Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
# Migrer une base de données Oracle sur site vers Amazon RDS for Oracle à l'aide d'Oracle Data Pump
*Mohan Annam et Brian Motzer, Amazon Web Services*
## Résumé
Ce modèle décrit comment migrer une base de données Oracle d'un centre de données sur site vers une instance de base de données Amazon Relational Database Service (Amazon RDS) pour Oracle à l'aide d'Oracle Data Pump.
Le modèle implique la création d'un fichier de vidage de données à partir de la base de données source, le stockage du fichier dans un bucket Amazon Simple Storage Service (Amazon S3), puis la restauration des données sur une instance de base de données Amazon RDS for Oracle. Ce modèle est utile lorsque vous rencontrez des difficultés lors de l'utilisation d'AWS Database Migration Service (AWS DMS) pour la migration.
## Conditions préalables et limitations
**Conditions préalables**
+ Un compte AWS actif
+ Les autorisations requises pour créer des rôles dans AWS Identity and Access Management (IAM) et pour un téléchargement partitionné sur Amazon S3
+ Les autorisations requises pour exporter des données depuis la base de données source
+ [Interface de ligne de commande (AWS CLI) (AWS CLI[)](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) installée et configurée](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html)
**Versions du produit**
+ Oracle Data Pump est uniquement disponible pour Oracle Database 10g version 1 (10.1) et versions ultérieures.
## Architecture
**Pile technologique source**
+ Bases de données Oracle sur site
**Pile technologique cible**
+ Amazon RDS for Oracle
+ Client SQL (développeur Oracle SQL)
+ Compartiment S3
**Architecture source et cible**
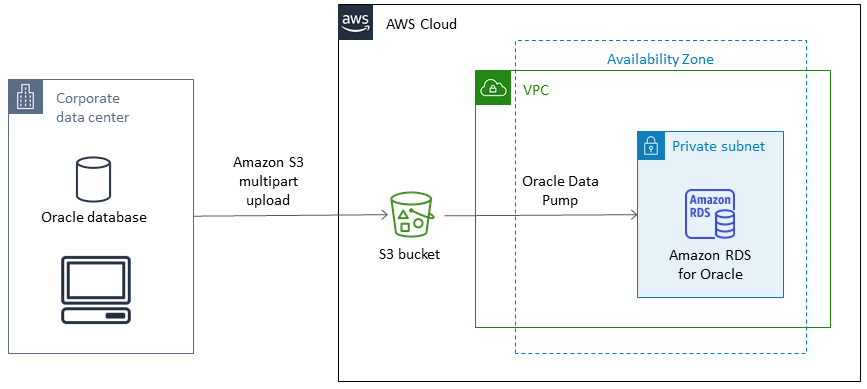
## Outils
**Services AWS**
+ [AWS Identity and Access Management (IAM)](https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html) vous aide à gérer en toute sécurité l'accès à vos ressources AWS en contrôlant qui est authentifié et autorisé à les utiliser. Dans ce modèle, IAM est utilisé pour créer les rôles et les politiques nécessaires à la migration des données d'Amazon S3 vers Amazon RDS for Oracle.
+ [Amazon Relational Database Service (Amazon RDS) pour](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Oracle.html) Oracle vous aide à configurer, exploiter et dimensionner une base de données relationnelle Oracle dans le cloud AWS.
+ [Amazon Simple Storage Service (Amazon S3)](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html) est un service de stockage d'objets basé sur le cloud qui vous permet de stocker, de protéger et de récupérer n'importe quel volume de données.
**Autres outils**
+ [Oracle Data Pump](https://docs.oracle.com/cd/B19306_01/server.102/b14215/dp_overview.htm) vous aide à déplacer des données et des métadonnées d'une base de données à une autre à grande vitesse. Dans ce modèle, Oracle Data Pump est utilisé pour exporter le fichier de vidage de données (.dmp) vers le serveur Oracle et pour l'importer dans Amazon RDS for Oracle. Pour plus d'informations, consultez la section [Importation de données dans Oracle sur Amazon RDS](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Oracle.Procedural.Importing.html#Oracle.Procedural.Importing.DataPump.S3) dans la documentation Amazon RDS.
