Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Automatisez le déploiement des lacs de Chaîne d'approvisionnement données dans une configuration à référentiels multiples
Keshav Ganesh, Amazon Web Services
Résumé
Ce modèle fournit une approche automatisée pour le déploiement et la gestion des lacs de AWS Supply Chain données à l'aide d'une intégration continue multi-référentiels et de fonctionnalités de déploiement continu (CI/CD) pipeline. It demonstrates two deployment methods: automated deployment using GitHub Actions workflows, or manual deployment using Terraform directly. Both approaches use Terraform for infrastructure as code (IaC), with the automated method adding GitHub Actions and JFrog Artifactory for enhanced CI/CDfonctionnalités).
La solution s'appuie sur Chaîne d'approvisionnement Amazon Simple Storage Service (Amazon S3) pour établir l'infrastructure du lac de données, tout en utilisant l'une ou l'autre des méthodes de déploiement pour automatiser la configuration et la création de ressources. AWS Lambda Cette automatisation élimine les étapes de configuration manuelles et garantit des déploiements cohérents dans tous les environnements. En outre, il Chaîne d'approvisionnement élimine le besoin d'une expertise approfondie en matière d'extraction, de transformation et de chargement (ETL) et peut fournir des informations et des analyses basées sur Amazon Quick Sight.
En mettant en œuvre ce modèle, les entreprises peuvent réduire le temps de déploiement, maintenir l'infrastructure sous forme de code et gérer les lacs de données de la chaîne d'approvisionnement grâce à un processus automatisé contrôlé par version. L'approche multi-référentiels fournit un contrôle d'accès précis et permet le déploiement indépendant de différents composants. Les équipes peuvent choisir la méthode de déploiement la mieux adaptée à leurs outils et processus existants.
Conditions préalables et limitations
Conditions préalables
Assurez-vous que les éléments suivants sont installés sur votre ordinateur local :
AWS Command Line Interface (AWS CLI) version 2
Terraform
v1.12 ou version ultérieure
Assurez-vous que les éléments suivants sont en place avant le déploiement :
Un actif Compte AWS.
Un cloud privé virtuel (VPC) avec deux sous-réseaux privés Compte AWS dans l'espace Région AWS de votre choix.
Autorisations suffisantes pour le rôle Gestion des identités et des accès AWS (IAM) utilisé pour le déploiement vers les services suivants :
Chaîne d'approvisionnement — L'accès complet est préféré pour déployer ses composants tels que les ensembles de données et les flux d'intégration, ainsi que pour y accéder depuis le AWS Management Console.
Amazon CloudWatch Logs : pour créer et gérer des groupes de CloudWatch journaux.
Amazon Elastic Compute Cloud (Amazon EC2) — Pour les groupes de sécurité Amazon EC2 et les points de terminaison Amazon Virtual Private Cloud (Amazon VPC).
Amazon EventBridge — À utiliser par Chaîne d'approvisionnement.
IAM — Pour créer des rôles AWS Lambda de service.
AWS Key Management Service (AWS KMS) — Pour accéder au compartiment d'artefacts AWS KMS keys utilisé pour le compartiment d'artefacts Amazon S3 et le compartiment Chaîne d'approvisionnement intermédiaire Amazon S3.
AWS Lambda — Pour créer les fonctions Lambda qui déploient les Chaîne d'approvisionnement composants.
Amazon S3 — Pour accéder au compartiment d'artefacts Amazon S3, au compartiment de journalisation des accès au serveur et au Chaîne d'approvisionnement compartiment intermédiaire. Si vous utilisez le déploiement manuel, les autorisations pour le compartiment d'artefacts Amazon S3 Terraform sont également requises.
Amazon VPC — Pour créer et gérer un VPC.
Si vous préférez utiliser les flux de travail GitHub Actions pour le déploiement, procédez comme suit :
Configurez OpenID Connect (OIDC)
pour le rôle IAM avec les autorisations mentionnées précédemment. Créez un rôle IAM avec des autorisations similaires pour accéder au AWS Management Console. Pour plus d'informations, consultez la section Créer un rôle pour accorder des autorisations à un utilisateur IAM dans la documentation IAM.
Si vous préférez effectuer un déploiement manuel, procédez comme suit :
Créez un utilisateur IAM pour assumer le rôle IAM avec les autorisations mentionnées précédemment. Pour plus d'informations, consultez la section Créer un rôle pour accorder des autorisations à un utilisateur IAM dans la documentation IAM.
Assumez le rôle dans votre terminal local.
