Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
# Utilisation des tables Iceberg à l'aide d'Apache Spark
Cette section fournit une vue d'ensemble de l'utilisation d'Apache Spark pour interagir avec les tables Iceberg. Les exemples sont du code standard qui peut être exécuté sur Amazon EMR ou. AWS Glue
Remarque : L'interface principale pour interagir avec les tables Iceberg est SQL. La plupart des exemples associeront donc Spark SQL à l' DataFrames API.
## Création et écriture de tables Iceberg
Vous pouvez utiliser Spark SQL et Spark DataFrames pour créer et ajouter des données aux tables Iceberg.
### Utilisation de Spark SQL
Pour écrire un jeu de données Iceberg, utilisez des instructions SQL Spark standard telles que `CREATE TABLE` et`INSERT INTO`.
#### Tables non partitionnées
Voici un exemple de création d'une table Iceberg non partitionnée avec Spark SQL :
```
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions (
c_customer_sk int,
c_customer_id string,
c_first_name string,
c_last_name string,
c_birth_country string,
c_email_address string)
USING iceberg
OPTIONS ('format-version'='2')
""")
```
Pour insérer des données dans une table non partitionnée, utilisez une instruction standard `INSERT INTO` :
```
spark.sql(f"""
INSERT INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions
SELECT c_customer_sk, c_customer_id, c_first_name, c_last_name, c_birth_country, c_email_address
FROM another_table
""")
```
#### Tables partitionnées
Voici un exemple de création d'une table Iceberg partitionnée avec Spark SQL :
```
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions (
c_customer_sk int,
c_customer_id string,
c_first_name string,
c_last_name string,
c_birth_country string,
c_email_address string)
USING iceberg
PARTITIONED BY (c_birth_country)
OPTIONS ('format-version'='2')
""")
```
Pour insérer des données dans une table Iceberg partitionnée avec Spark SQL, utilisez une instruction standard `INSERT INTO` :
```
spark.sql(f"""
INSERT INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions
SELECT c_customer_sk, c_customer_id, c_first_name, c_last_name, c_birth_country, c_email_address
FROM another_table
""")
```
**Note**
À partir de la version 1.5.0 d'Iceberg, le mode de distribution d'`hash`écriture est le mode par défaut lorsque vous insérez des données dans des tables partitionnées. Pour plus d'informations, consultez la section [Writing Distribution Modes](https://iceberg.apache.org/docs/latest/spark-writes/#writing-distribution-modes) dans la documentation d'Iceberg.
### Utilisation de l' DataFrames API
Pour écrire un jeu de données Iceberg, vous pouvez utiliser l'`DataFrameWriterV2`API.
Pour créer une table Iceberg et y écrire des données, utilisez la fonction `df.writeTo(` t). Si la table existe, utilisez la `.append()` fonction. Si ce n'est pas le cas, utilisez `.create().` Les exemples suivants utilisent`.createOrReplace()`, qui est une variante de `.create()` ce qui équivaut à`CREATE OR REPLACE TABLE AS SELECT`.
#### Tables non partitionnées
Pour créer et remplir une table Iceberg non partitionnée à l'aide de l'API : `DataFrameWriterV2`
```
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions") \
.tableProperty("format-version", "2") \
.createOrReplace()
```
Pour insérer des données dans une table Iceberg non partitionnée existante à l'aide de l'API : `DataFrameWriterV2`
```
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_nopartitions") \
.append()
```
#### Tables partitionnées
Pour créer et remplir une table Iceberg partitionnée à l'aide de l'API : `DataFrameWriterV2`
```
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions") \
.tableProperty("format-version", "2") \
.partitionedBy("c_birth_country") \
.createOrReplace()
```
Pour insérer des données dans une table Iceberg partitionnée à l'aide de l'`DataFrameWriterV2`API :
```
input_data.writeTo(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}_withpartitions") \
.append()
```
## Mise à jour des données dans les tables Iceberg
L'exemple suivant montre comment mettre à jour les données d'une table Iceberg. Cet exemple modifie toutes les lignes dont la `c_customer_sk` colonne contient un nombre pair.
