’option Équilibré effectue une mise à l’échelle de la charge de travail superlinéaire, linéaire et éventuellement sublinéaire.
Optimisation pour les performances : avec l’option Optimisation pour les performances, outre les méthodes précédentes d’amélioration des performances, le système met à l’échelle même si les coûts sont plus élevés, et ce n’est peut-être pas proportionnel à l’amélioration du temps d’exécution. Avec Optimisation pour les performances, le système effectue une mise à l’échelle superlinéaire, une mise à l’échelle linéaire et une mise à l’échelle sublinéaire si possible. Plus la position du curseur est proche de la position Optimisation pour les performances, plus Amazon Redshift sans serveur autorise le mise à l’échelle sublinéaire.
Lorsque vous réglez le Price-Performancecurseur, tenez compte des points suivants :
Vous pouvez modifier le paramètre de prix/performances à tout moment, mais le mise à l’échelle de la charge de travail ne changera pas immédiatement. La mise à l’échelle change au fil du temps à mesure que le système prend connaissance de la charge de travail actuelle. Nous vous conseillons de surveiller un groupe de travail sans serveur pendant 1 à 3 jours afin de vérifier l’impact du nouveau paramètre.
Les options du curseur prix/performance Max capacity et Max fonctionnent ensemble. RPU-hours La capacité maximale et la valeur maximale RPU-hours sont les commandes permettant de limiter les RPU maximales qu'Amazon Redshift Serverless permet à l'entrepôt de données de faire évoluer, ainsi que le nombre maximum d'heures de RPU qu'Amazon Redshift Serverless permet à l'entrepôt de données de consommer. Amazon Redshift sans serveur respecte et applique toujours ces paramètres, quel que soit l’objectif prix/performances fixé.
Surveillance de l’autoscaling des ressources
Vous pouvez surveiller la mise à l'échelle du AI-driven RPU de différentes manières :
Consultez le graphique de capacité RPU utilisée sur la console Amazon Redshift.
Surveillez la
ComputeCapacitymétrique en dessousAWS/Redshift-ServerlessetWorkgroupen aval CloudWatch.Interrogez la vue SYS_QUERY_HISTORY. Fournissez l’ID de requête ou le texte de la requête spécifique pour identifier la période. Utilisez cette période pour interroger la vue système SYS_SERVERLESS_USAGE afin de trouver la valeur
compute_capacity. Le champcompute_capacityindique les RPU redimensionnées pendant l’exécution de la requête.
Utilisez l’exemple suivant pour interroger la vue SYS_QUERY_HISTORY. Remplacez les exemples de valeur par le texte de votre requête.
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds from sys_query_history where query_text like '<query_text>' and query_text not like '%sys_query_history%' order by start_time desc
Exécutez la requête suivante pour voir comment compute_capacity a été mise à l’échelle au cours de la période allant de start_time à end_time. Remplacez start_time et end_time dans la requête suivante par le résultat de la requête précédente :
select * from sys_serverless_usage where end_time >= 'start_time' and end_time <= DATEADD(minute,1,'end_time') order by end_time asc
Pour obtenir des instructions détaillées sur l’utilisation de ces fonctionnalités, consultez Configurer la surveillance, les limites et les alarmes dans Amazon Redshift sans serveur afin de garantir la prévisibilité des coûts
Considérations relatives à l'utilisation du AI-driven dimensionnement et de l'optimisation
Lorsque vous utilisez la mise à l' AI-driven échelle et l'optimisation, tenez compte des points suivants :
Pour les charges de travail existantes sur Amazon Redshift Serverless nécessitant 8 à 512 RPU de base, nous recommandons d'utiliser le dimensionnement et l'optimisation Amazon Redshift AI-driven Serverless pour des résultats optimaux. Nous déconseillons d'utiliser cette fonctionnalité pour des charges de travail de 4 RPU de base ou plus de 512 RPU de base.
Price-performance les cibles optimisent automatiquement la charge de travail, même si les résultats peuvent varier. Nous recommandons d’utiliser cette fonctionnalité au fil du temps afin que le système puisse apprendre vos modèles spécifiques en exécutant une charge de travail représentative.
AI-driven le dimensionnement et l'optimisation utilisent des moments optimaux pour appliquer des optimisations aux groupes de travail sans serveur en fonction de la charge de travail exécutée sur votre instance Amazon Redshift Serverless.
Pour en savoir plus sur les AI-driven optimisations et le dimensionnement des ressources, regardez la vidéo suivante.