Si vous préférez utiliser les flux de travail GitHub Actions pour le déploiement, configurez les éléments suivants :
Un compte JFrog Artifactory
pour obtenir le nom d'hôte, le nom d'utilisateur de connexion et le jeton d'accès. Une clé de JFrog projet et un référentiel
pour le stockage des artefacts.
Limites
L' Chaîne d'approvisionnement instance ne prend pas en charge les techniques de transformation de données complexes.
Chaîne d'approvisionnement est particulièrement adapté aux domaines de la chaîne d'approvisionnement car il fournit des analyses et des informations intégrées. Pour tout autre domaine, il Chaîne d'approvisionnement peut être utilisé comme magasin de données dans le cadre de l'architecture du lac de données.
Les fonctions Lambda utilisées dans cette solution devront peut-être être améliorées pour gérer les nouvelles tentatives d'API et la gestion de la mémoire dans le cadre d'un déploiement à l'échelle de la production.
Certains Services AWS ne sont pas disponibles du tout Régions AWS. Pour connaître la disponibilité par région, consultez la section AWS Services par région
. Pour des points de terminaison spécifiques, consultez Points de terminaison de service et quotas, puis choisissez le lien correspondant au service.
Architecture
Vous pouvez déployer cette solution soit à l'aide de flux de travail GitHub Actions automatisés, soit manuellement à l'aide de Terraform.
Déploiement automatisé avec des GitHub actions
Le schéma suivant montre l'option de déploiement automatique qui utilise les flux de travail GitHub Actions. JFrog Artifactory est utilisé pour la gestion des artefacts. Il stocke les informations sur les ressources et les sorties à utiliser dans le cadre d'un déploiement multi-référentiels.
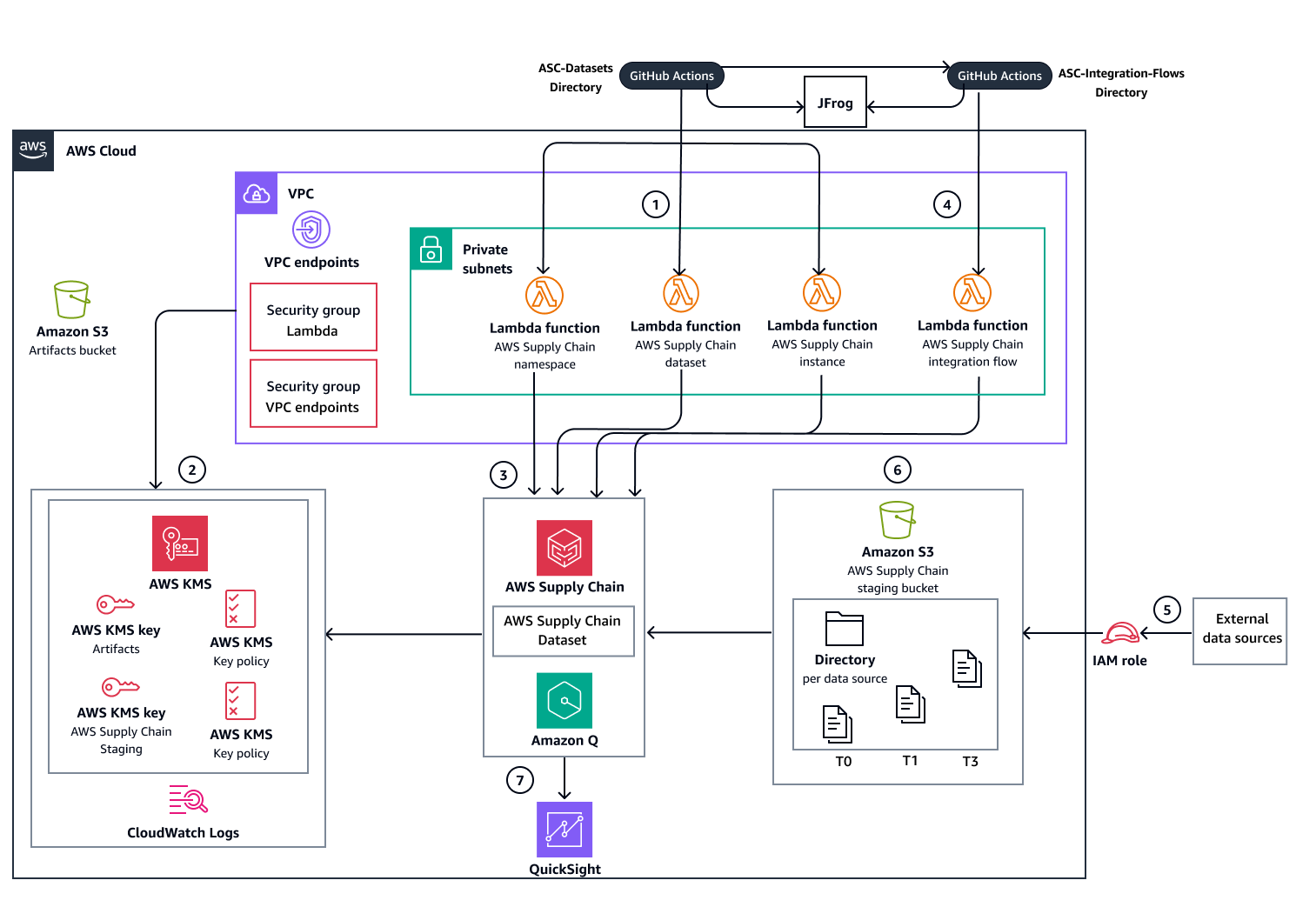
Déploiement manuel avec Terraform
Le schéma suivant montre l'option de déploiement manuel via Terraform. Au lieu d' JFrog Artifactory, Amazon S3 est utilisé pour la gestion des artefacts.

