Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
GitHub repositorios
Para iniciar un trabajo de formación, se utilizan archivos de dos GitHub repositorios distintos:
Estos repositorios contienen componentes esenciales para iniciar, administrar y personalizar los procesos de entrenamiento de los modelos de lenguaje de gran tamaño (LLM). Los scripts de los repositorios se utilizan para configurar y ejecutar los trabajos de entrenamiento de sus LLM.
HyperPod repositorio de recetas
Usa el repositorio de SageMaker HyperPod recetas
-
main.py: Este archivo sirve como punto de entrada principal para iniciar el proceso de envío de un trabajo de formación a un clúster o a un trabajo de SageMaker formación. -
launcher_scripts: este directorio contiene una colección de scripts de uso común diseñados para facilitar el proceso de entrenamiento de varios modelos de lenguajes de gran tamaño (LLM). -
recipes_collection: esta carpeta contiene una recopilación de fórmulas de LLM predefinidas proporcionadas por los desarrolladores. Los usuarios pueden aprovechar estas fórmulas, además de sus datos personalizados, para entrenar los modelos LLM adaptados a sus requisitos específicos.
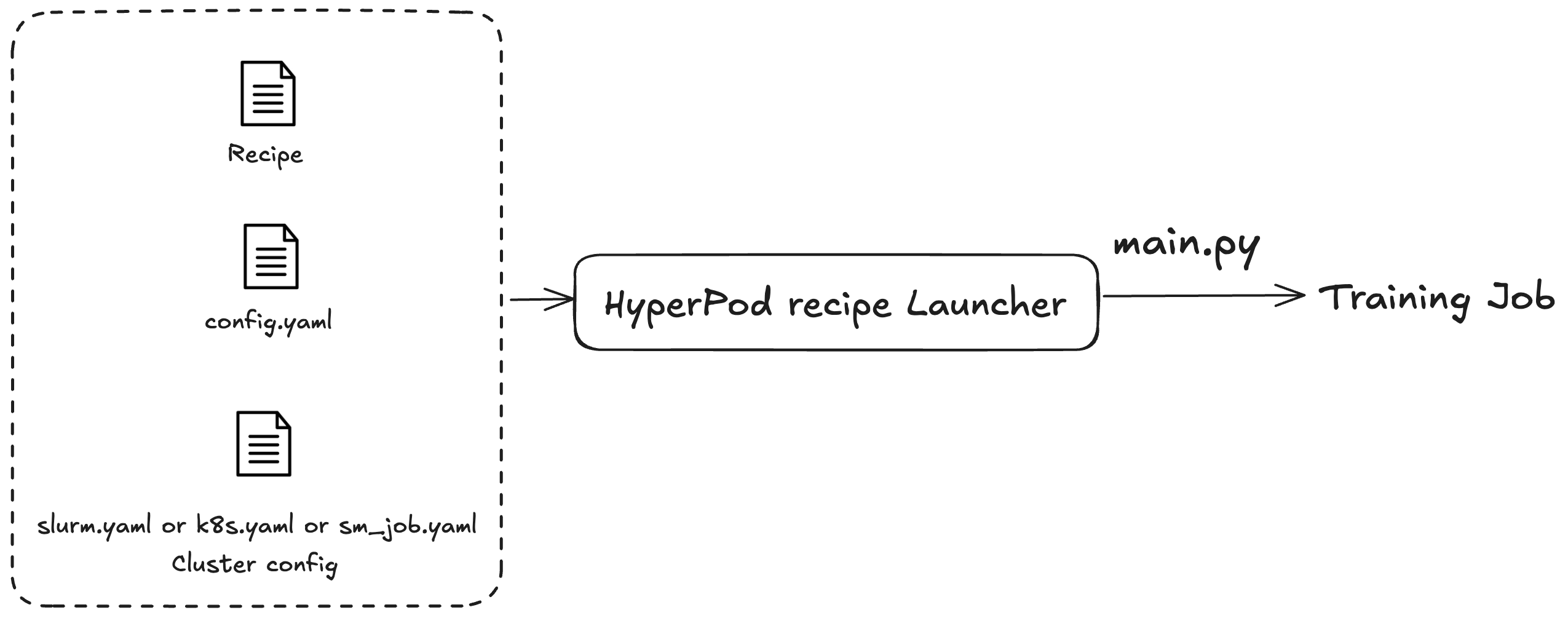
Las SageMaker HyperPod recetas se utilizan para iniciar tareas de formación o de perfeccionamiento. Independientemente del clúster que utilice, el proceso de envío del trabajo es el mismo. Por ejemplo, puede usar el mismo script para enviar un trabajo a un clúster de Slurm o Kubernetes. El lanzador distribuye un trabajo de entrenamiento en función de tres archivos de configuración:
-
Configuración general (
config.yaml): incluye ajustes comunes, como los parámetros predeterminados o las variables de entorno que se utilizan en el trabajo de entrenamiento. -
Configuración de clústeres (clúster): para trabajos de entrenamiento que únicamente utilizan clústeres. Si va a enviar un trabajo de entrenamiento a un clúster de Kubernetes, es posible que tenga que especificar información como el volumen, la etiqueta o la política de reinicio. En el caso de los clústeres de Slurm, es posible que tenga que especificar el nombre del trabajo de Slurm. Todos los parámetros están relacionados con el clúster específico que está utilizando.
-
Receta (recetas): las fórmulas contienen la configuración de su trabajo de entrenamiento, como los tipos de modelo, el grado de partición o las rutas de los conjuntos de datos. Por ejemplo, puede especificar Llama como modelo de entrenamiento y entrenarlo con técnicas de paralelismo de datos o modelos, como el paralelismo de datos totalmente particionados (FSDP, por sus siglas en inglés), en ocho máquinas. También puede especificar diferentes frecuencias o rutas de puntos de comprobación para su trabajo de entrenamiento.
Después de especificar la fórmula, ejecute el script del lanzador para especificar un trabajo de entrenamiento integral en un clúster según las configuraciones hasta el punto de entrada main.py. Cada fórmula que utilice tiene scripts de intérprete de comandos asociados ubicados en la carpeta launch_scripts. Estos ejemplos le guían a la hora de enviar e iniciar trabajos de entrenamiento. La siguiente figura ilustra cómo un lanzador de SageMaker HyperPod recetas envía un trabajo de formación a un clúster en función de lo anterior. Actualmente, el lanzador de SageMaker HyperPod recetas está construido sobre el Nvidia NeMo Framework Launcher. Para obtener más información, consulte la Guía del NeMo lanzador
HyperPod repositorio de adaptadores de recetas
El adaptador SageMaker HyperPod de formación es un marco de formación. Puede utilizarlo para administrar todo el ciclo de vida de sus trabajos de entrenamiento. Utilice el adaptador para distribuir el entrenamiento previo o el refinamiento de sus modelos entre varias máquinas. El adaptador utiliza diferentes técnicas de paralelismo para distribuir el entrenamiento. También se encarga de la implementación y la administración del almacenamiento de los puntos de comprobación. Para obtener más información, consulte Configuración avanzada.
Utilice el repositorio de adaptadores de SageMaker HyperPod recetas
-
src: Este directorio contiene la implementación de la formación en modelos de Large-scale lenguaje (LLM) y abarca diversas funciones, como el paralelismo de modelos, la formación de precisión mixta y la gestión de puntos de control. -
examples: esta carpeta proporciona una colección de ejemplos que muestran cómo crear un punto de entrada para el entrenamiento de un modelo de LLM y sirve de guía práctica para los usuarios.