+ [Oracle SQL Developer](https://www.oracle.com/database/technologies/appdev/sqldeveloper-landing.html) est un environnement de développement intégré qui simplifie le développement et la gestion des bases de données Oracle dans les déploiements traditionnels et basés sur le cloud. Il interagit à la fois avec la base de données Oracle sur site et avec Amazon RDS for Oracle pour exécuter les commandes SQL nécessaires à l'exportation et à l'importation de données.
## Épopées
### Création d’un compartiment S3
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Créer le compartiment. | Pour créer le compartiment S3, suivez les instructions de la [documentation AWS](https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html). | Administrateur système AWS |
### Création du rôle IAM et attribution de politiques
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Configurez les autorisations IAM. | Pour configurer les autorisations, suivez les instructions de la [documentation AWS](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/oracle-s3-integration.html#oracle-s3-integration.preparing). | Administrateur système AWS |
### Créez l'instance de base de données Amazon RDS for Oracle cible et associez le rôle d'intégration Amazon S3
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Créez l'instance de base de données Amazon RDS for Oracle cible. | Pour créer l'instance Amazon RDS for Oracle, suivez les instructions de la documentation [AWS](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_GettingStarted.CreatingConnecting.Oracle.html). | Administrateur système AWS |
| Associez le rôle à l'instance de base de données. | Pour associer le rôle à l'instance, suivez les instructions de la [documentation AWS](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/oracle-s3-integration.html#oracle-s3-integration.preparing.instance). | DBA |
### Création de l'utilisateur de base de données sur la base de données cible
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Créez l’utilisateur. | Connectez-vous à la base de données Amazon RDS for Oracle cible depuis Oracle SQL Developer ou SQL\*Plus, puis exécutez la commande SQL suivante pour créer l'utilisateur dans lequel importer le schéma.create user SAMPLE_SCHEMA identified by ;
grant create session, resource to ;
alter user quota 100M on users;
| DBA |
### Créez le fichier d'exportation à partir de la base de données Oracle source
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Créez un fichier de vidage de données. | Pour créer un fichier de vidage nommé `sample.dmp` dans le `DATA_PUMP_DIR` répertoire d'exportation de l'`SAMPLE_SCHEMA`utilisateur, utilisez le script suivant.DECLARE
hdnl NUMBER;
BEGIN
hdnl := dbms_datapump.open(operation => 'EXPORT',
job_mode => 'SCHEMA',
job_name => NULL);
dbms_datapump.add_file( handle => hdnl,
filename => 'sample.dmp',
directory => 'DATA_PUMP_DIR',
filetype => dbms_datapump.ku$_file_type_dump_file);
dbms_datapump.add_file(handle => hdnl,
filename => 'export.log',
directory => 'DATA_PUMP_DIR',
filetype => dbms_datapump.ku$_file_type_log_file);
dbms_datapump.metadata_filter(hdnl, 'SCHEMA_EXPR', 'IN (''SAMPLE_SCHEMA'')');
dbms_datapump.start_job(hdnl);
END;
/
Vérifiez les détails de l'exportation en consultant le `export.log` fichier dans votre `DATA_PUMP_DIR` répertoire local. | DBA |
### Téléchargez le fichier de vidage dans le compartiment S3
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Téléchargez le fichier de vidage de données de la source vers le compartiment S3. | À l'aide de l'AWS CLI, exécutez la commande suivante.aws s3 cp sample.dmp s3:///
| DBA |
### Téléchargez le fichier d'exportation depuis le compartiment S3 vers l'instance RDS
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Téléchargez le fichier de vidage de données sur Amazon RDS | Pour copier le fichier `sample.dmp` de vidage du compartiment S3 vers la base de données Amazon RDS for Oracle, exécutez la commande SQL suivante. Dans cet exemple, le `sample.dmp` fichier est téléchargé depuis le compartiment S3 `my-s3-integration1` vers le répertoire Oracle`DATA_PUMP_DIR`. Assurez-vous que l'espace disque alloué à votre instance RDS est suffisant pour accueillir à la fois la base de données et le fichier d'exportation.-- If you want to download all the files in the S3 bucket remove the p_s3_prefix line.
SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3(
p_bucket_name => 'my-s3-integration',
p_s3_prefix => 'sample.dmp',
p_directory_name => 'DATA_PUMP_DIR')
AS TASK_ID FROM DUAL;
La commande précédente génère un identifiant de tâche. Pour vérifier l'état du téléchargement en consultant les données contenues dans l'ID de tâche, exécutez la commande suivante.SELECT text FROM table(rdsadmin.rds_file_util.read_text_file('BDUMP','dbtask-.log'));
Pour voir les fichiers du `DATA_PUMP_DIR` répertoire, exécutez la commande suivante.SELECT filename,type,filesize/1024/1024 size_megs,to_char(mtime,'DD-MON-YY HH24:MI:SS') timestamp
FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => upper('DATA_PUMP_DIR'))) order by 4;
| Administrateur système AWS |
### Importez le fichier de vidage dans la base de données cible
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Restaurez le schéma et les données sur Amazon RDS. | Pour importer le fichier de vidage dans le schéma `sample_schema` de base de données, exécutez la commande SQL suivante depuis SQL Developer ou SQL\*Plus.DECLARE
hdnl NUMBER;
BEGIN
hdnl := DBMS_DATAPUMP.OPEN( operation => 'IMPORT', job_mode => 'SCHEMA', job_name=>null);
DBMS_DATAPUMP.ADD_FILE( handle => hdnl, filename => 'sample.dmp', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_dump_file);
DBMS_DATAPUMP.ADD_FILE( handle => hdnl, filename => 'import.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file);
DBMS_DATAPUMP.METADATA_FILTER(hdnl,'SCHEMA_EXPR','IN (''SAMPLE_SCHEMA'')');
DBMS_DATAPUMP.START_JOB(hdnl);
END;
/
Pour consulter le fichier journal de l'importation, exécutez la commande suivante.SELECT text FROM table(rdsadmin.rds_file_util.read_text_file('DATA_PUMP_DIR','import.log')); | DBA |
### Supprimez le fichier de vidage du répertoire DATA\_PUMP\_DIR
| Sous-tâche | Description | Compétences requises |
| --- | --- | --- |
| Répertoriez et nettoyez les fichiers d'exportation. | Répertoriez et supprimez les fichiers d'exportation dans le `DATA_PUMP_DIR` répertoire, exécutez les commandes suivantes.-- List the files
SELECT filename,type,filesize/1024/1024 size_megs,to_char(mtime,'DD-MON-YY HH24:MI:SS') timestamp FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => upper('DATA_PUMP_DIR'))) order by 4;
-- Remove the files
EXEC UTL_FILE.FREMOVE('DATA_PUMP_DIR','sample.dmp');
EXEC UTL_FILE.FREMOVE('DATA_PUMP_DIR','import.log');
| Administrateur système AWS |
## Ressources connexes
+ [Intégration avec Amazon S3](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/oracle-s3-integration.html#oracle-s3-integration.preparing)
+ [Création d'une instance de base de données](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Tutorials.WebServerDB.CreateDBInstance.html)
+ [Importation de données dans Oracle sur Amazon RDS](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Oracle.Procedural.Importing.html#Oracle.Procedural.Importing.DataPump.S3)
+ [Documentation Amazon S3](https://docs.aws.amazon.com/s3/index.html)
+ [Documentation IAM](https://docs.aws.amazon.com/iam/index.html)
+ [Documentation Amazon RDS](https://docs.aws.amazon.com/rds/index.html)
+ [Documentation Oracle Data Pump](https://docs.oracle.com/en/database/oracle/oracle-database/19/sutil/oracle-data-pump-overview.html)
+ [Oracle SQL Developer](https://www.oracle.com/database/sqldeveloper/)