Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Configuration de récupération de la base de connaissances
Lorsque vous utilisez des agents d'orchestration AI, vous pouvez configurer des outils Retrieve qui permettent à votre agent d'IA de rechercher des bases de connaissances et de renvoyer des informations pertinentes pour répondre aux questions des utilisateurs.
Chaque outil Retrieve interroge une seule base de connaissances. En configurant plusieurs outils de récupération, vous permettez à votre agent d'intelligence artificielle d'interroger plusieurs bases de connaissances simultanément ou de sélectionner intelligemment celle à rechercher en fonction de la question de l'utilisateur. Well-defined les descriptions des outils et les instructions rapides permettent au modèle d'acheminer automatiquement les requêtes vers la base de connaissances la plus pertinente.
Vous pouvez contrôler la manière dont votre agent d'intelligence artificielle interroge le contenu à deux niveaux :
-
Niveau de base de connaissances : configurez plusieurs outils de récupération pour interroger différentes bases de connaissances. Utilisez cette approche lorsque votre contenu est organisé en plusieurs bases de connaissances.
-
Niveau du contenu : utilisez la segmentation du contenu pour n'interroger que du contenu spécifique au sein d'une seule base de connaissances.
Table des matières
Comment configurer votre agent d'orchestration pour interroger plusieurs bases de connaissances