Flux de travail de déploiement
Les diagrammes montrent le flux de travail suivant :
Déployez l'infrastructure des ensembles de données de Chaîne d'approvisionnement service et les bases de données à l'aide de l'une des méthodes de déploiement suivantes :
Déploiement automatisé : utilise GitHub les flux de travail Actions pour orchestrer toutes les étapes de déploiement et utilise JFrog Artifactory pour la gestion des artefacts.
Déploiement manuel : exécute les commandes Terraform directement pour chaque étape de déploiement et utilise Amazon S3 pour la gestion des artefacts.
Créez les AWS ressources de support nécessaires au fonctionnement Chaîne d'approvisionnement du service :
Points de terminaison et groupes de sécurité Amazon VPC
AWS KMS keys
CloudWatch Logs, journaux, groupes
Créez et déployez les ressources d'infrastructure suivantes :
Fonctions Lambda qui gèrent (créent, mettent à jour et suppriment) l'instance de Chaîne d'approvisionnement service, les espaces de noms et les ensembles de données.
Chaîne d'approvisionnement préparation du compartiment Amazon S3 pour l'ingestion de données
Déployez la fonction Lambda qui gère les flux d'intégration entre le bucket intermédiaire et Chaîne d'approvisionnement les ensembles de données. Une fois le déploiement terminé, les étapes restantes du flux de travail gèrent l'ingestion et l'analyse des données.
Configurez l'ingestion des données sources dans Chaîne d'approvisionnement le compartiment Amazon S3 intermédiaire.
Une fois les données ajoutées au compartiment Chaîne d'approvisionnement Amazon S3 intermédiaire, le service déclenche automatiquement le flux d'intégration vers les Chaîne d'approvisionnement ensembles de données.
Chaîne d'approvisionnement s'intègre à Quick Sight Analytics pour produire des tableaux de bord basés sur les données ingérées.
Outils
Services AWS
Amazon CloudWatch Logs vous aide à centraliser les journaux de tous vos systèmes et applications, Services AWS afin que vous puissiez les surveiller et les archiver en toute sécurité.
AWS Command Line Interface (AWS CLI) est un outil open source qui vous permet d'interagir Services AWS par le biais de commandes dans votre interface de ligne de commande.
Amazon Elastic Compute Cloud (Amazon EC2) offre une capacité de calcul évolutive dans l' AWS Cloud. Vous pouvez lancer autant de serveurs virtuels que vous le souhaitez et les augmenter ou les diminuer rapidement.
Amazon EventBridge est un service de bus d'événements sans serveur qui vous permet de connecter vos applications à des données en temps réel provenant de diverses sources. Par exemple, des AWS Lambda fonctions, des points de terminaison d'invocation HTTP utilisant des destinations d'API ou des bus d'événements dans d'autres. Comptes AWS
Gestion des identités et des accès AWS (IAM) vous aide à gérer en toute sécurité l'accès à vos AWS ressources en contrôlant qui est authentifié et autorisé à les utiliser.
AWS IAM Identity Centervous permet de gérer de manière centralisée l'accès par authentification unique (SSO) à toutes vos applications Comptes AWS et à celles du cloud.