```
spark.sql(f"""
UPDATE {CATALOG_NAME}.{db.name}.{table.name}
SET c_email_address = 'even_row'
WHERE c_customer_sk % 2 == 0
""")
```
Cette opération utilise la copy-on-write stratégie par défaut, de sorte qu'elle réécrit tous les fichiers de données concernés.
## Insertion de données dans des tables Iceberg
La modification des données fait référence à l'insertion de nouveaux enregistrements de données et à la mise à jour des enregistrements de données existants en une seule transaction. Pour insérer des données dans une table Iceberg, vous devez utiliser l'`SQL MERGE INTO`instruction.
L'exemple suivant insère le contenu de la table`{UPSERT_TABLE_NAME`} à l'intérieur de la table : `{TABLE_NAME}`
```
spark.sql(f"""
MERGE INTO {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME} t
USING {UPSERT_TABLE_NAME} s
ON t.c_customer_id = s.c_customer_id
WHEN MATCHED THEN UPDATE SET t.c_email_address = s.c_email_address
WHEN NOT MATCHED THEN INSERT *
""")
```
+ Si un enregistrement client présent existe `{UPSERT_TABLE_NAME}` déjà dans le même dossier`c_customer_id`, la valeur de l'`{UPSERT_TABLE_NAME}`enregistrement remplace la `c_email_address` valeur existante (opération de mise à jour). `{TABLE_NAME}`
+ Si un enregistrement client qui se trouve dans `{UPSERT_TABLE_NAME}` n'existe pas dans`{TABLE_NAME}`, l'`{UPSERT_TABLE_NAME}`enregistrement est ajouté `{TABLE_NAME}` (opération d'insertion).
## Supprimer des données dans les tables Iceberg
Pour supprimer des données d'une table Iceberg, utilisez l'`DELETE FROM`expression et spécifiez un filtre correspondant aux lignes à supprimer.
```
spark.sql(f"""
DELETE FROM {CATALOG_NAME}.{db.name}.{table.name}
WHERE c_customer_sk % 2 != 0
""")
```
Si le filtre correspond à une partition entière, Iceberg supprime uniquement les métadonnées et laisse les fichiers de données en place. Dans le cas contraire, il réécrit uniquement les fichiers de données concernés.
La méthode de suppression prend les fichiers de données concernés par la `WHERE` clause et en crée une copie sans les enregistrements supprimés. Il crée ensuite un nouvel instantané de table qui pointe vers les nouveaux fichiers de données. Par conséquent, les enregistrements supprimés sont toujours présents dans les anciens instantanés de la table. Par exemple, si vous récupérez l'instantané précédent de la table, vous verrez les données que vous venez de supprimer. Pour plus d'informations sur la suppression d'anciens instantanés inutiles avec les fichiers de données associés à des fins de nettoyage, consultez la section Gestion des [fichiers à l'aide du compactage](best-practices-compaction.md) plus loin dans ce guide.
## Lecture de données
Vous pouvez consulter le dernier état de vos tables Iceberg dans Spark à la fois avec Spark SQL et DataFrames.
Exemple d'utilisation de Spark SQL :
```
spark.sql(f"""
SELECT * FROM {CATALOG_NAME}.{db.name}.{table.name} LIMIT 5
""")
```
Exemple d'utilisation de l' DataFrames API :
```
df = spark.table(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}").limit(5)
```
## Utiliser le voyage dans le temps
Chaque opération d'écriture (insertion, mise à jour, modification, suppression) dans une table Iceberg crée un nouvel instantané. Vous pouvez ensuite utiliser ces instantanés pour voyager dans le temps, pour revenir dans le temps et vérifier le statut d'un tableau dans le passé.
Pour plus d'informations sur la façon de récupérer l'historique des instantanés de tables en utilisant `snapshot-id` et en chronométrant des valeurs, consultez la section [Accès aux métadonnées](#spark-metadata) plus loin dans ce guide.