Vous pouvez configurer plusieurs outils de récupération pour interroger différentes bases de connaissances. En fonction de votre cas d'utilisation, vous pouvez soit :
Interrogation simultanée de toutes les bases de connaissances (invocation parallèle)
Interroger des bases de connaissances spécifiques en fonction du contexte de la demande (invocation conditionnelle)
Configuration de plusieurs outils de récupération
Les deux configurations nécessitent la même configuration initiale. Effectuez d'abord ces étapes, puis suivez les instructions correspondant à votre cas d'utilisation spécifique.
-
Depuis la console AWS, vous pouvez ajouter des bases de connaissances supplémentaires en choisissant Ajouter une intégration et en suivant l'expérience guidée. Dans cet exemple, nous avons ajouté demo-byobkb comme base de connaissances supplémentaire.

-
Dans AI Agent Designer, créez un nouvel agent d'orchestration AI et modifiez l'outil de récupération par défaut
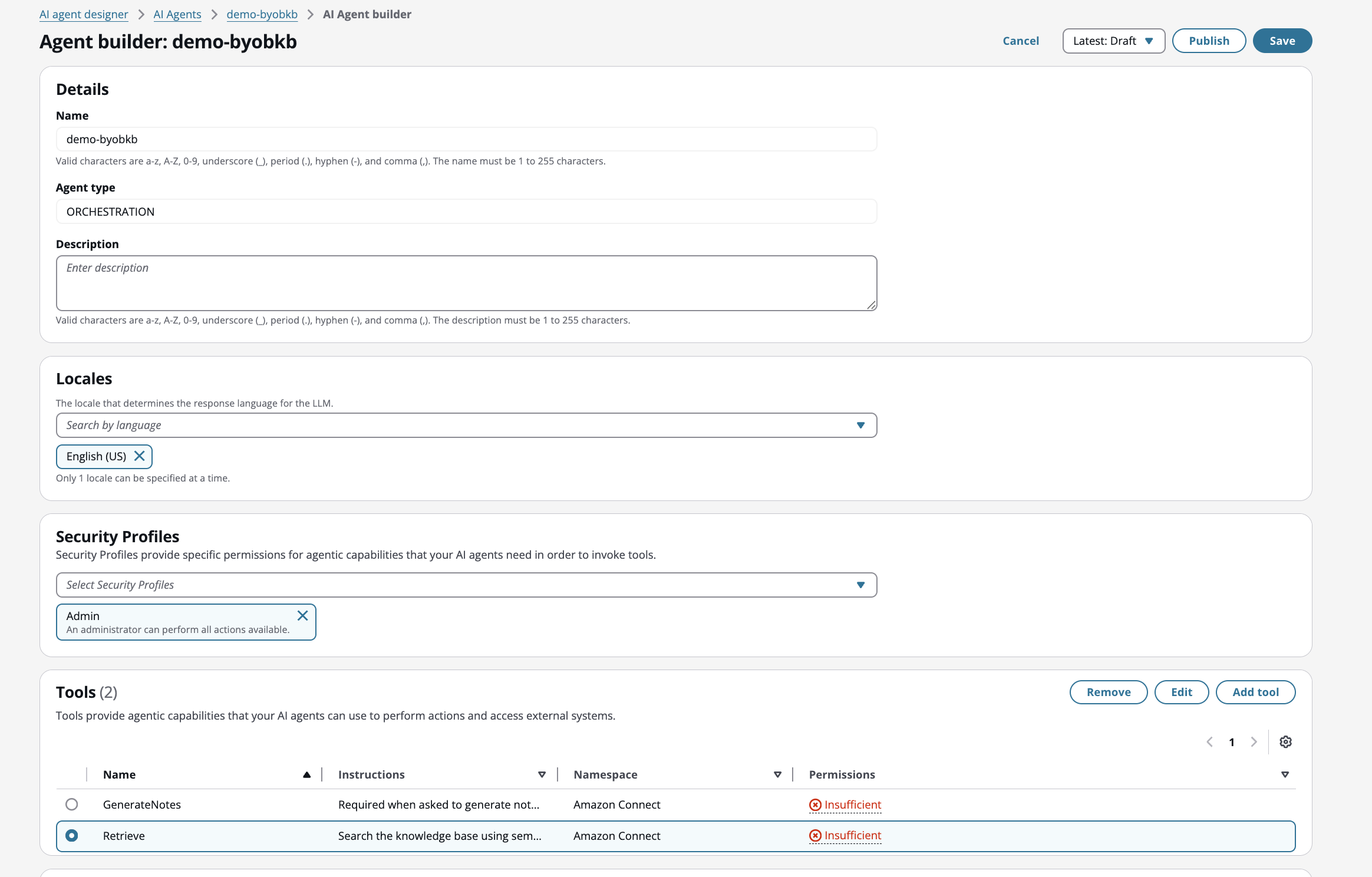
-
Associez la base de connaissances existante à l'outil de récupération. L'agent AI utilisera cette base de connaissances par défaut
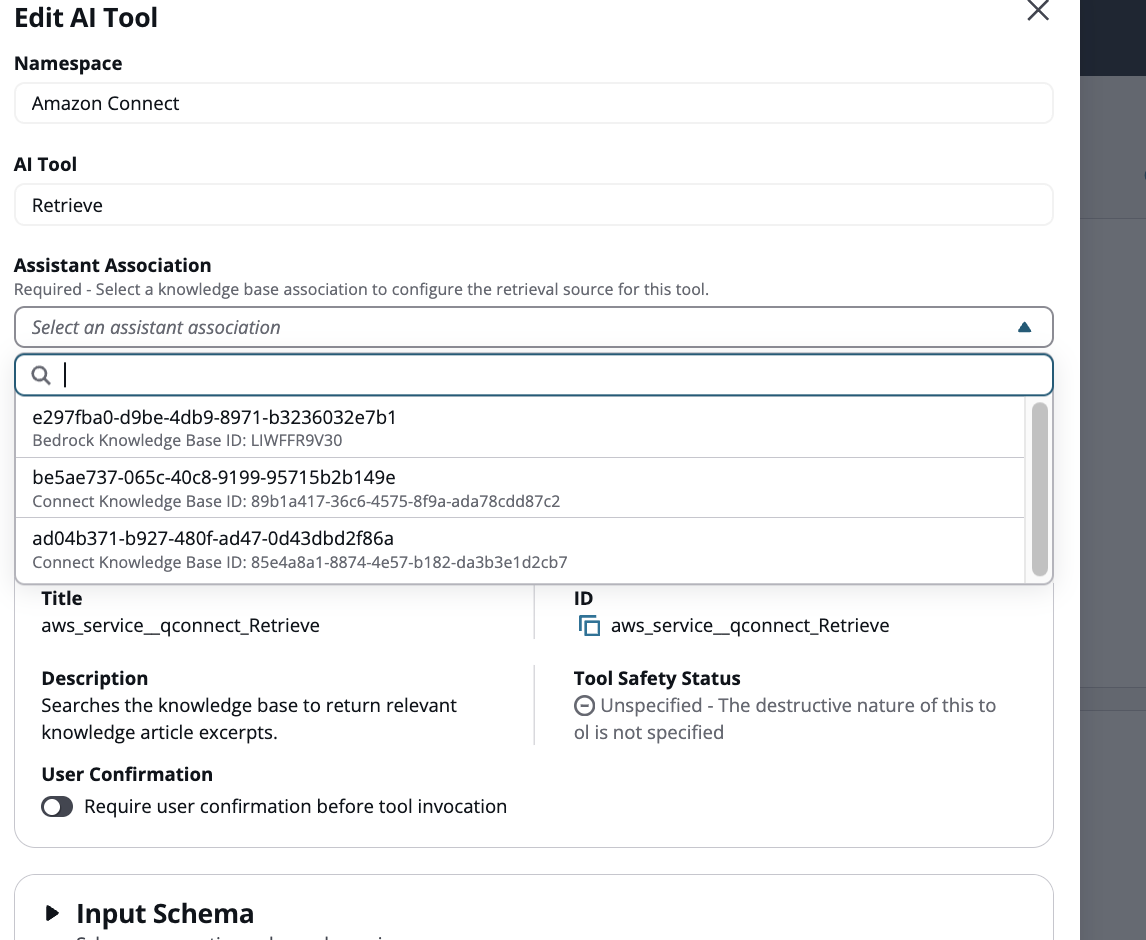
-
Ajoutez un outil supplémentaire, choisissez Amazon Connect comme espace de noms et choisissez le type d'outil d'IA Retrieve
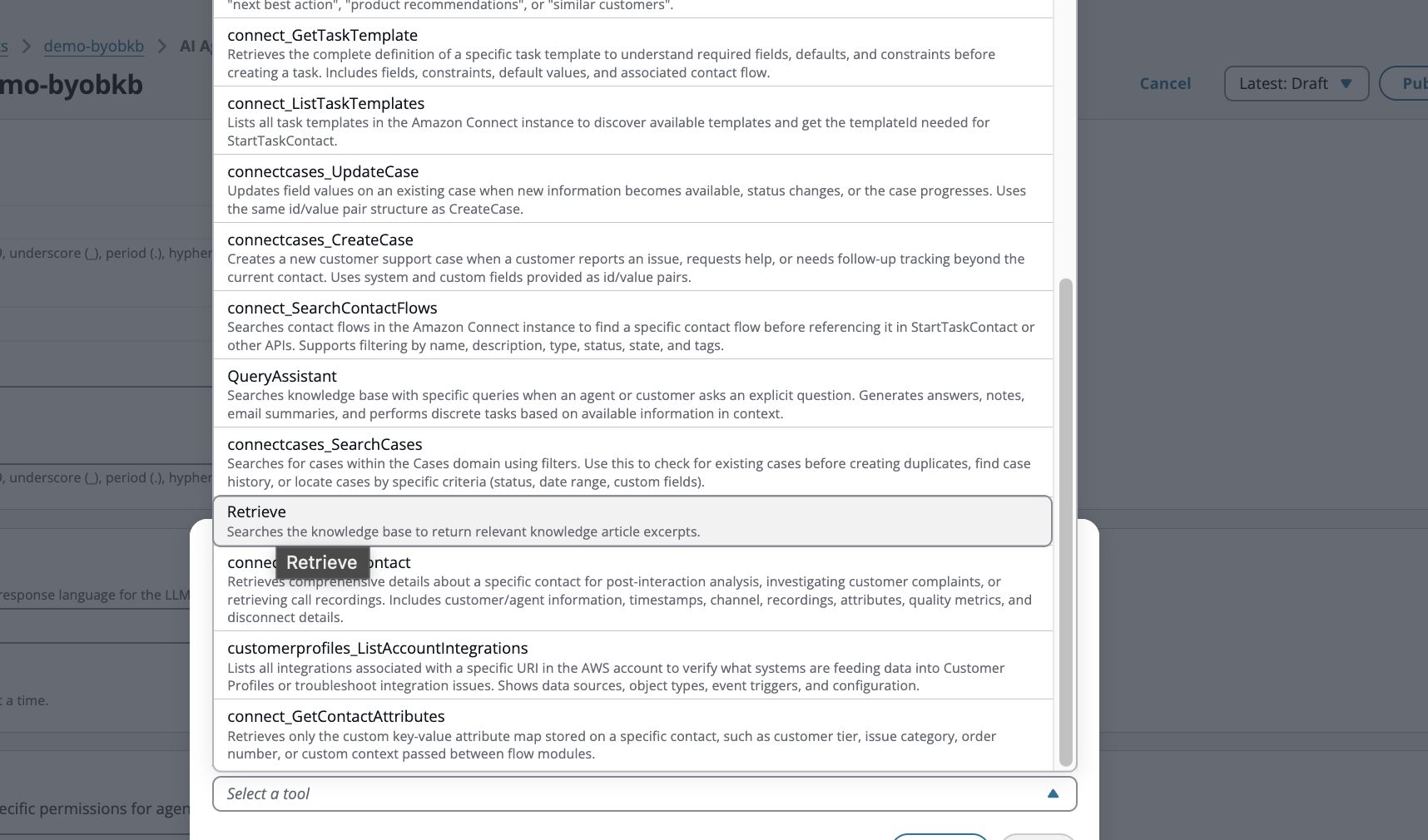
-
Sélectionnez maintenant la base de connaissances supplémentaire que vous souhaitez associer en plus de la base de connaissances par défaut.