AWS Key Management Service (AWS KMS) vous aide à créer et à contrôler des clés cryptographiques afin de protéger vos données.
AWS Lambda est un service de calcul qui vous aide à exécuter du code sans avoir à allouer ni à gérer des serveurs. Il exécute votre code uniquement lorsque cela est nécessaire et évolue automatiquement, de sorte que vous ne payez que pour le temps de calcul que vous utilisez.
Amazon Q in Chaîne d'approvisionnement est un assistant d'intelligence artificielle générative interactif qui vous aide à gérer votre chaîne d'approvisionnement de manière plus efficace en analysant les données de votre lac de Chaîne d'approvisionnement données.
Amazon Quick Sight est un service de business intelligence (BI) à l'échelle du cloud qui vous permet de visualiser, d'analyser et de rapporter vos données dans un tableau de bord unique.
Amazon Simple Storage Service (Amazon S3) est un service de stockage d'objets basé sur le cloud qui vous permet de stocker, de protéger et de récupérer n'importe quel volume de données.
Chaîne d'approvisionnementest une application gérée dans le cloud qui peut être utilisée comme magasin de données dans les organisations pour les domaines de la chaîne d'approvisionnement, qui peut être utilisée pour générer des informations et effectuer des analyses sur les données ingérées.
Amazon Virtual Private Cloud (Amazon VPC) vous aide à lancer AWS des ressources dans un réseau virtuel que vous avez défini. Ce réseau virtuel ressemble à un réseau traditionnel que vous pourriez exécuter dans votre propre centre de données et présente l'avantage d'utiliser l'infrastructure évolutive d' AWS. Un point de terminaison Amazon VPC est un appareil virtuel qui vous permet de connecter de manière privée votre VPC à un service compatible Services AWS sans avoir besoin d'une passerelle Internet, d'un appareil NAT, d'une connexion VPN ou d'une connexion. AWS Direct Connect
Autres outils
GitHub Actions
est une plateforme d'intégration et de livraison continues (CI/CD) étroitement intégrée aux GitHub référentiels. Vous pouvez utiliser GitHub les actions pour automatiser votre pipeline de création, de test et de déploiement. HashiCorp Terraform
est un outil d'infrastructure en tant que code (IaC) qui vous aide à créer et à gérer des ressources sur site et dans le cloud. JFrog Artifactory
assure end-to-end l'automatisation et la gestion des fichiers binaires et des artefacts tout au long du processus de livraison des applications. Python
est un langage de programmation informatique polyvalent. Ce modèle utilise Python pour que le code de la AWS fonction interagisse avec Chaîne d'approvisionnement .
Bonnes pratiques
Maintenez le niveau de sécurité le plus élevé possible lors de la mise en œuvre de ce modèle. Comme indiqué dans la section Conditions préalables, assurez-vous qu'un cloud privé virtuel (VPC) avec deux sous-réseaux privés se trouve dans Région AWS l'espace de Compte AWS votre choix.
Utilisez des clés gérées par le AWS KMS client dans la mesure du possible et accordez-leur des autorisations d'accès limitées.
Pour configurer les rôles IAM avec le moins d'accès requis pour ingérer les données pour ce modèle, consultez la section Ingestion sécurisée des données depuis les systèmes source vers Amazon S3
dans le référentiel de ce modèle.