La requête de voyage dans le temps suivante affiche le statut d'une table en fonction d'une donnée spécifique`snapshot-id`.
À l'aide de Spark SQL :
```
spark.sql(f"""
SELECT * FROM {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME} VERSION AS OF {snapshot_id}
""")
```
À l'aide de DataFrames l'API :
```
df_1st_snapshot_id = spark.read.option("snapshot-id", snapshot_id) \
.format("iceberg") \
.load(f"{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}") \
.limit(5)
```
La requête de voyage dans le temps suivante affiche le statut d'une table en fonction du dernier instantané créé avant un horodatage spécifique, en millisecondes (). `as-of-timestamp`
À l'aide de Spark SQL :
```
spark.sql(f"""
SELECT * FROM dev.{db.name}.{table.name} TIMESTAMP AS OF '{snapshot_ts}'
""")
```
À l'aide de DataFrames l'API :
```
df_1st_snapshot_ts = spark.read.option("as-of-timestamp", snapshot_ts) \
.format("iceberg") \
.load(f"dev.{DB_NAME}.{TABLE_NAME}") \
.limit(5)
```
## Utilisation de requêtes incrémentielles
Vous pouvez également utiliser les instantanés Iceberg pour lire les données ajoutées de manière incrémentielle.
Remarque : Actuellement, cette opération prend en charge la lecture de données à partir de `append` snapshots. Il ne prend pas en charge l'extraction de données à partir d'opérations telles que `replace``overwrite`, ou`delete`. De plus, les opérations de lecture incrémentielles ne sont pas prises en charge dans la syntaxe SQL de Spark.
L'exemple suivant récupère tous les enregistrements ajoutés à une table Iceberg entre l'instantané `start-snapshot-id` (exclusif) et `end-snapshot-id` (inclus).
```
df_incremental = (spark.read.format("iceberg")
.option("start-snapshot-id", snapshot_id_start)
.option("end-snapshot-id", snapshot_id_end)
.load(f"glue_catalog.{DB_NAME}.{TABLE_NAME}")
)
```
## Accès aux métadonnées
Iceberg fournit un accès à ses métadonnées via SQL. Vous pouvez accéder aux métadonnées d'une table donnée (``) en interrogeant l'espace de noms`.`. Pour obtenir la liste complète des tables de métadonnées, consultez la section [Inspection des tables](https://iceberg.apache.org/docs/latest/spark-queries/#inspecting-tables) dans la documentation d'Iceberg.
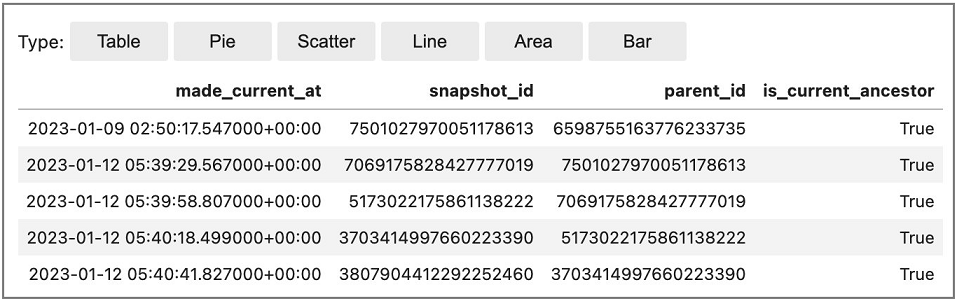
L'exemple suivant montre comment accéder à la table de métadonnées d'historique d'Iceberg, qui présente l'historique des validations (modifications) d'une table Iceberg.
En utilisant Spark SQL (avec la `%%sql` magie) à partir d'un bloc-notes Amazon EMR Studio :
```
Spark.sql(f"""
SELECT * FROM {CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}.history LIMIT 5
""")
```
À l'aide de DataFrames l'API :
```
spark.read.format("iceberg").load("{CATALOG_NAME}.{DB_NAME}.{TABLE_NAME}.history").show(5,False)
```
Exemple de sortie :