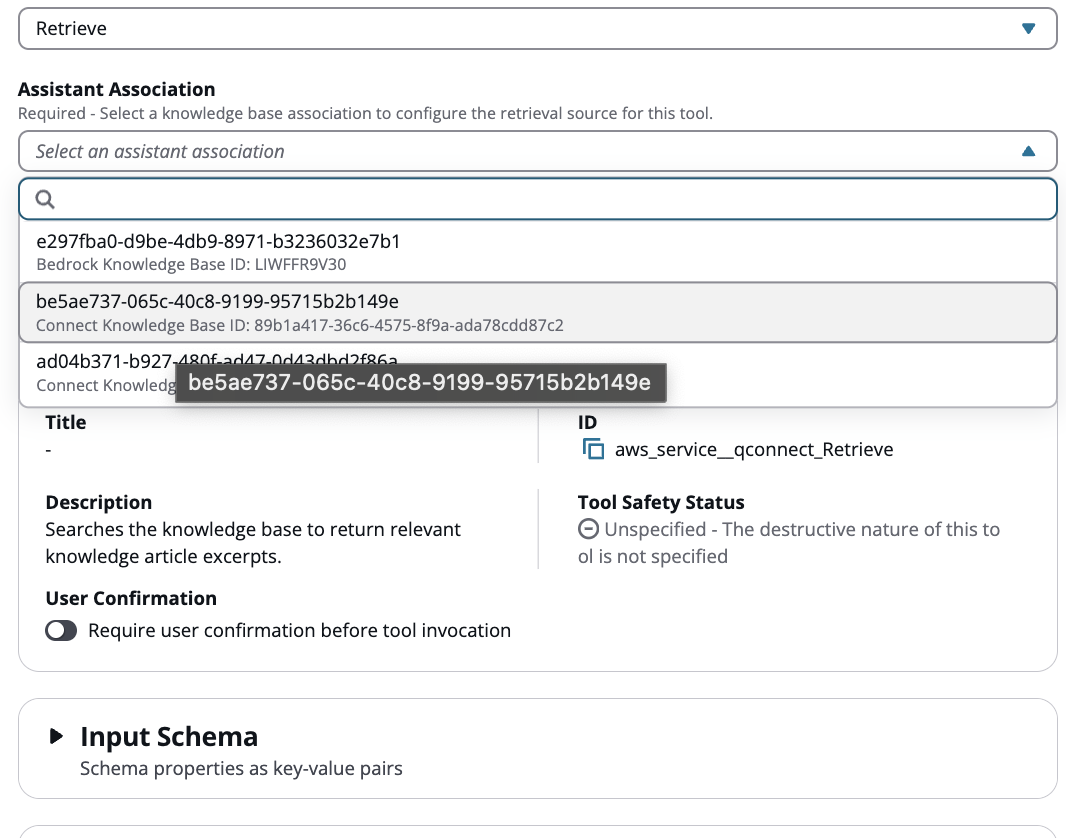
-
Nommez chaque outil de récupération supplémentaire en commençant par « Retrieve » (par exemple, Retrieve2, Retrieve3,,). RetrieveProducts RetrievePolicies
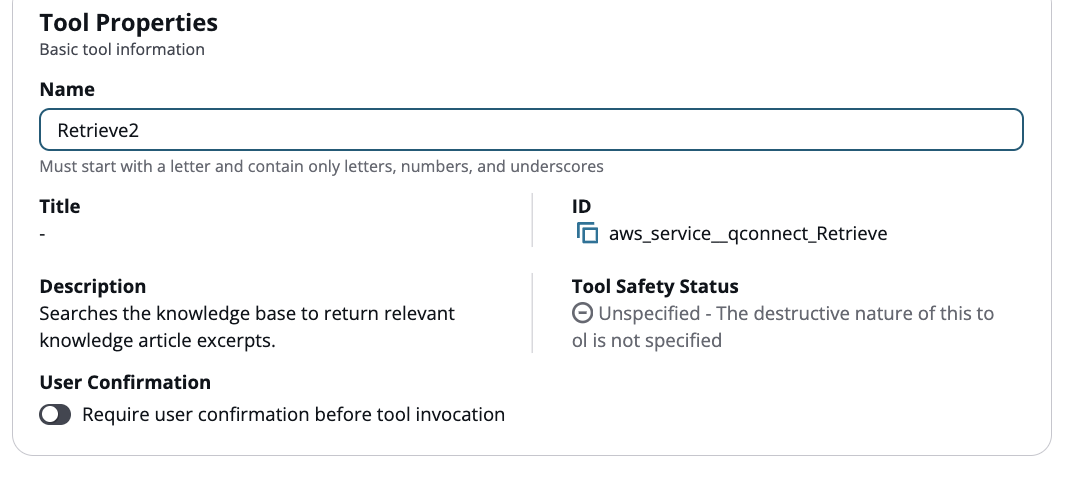
-
Configurez ensuite les instructions et les exemples de l'outil. La configuration varie en fonction de votre cas d'utilisation. Les sections suivantes couvrent deux scénarios : interroger simultanément toutes les bases de connaissances et interroger les bases de connaissances de manière sélective.