Épopées
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Pour cloner le référentiel. | Pour cloner le dépôt de ce modèle, exécutez la commande suivante sur votre station de travail locale :
| AWS DevOps |
(Option automatique) Vérifiez les conditions préalables au déploiement. | Assurez-vous que les conditions préalables sont remplies pour le déploiement automatique. | Propriétaire de l'application |
(Option manuelle) Préparez le déploiement des Chaîne d'approvisionnement ensembles de données. | Pour accéder au
Pour assumer le rôle ARN créé dans les prérequis, exécutez la commande suivante :
Pour configurer et exporter les variables d'environnement, exécutez les commandes suivantes :
| AWS DevOps |
(Option manuelle) Préparez-vous à gérer les flux Chaîne d'approvisionnement d'intégration lors du déploiement. | Pour accéder au
Pour assumer le rôle ARN créé précédemment, exécutez la commande suivante :
Pour configurer et exporter les variables d'environnement, exécutez les commandes suivantes :
| Propriétaire de l'application |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Copiez le | Pour copier le
| AWS DevOps |
Configurez le | Pour le configurer
| AWS DevOps |
Configurez le nom de la branche dans le fichier de flux de travail .github. | Configurez le nom de la branche dans le fichier du flux de travail de déploiement
| Propriétaire de l'application |
Configurez GitHub des environnements et configurez les valeurs d'environnement. | Pour configurer GitHub des environnements dans votre GitHub organisation, suivez les instructions de la section Configuration GitHub des environnements Pour configurer les valeurs d'environnement | Propriétaire de l'application |
Déclenchez le flux de travail. | Pour appliquer vos modifications à votre GitHub organisation et déclencher le flux de travail de déploiement, exécutez la commande suivante :
| AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Copiez le | Pour copier le
| AWS DevOps |
Configurez le | Pour configurer le
| AWS DevOps |
Configurez le nom de la branche dans le fichier de flux de travail .github. | Configurez le nom de la branche dans le fichier du flux de travail de déploiement
| Propriétaire de l'application |
Configurez GitHub des environnements et configurez les valeurs d'environnement. | Pour configurer GitHub des environnements dans votre GitHub organisation, suivez les instructions de la section Configuration GitHub des environnements Pour configurer les valeurs d'environnement | Propriétaire de l'application |
Déclenchez le flux de travail. | Pour appliquer vos modifications à votre GitHub organisation et déclencher le flux de travail de déploiement, exécutez la commande suivante :
| AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Accédez au répertoire | Pour accéder au
| AWS DevOps |
Configurez le compartiment Amazon S3 d'état Terraform. | Pour configurer le compartiment Amazon S3 d'état Terraform, utilisez le script suivant :
| AWS DevOps |
Configurez le compartiment Amazon S3 des artefacts Terraform. | Pour configurer le compartiment Amazon S3 des artefacts Terraform, utilisez le script suivant :
| AWS DevOps |
Configurez le backend Terraform et la configuration des fournisseurs. | Pour configurer le backend Terraform et la configuration des fournisseurs, utilisez le script suivant :
| AWS DevOps |
Générez un plan de déploiement. | Pour générer un plan de déploiement, exécutez les commandes suivantes :
| AWS DevOps |
Déployez les configurations. | Pour déployer les configurations, exécutez la commande suivante :
| AWS DevOps |
Mettez à jour les autres configurations et stockez les sorties. | Pour mettre à jour les politiques AWS KMS clés et stocker les sorties de configuration appliquées dans le compartiment Amazon S3 des artefacts Terraform, exécutez les commandes suivantes :
| AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Accédez au répertoire | Pour accéder au
| AWS DevOps |
Configurez le backend Terraform et la configuration des fournisseurs. | Pour configurer les configurations du backend et du fournisseur Terraform, utilisez le script suivant :
| AWS DevOps |
Générez un plan de déploiement. | Pour générer un plan de déploiement, exécutez les commandes suivantes. Ces commandes initialisent votre environnement Terraform, fusionnent les variables de configuration
| AWS DevOps |
Déployez les configurations. | Pour déployer les configurations, exécutez la commande suivante :
| AWS DevOps |
Mettez à jour les autres configurations. | Pour mettre à jour les politiques AWS KMS clés et stocker les sorties de configuration appliquées dans le compartiment Amazon S3 des artefacts Terraform, exécutez les commandes suivantes :
| AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Téléchargez des exemples de fichiers CSV. | Pour télécharger des exemples de fichiers CSV pour les ensembles de données, procédez comme suit :
| Ingénieur de données |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Configurez Chaîne d'approvisionnement l'accès. | Pour configurer Chaîne d'approvisionnement l'accès depuis le AWS Management Console, procédez comme suit :
| Propriétaire de l'application |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Déclenchez le flux de travail de destruction des ressources des flux d'intégration. | Déclenchez le flux de travail de destruction | AWS DevOps |
Déclenchez le flux de travail de destruction des ressources des ensembles de données. | Déclenchez le flux de travail de destruction | AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Accédez au répertoire | Pour accéder au
| AWS DevOps |
Configurez le backend Terraform et la configuration des fournisseurs. | Pour configurer le backend Terraform et la configuration des fournisseurs, utilisez le script suivant :
| AWS DevOps |
Générez un plan de destruction de l'infrastructure. | Pour préparer la destruction contrôlée de votre AWS infrastructure en générant un plan de démontage détaillé, exécutez les commandes suivantes. Le processus initialise Terraform, intègre les configurations de Chaîne d'approvisionnement jeux de données et crée un plan de destruction que vous pouvez consulter avant de l'exécuter.