Interrogation simultanée de toutes les bases de connaissances
Utilisez cette configuration lorsque vous souhaitez que l'agent recherche simultanément toutes les bases de connaissances pour chaque requête.
Instructions de configuration de l'outil
-
Renseignez les instructions de l'outil en copiant les instructions et les exemples de l'outil Retrieve par défaut.
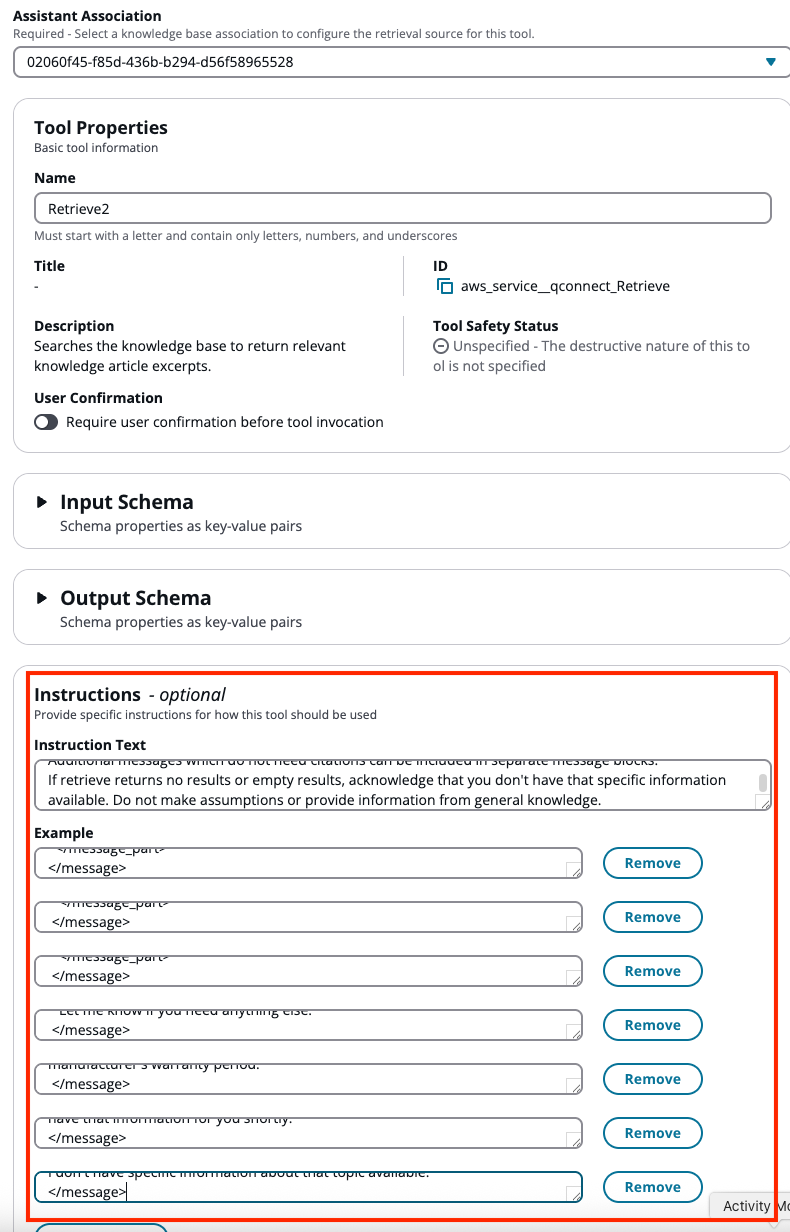
-
Cliquez sur le bouton Ajouter pour créer le nouvel outil de récupération. Votre liste d'outils devrait maintenant contenir le nouvel outil Retrieve.
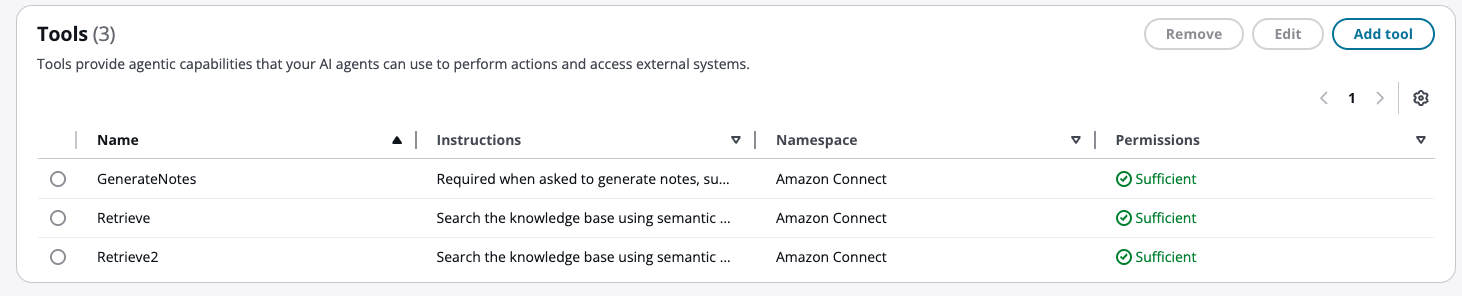
Vous disposez maintenant d'un deuxième outil de récupération. Pour utiliser tous les outils Retrieve ensemble, vous devez modifier l'invite avec des instructions pour les invoquer simultanément. Sans cette modification, un seul outil de récupération sera utilisé.