| AWS DevOps |
Exécutez le plan de destruction de l'infrastructure. | Pour exécuter la destruction planifiée de votre infrastructure, exécutez la commande suivante :
| AWS DevOps |
Supprimez les sorties Terraform du compartiment Amazon S3. | Pour supprimer le fichier de sortie qui a été chargé lors du déploiement de
| AWS DevOps |
| Sous-tâche | Description | Compétences requises |
|---|---|---|
Accédez au répertoire | Pour accéder au
| AWS DevOps |
Configurez le backend Terraform et la configuration des fournisseurs. | Pour configurer le backend Terraform et la configuration des fournisseurs, utilisez le script suivant :
| AWS DevOps |
Générez un plan de destruction de l'infrastructure. | Pour créer un plan de destruction des ressources du Chaîne d'approvisionnement jeu de données, exécutez les commandes suivantes :
| AWS DevOps |
Compartiments Amazon S3 vides. | Pour vider tous les compartiments Amazon S3 (à l'exception du compartiment de journalisation des accès au serveur, qui est configuré pour
| AWS DevOps |
Exécutez le plan de destruction de l'infrastructure. | Pour exécuter la destruction planifiée de votre infrastructure de jeux de Chaîne d'approvisionnement données à l'aide du plan généré, exécutez la commande suivante :
| AWS DevOps |
Supprimez les sorties Terraform du compartiment d'artefacts Amazon S3 Terraform. | Pour terminer le processus de nettoyage, supprimez le fichier de sortie qui a été chargé lors du déploiement de
| AWS DevOps |
Résolution des problèmes
| Problème | Solution |
|---|---|
Un Chaîne d'approvisionnement ensemble de données ou un flux d'intégration n'a pas été déployé correctement en raison d'erreurs Chaîne d'approvisionnement internes ou d'autorisations IAM insuffisantes pour le rôle de service. | Tout d'abord, nettoyez toutes les ressources. Redéployez ensuite les ressources du Chaîne d'approvisionnement jeu de données |
Le flux Chaîne d'approvisionnement d'intégration ne récupère pas les nouveaux fichiers de données chargés pour les Chaîne d'approvisionnement ensembles de données. |
|
Ressources connexes
AWS documentation
Autres ressources
Comprendre GitHub les flux de travail liés aux actions
(GitHub documentation)
Informations supplémentaires
Cette solution peut être répliquée pour un plus grand nombre d'ensembles de données et peut être interrogée pour une analyse plus approfondie, via des tableaux de bord prédéfinis fournis ou une intégration Chaîne d'approvisionnement personnalisée avec Amazon Quick Sight. En outre, vous pouvez utiliser Amazon Q pour poser des questions relatives à votre Chaîne d'approvisionnement instance.
Analyser les données avec Chaîne d'approvisionnement Analytics
Pour obtenir des instructions sur la configuration Chaîne d'approvisionnement d'Analytics, consultez la section Configuration Chaîne d'approvisionnement d'Analytics dans la Chaîne d'approvisionnement documentation.
Ce modèle a démontré la création des ensembles de données Calendar et Outbound_Order_Line. Pour créer une analyse utilisant ces ensembles de données, procédez comme suit :
Pour analyser les ensembles de données, utilisez le tableau de bord d'analyse de la saisonnalité. Pour ajouter le tableau de bord, suivez les étapes décrites dans la section Tableaux de bord prédéfinis de la Chaîne d'approvisionnement documentation.
Choisissez le tableau de bord pour voir son analyse basée sur des exemples de fichiers CSV pour les données du calendrier et les données des lignes de commande sortantes.
Le tableau de bord fournit des informations à la demande au fil des ans sur la base des données ingérées pour les ensembles de données. Vous pouvez également spécifier le ProductID, le CustomerID, les années et d'autres paramètres pour l'analyse.
Utilisez Amazon Q pour poser des questions relatives à votre Chaîne d'approvisionnement instance
Amazon Q in Chaîne d'approvisionnement est un assistant IA génératif interactif qui vous aide à gérer votre chaîne d'approvisionnement de manière plus efficace. Amazon Q peut effectuer les opérations suivantes :
Analysez les données de votre lac Chaîne d'approvisionnement de données.
Fournissez des informations opérationnelles et financières.
Répondez à vos questions immédiates sur la chaîne d'approvisionnement.
Pour plus d'informations sur l'utilisation d'Amazon Q, consultez les sections Activation d'Amazon Q dans Chaîne d'approvisionnement et Utilisation d'Amazon Q Chaîne d'approvisionnement dans la Chaîne d'approvisionnement documentation.