Mettre à jour votre invite d'invocation parallèle
-
Modifiez l'invite pour lui demander d'utiliser plusieurs outils de récupération. Les instructions d'orchestration par défaut ne peuvent pas être modifiées directement. Vous devez donc créer une copie avec vos modifications.
Créez une nouvelle invite en copiant l'invite d'orchestration par défaut qui correspond à votre cas d'utilisation. Dans cet exemple, nous effectuons une copie à partir de l' AgentAssistanceOrchestration invite.
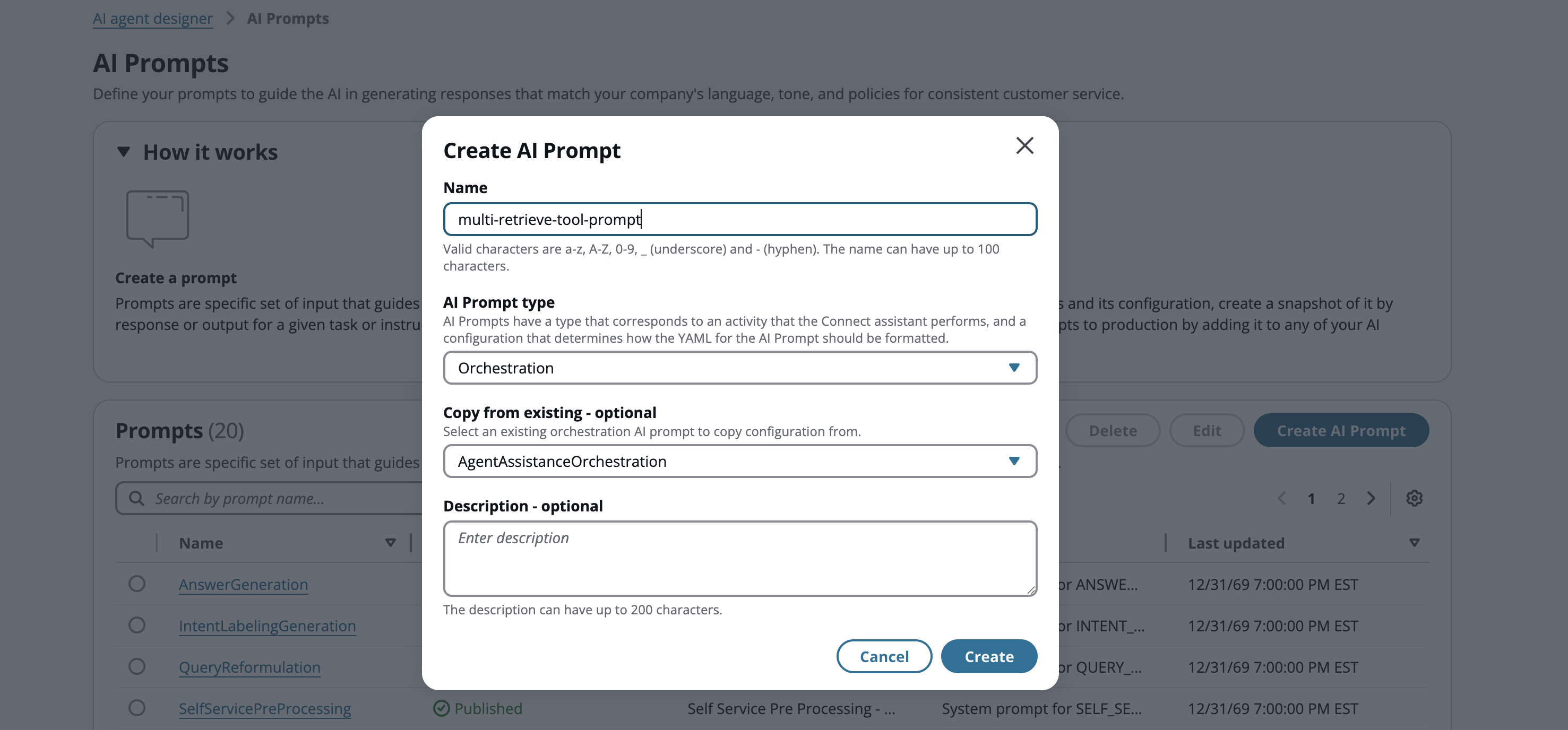
-
Cliquez sur le bouton Créer et vous serez redirigé vers une page où vous pourrez modifier l'invite.
-
Modifiez votre invite en fonction de votre type d'orchestration :
-
Pour les instructions d'orchestration de l'assistance aux agents :
Repérez la section des règles numérotées dans votre invite d'orchestration. Cette section commence par une ligne similaire à :
Your goal is to resolve the customer's issue while also being responsive. While responding, follow these important rules:Ajoutez la règle suivante comme dernière règle numérotée dans cette section :
CRITICAL - Multiple Retrieve Tools: When multiple Retrieve-type tools are available ([Retrieve], [Retrieve2]), you MUST invoke ALL of them simultaneously for any search request. Never use only one Retrieve tool when multiple are available-always select and invoke them together to ensure comprehensive results from all knowledge sources. -
Pour les instructions Self-Service d'orchestration :
Localisez la
core_behaviorsection. Ajoutez la règle suivante dans cette section :CRITICAL - Multiple Retrieve Tools: When multiple Retrieve-type tools are available ([Retrieve], [Retrieve2]), you MUST invoke ALL of them simultaneously for any search request. Never use only one Retrieve tool when multiple are available—always invoke them together to ensure comprehensive results from all knowledge sources.
Note
Remplacez les espaces réservés entre crochets par les noms réels de vos outils.
-
Interrogation sélective des bases de connaissances
Utilisez cette configuration lorsque vous souhaitez que l'agent sélectionne la base de connaissances appropriée en fonction du type de question ou du contexte.
Instructions de configuration des outils pour chaque base de connaissances
Contrairement à l'invocation parallèle, chaque outil Retrieve a besoin d'instructions distinctes qui décrivent à quel moment il doit être utilisé. Cela inclut l'outil de récupération par défaut : vous devez mettre à jour ses instructions pour le différencier des outils de récupération supplémentaires. Utilisez des noms descriptifs qui reflètent le contenu de chaque base de connaissances (par exemple RetrieveProducts, RetrievePolicies) pour aider le modèle à sélectionner l'outil approprié.
-
Pour chaque outil Retrieve, y compris l'outil par défaut, rédigez des instructions spécifiques qui décrivent le contenu de la base de connaissances associée et les circonstances dans lesquelles il convient de l'utiliser.
-
Cliquez sur le bouton Ajouter pour créer le nouvel outil de récupération. Votre liste d'outils devrait maintenant contenir le nouvel outil Retrieve.
Vous disposez maintenant d'un deuxième outil de récupération. Pour que l'agent sélectionne l'outil approprié en fonction du contexte, vous devez modifier l'invite contenant des instructions indiquant quand utiliser chaque outil.
Mettre à jour votre invite d'invocation conditionnelle
-
Modifiez l'invite pour lui demander de choisir l'outil de récupération approprié en fonction du contexte. Les instructions d'orchestration par défaut ne peuvent pas être modifiées directement. Vous devez donc créer une copie avec vos modifications.
Créez une nouvelle invite en copiant l'invite d'orchestration par défaut qui correspond à votre cas d'utilisation. Dans cet exemple, nous effectuons une copie à partir de l' AgentAssistanceOrchestration invite.
-
Cliquez sur le bouton Créer et vous serez redirigé vers une page où vous pourrez modifier l'invite.
-
Modifiez votre invite en fonction de votre type d'orchestration :
-
Pour les instructions d'orchestration de l'assistance aux agents :
Repérez la section des règles numérotées dans votre invite d'orchestration. Cette section commence par une ligne similaire à :
Your goal is to resolve the customer's issue while also being responsive. While responding, follow these important rules:Ajoutez la règle suivante comme dernière règle numérotée dans cette section :
CRITICAL - Retrieve Tool Selection: You have multiple Retrieve tools. Each queries a different knowledge base. You MUST select only ONE tool per question based on the topic. - [Retrieve] contains [description]. - [Retrieve2] contains [description]. Evaluate the question, match it to the most relevant tool, and invoke only that tool. -
Pour les instructions Self-Service d'orchestration :
Localisez la
core_behaviorsection. Ajoutez la règle suivante dans cette section :CRITICAL - Retrieve Tool Selection: You have multiple Retrieve tools. Each queries a different knowledge base. You MUST select only ONE tool per question based on the topic. - [Retrieve] contains [description]. - [Retrieve2] contains [description]. Evaluate the question, match it to the most relevant tool, and invoke only that tool.
Note
Remplacez les espaces réservés entre crochets par les noms, descriptions et exemples de questions de vos outils réels.
Meilleures pratiques pour une sélection précise des outils
La capacité du modèle à sélectionner le bon outil de récupération dépend de plusieurs facteurs : nom de l'outil, description de l'outil, exemples d'outils et instructions rapides. Suivez ces instructions :
-
Utilisez des noms d'outils descriptifs : les noms ressemblent RetrieveProducts ou RetrievePolicies aident le modèle à comprendre l'objectif de chaque outil.
-
Soyez précis dans les descriptions : évitez les descriptions vagues telles que « informations générales ». Répertoriez les sujets, les types de documents ou les catégories de questions spécifiques traités par chaque base de connaissances.
-
Ajouter des exemples de questions : incluez des exemples de questions dans les instructions de l'outil pour aider le modèle à comprendre les cas d'utilisation prévus.
-
Évitez les chevauchements : assurez-vous que les noms, les descriptions et les exemples des outils s'excluent mutuellement. Le chevauchement du contenu peut entraîner des choix incohérents du modèle.
-
Adaptez la terminologie à la langue de l'utilisateur : utilisez les mêmes mots et expressions que ceux que vos utilisateurs utilisent habituellement, et pas uniquement de la terminologie interne ou technique.
Votre cas d'utilisation peut nécessiter des modifications rapides supplémentaires au-delà des exemples fournis ici.
-
Segmentation du contenu
La segmentation du contenu vous permet de baliser le contenu de votre base de connaissances et de filtrer les résultats de récupération en fonction de ces balises. Lorsque votre outil LLM interroge la base de connaissances, il peut spécifier des balises pour récupérer uniquement le contenu correspondant à ces balises, permettant ainsi des réponses ciblées à partir de sous-ensembles de contenu spécifiques.
Note
La segmentation du contenu n'est pas disponible avec le type de source de données Web Crawler.
Marquage du contenu par type de source de données
Le processus de balisage du contenu varie en fonction du type de source de données.
S3, Salesforce SharePoint, Zendesk et ServiceNow
Après avoir créé votre base de connaissances, vous pouvez appliquer des balises à des éléments de contenu individuels à des fins de segmentation. Les balises sont appliquées au niveau du contenu, ce qui signifie que chaque élément de contenu doit être étiqueté individuellement.
Pour baliser le contenu, utilisez l'TagResource API Amazon Connect. Cette API vous permet d'ajouter par programmation des balises au contenu de la base de connaissances, qui peuvent ensuite être utilisées pour le filtrage par segmentation du contenu lors de la récupération.
Pour des exemples de balisage de contenu, consultez l'atelier de segmentation du contenu
Utilisation de balises dans l'outil Retrieve
Une fois que votre contenu est balisé, vous pouvez filtrer les résultats de récupération en spécifiant des filtres de balises dans la configuration de l'outil de récupération.
-
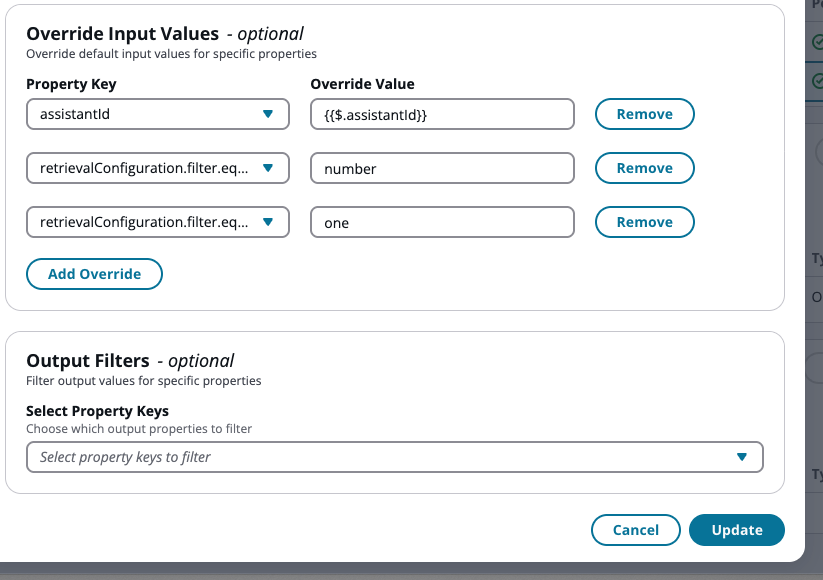
Dans la configuration de l'outil de récupération, accédez à la section Remplacer les valeurs d'entrée.
-
Ajoutez des paires clé-valeur pour définir votre filtre de balises. Vous avez besoin de deux remplacements pour filtrer en fonction d'une seule balise. Dans cet exemple, nous utilisons
equalscomme opérateur de filtre :-
Définissez la clé de propriété sur
retrievalConfiguration.filter.equals.keyavec la valeur comme nom de balise (par exemple,number).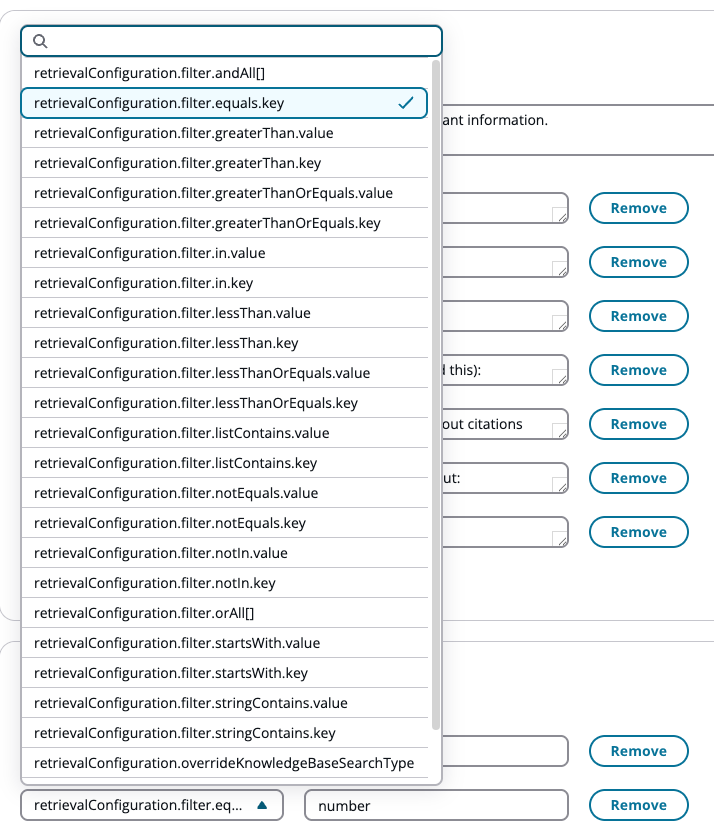
-
Définissez la clé de propriété sur
retrievalConfiguration.filter.equals.valueavec la valeur comme valeur de balise (par exemple,one).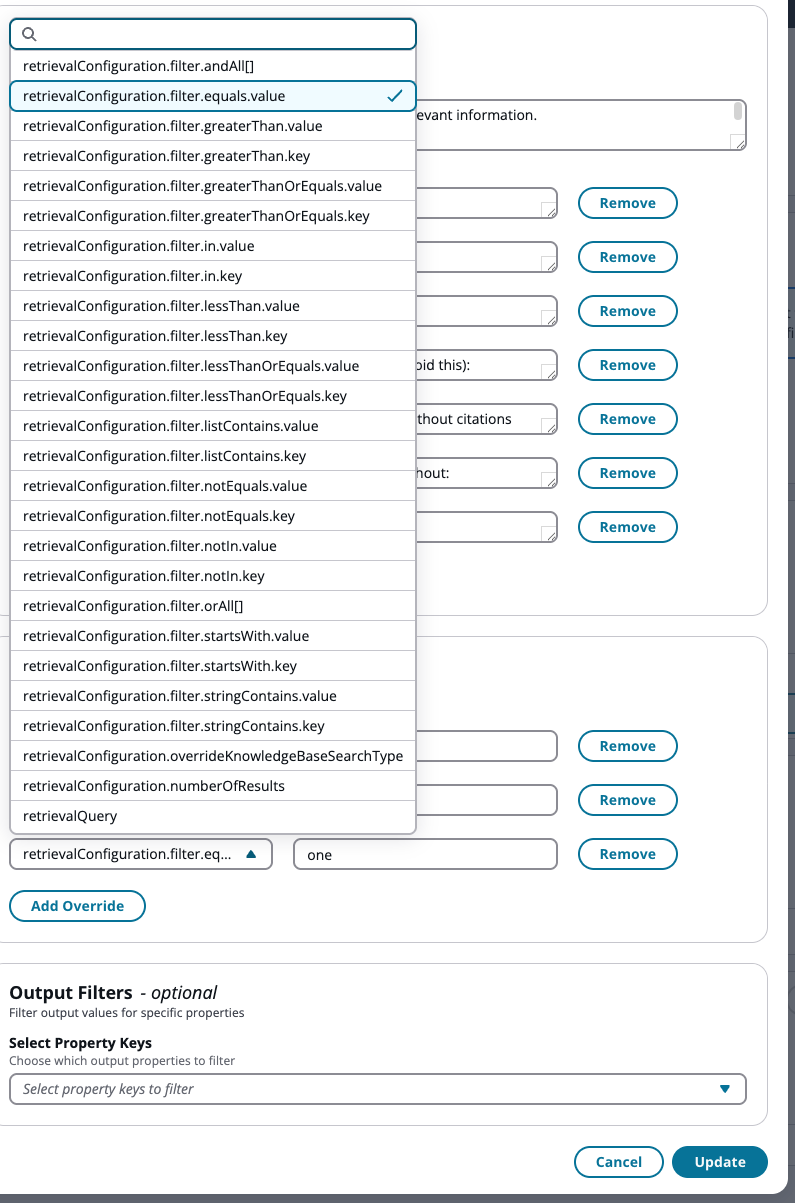
-
Vous pouvez utiliser n'importe quelle configuration de filtre commençant par retrievalConfiguration.filter pour définir vos critères de filtrage des balises.
Base de connaissances Bedrock
Pour les sources de données de la base de connaissances Bedrock, le contenu n'est pas stocké en tant que ressources Amazon Connect. Le balisage via l' TagResource API n'est donc pas disponible. Vous devez plutôt définir des champs de métadonnées directement sur les sources de données de votre base de connaissances Bedrock.
Pour les sources de données S3, consultez la section Champs de métadonnées du document dans le guide de l'utilisateur du connecteur de source de données Amazon Bedrock S3.
Pour les autres types de sources de données, consultez la section Transformation personnalisée lors de l'ingestion dans la documentation Amazon Bedrock.
Utilisation des champs de métadonnées dans l'outil Retrieve
Les bases de connaissances Bedrock fournissent automatiquement des champs de métadonnées intégrés à tous les fichiers. Vous pouvez utiliser ces champs pour filtrer les résultats de récupération dans l'outil Retrieve en utilisant la même méthode de configuration que dans l'exemple ci-dessus.
Pour récupérer les résultats uniquement à partir d'une source de données spécifique de votre base de connaissances Bedrock, configurez les remplacements de filtres comme suit :
-
retrievalConfiguration.filter.equals.key=x-amz-bedrock-kb-data-source-id -
retrievalConfiguration.filter.equals.value=[your-data-source-id]
Cela filtre l'outil Retrieve pour récupérer les résultats uniquement à partir de cette source de données spécifique. Vous pouvez également filtrer en fonction des champs de métadonnées personnalisés que vous avez définis dans vos sources de données Bedrock en utilisant la même configuration de remplacement.
Ajoutez des données de citation à votre trace d'agent AI
Lorsque votre agent d'intelligence artificielle utilise une base de connaissances pour répondre à des questions, vous pouvez capturer des données de citation indiquant quel contenu de la base de connaissances a été référencé. Ces données comprennent :
-
contentId : identifiant de l'élément de contenu spécifique référencé
-
title : le titre du contenu référencé (par exemple, « Amazon Connect Overview »)
-
knowledge BaseId — l'identifiant de la base de connaissances utilisée
-
knowledge BaseArn — l'ARN de la base de connaissances utilisée
Les données de citation de cette base de connaissances sont disponibles via l' ListSpans API et l'AI Agent Trace. Pour en savoir plus, consultez ListSpanset AI Agent Traces.
Note
Si vous utilisez l'assistance d'un agent, les données de citation sont automatiquement incluses et aucune configuration supplémentaire n'est requise. Les étapes suivantes s'appliquent uniquement aux instructions d'orchestration en libre-service.
Mettez à jour votre invite en libre-service pour inclure des citations
-
Pour activer les données de citation, vous devez mettre à jour le bloc d'instructions de l'outil Retrieve dans votre invite d'orchestration en libre-service. Cela indique au modèle d'inclure des références aux sources dans ses réponses en utilisant le format requis.
-
Créez une copie de votre invite d'orchestration en libre-service par défaut (les invites par défaut ne peuvent pas être modifiées directement).
-
Dans votre invite copiée, remplacez le bloc d'instructions de l'outil Retrieve par le suivant :
instruction: instruction: |- Search the knowledge base using semantic search to find relevant information. Use the results of the RETRIEVE tool to provide an informed answer to the customer's query. When summarizing retrieve tool results, you MUST include source citations using the format shown in the good examples below. MUST include a <sources> block with the sourceId values from the Retrieve result inside every <message_part> that uses retrieved content. MUST use the exact sourceId string returned by the Retrieve tool. Do not modify, truncate, or fabricate sourceId values. MUST include source citations for ALL information taken from retrieve results. If a message_part is purely conversational (greetings, clarifying questions, hand-offs) and does not use retrieved content, omit the <sources> block. If retrieve returns no results or empty results, acknowledge that you don't have that specific information available. Do not make assumptions or provide information from general knowledge. examples: - |- Good example - single message part with one source: <message> <message_part> <text>Your warranty covers parts replacement for any manufacturing defects during the first year.</text> <sources> <sourceId>warranty_policy_2024</sourceId> </sources> </message_part> </message> - |- Good example - multiple sources contributing to one answer: <message> <message_part> <text>Our check-in time is 3 PM and checkout is 11 AM. Late checkout is available for an additional fee.</text> <sources> <sourceId>checkin_policy</sourceId> <sourceId>fees_addendum</sourceId> </sources> </message_part> </message> - |- Good example - greeting with no retrieval: <message> <message_part> <text>Hello! How can I help you today?</text> </message_part> </message> - |- Bad example - retrieved content with no sources block (avoid this): <message> <message_part> <text>We offer extended warranty coverage beyond the manufacturer's warranty period.</text> </message_part> </message> - |- Bad example - text outside <message_part> (avoid this): <message> <message_part> <text>Your warranty covers parts replacement.</text> <sources> <sourceId>warranty_policy_2024</sourceId> </sources> </message_part> Let me know if you need anything else. </message> - |- Example for no results: <message> <message_part> <text>I don't have specific information about that topic available.</text> </message_part> </message>
-
Enregistrez votre invite et associez-la à votre agent d'intelligence artificielle.
Agents vocaux
Le <sources> bloc est constitué de métadonnées et n'est pas prononcé à haute voix. Cela n'a aucune incidence sur ce que l'appelant entend.
Comment vérifier
Après avoir mis à jour votre demande, placez un contact de test et confirmez :
-
L'agent répond correctement à la question.
-
Vérifiez la réponse de ListSpans l'API pour cette session. La base de connaissances utilisée pour répondre doit apparaître sous forme de citations dans les ListSpans détails. Pour en savoir plus ListSpans, consultez la section ListSpans API.
