Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Minimización de la sobrecarga de planificación
Como se analiza en Temas clave de Apache Spark, el controlador de Spark genera el plan de ejecución. Según ese plan, las tareas se asignan al ejecutor de Spark para su procesamiento distribuido. Sin embargo, el controlador de Spark puede convertirse en un cuello de botella si hay una gran cantidad de archivos pequeños o si el AWS Glue Data Catalog contiene una gran cantidad de particiones. Para identificar una sobrecarga de planificación elevada, evalúe las siguientes métricas.
CloudWatch métricas
Compruebe Carga de la CPU y Utilización de la memoria en las siguientes situaciones:
-
Los valores de Carga de la CPU y Utilización de la memoria del controlador de Spark se registran como altos. Normalmente, el controlador de Spark no procesa los datos, por lo que la carga de la CPU y la utilización de la memoria no aumentan. Sin embargo, si el origen de datos de Amazon S3 tiene demasiados archivos pequeños, la enumeración de todos los objetos de S3 y la administración de un gran número de tareas puede provocar una utilización elevada de los recursos.
-
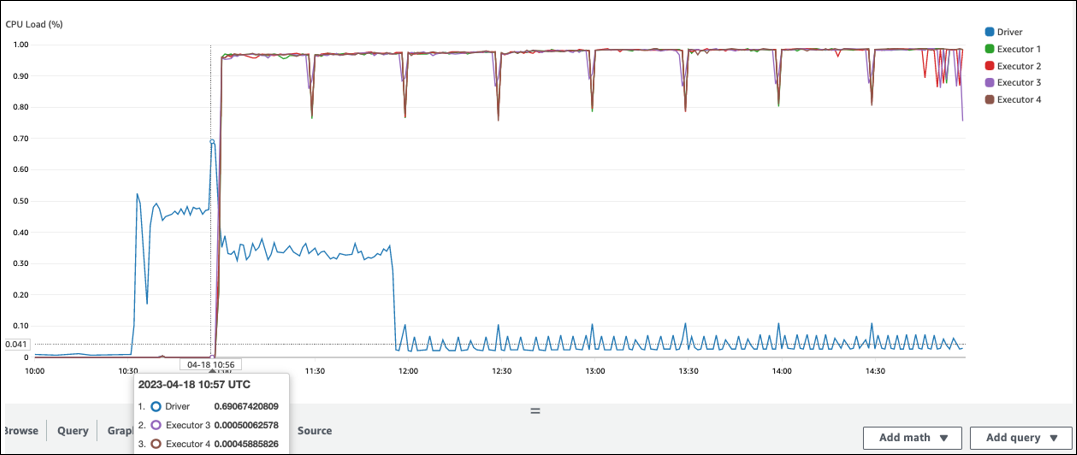
Hay un largo intervalo antes de que comience el procesamiento en el ejecutor de Spark. En la siguiente captura de pantalla de ejemplo, la carga de CPU del ejecutor de Spark es demasiado baja hasta las 10:57, a pesar de que el AWS Glue trabajo comenzó a las 10:00. Esto indica que es posible que el controlador de Spark esté tardando mucho en generar un plan de ejecución. En este ejemplo, recuperar la gran cantidad de particiones del Catálogo de datos y enumerar la gran cantidad de archivos pequeños en el controlador de Spark lleva mucho tiempo.
IU de Spark
En la pestaña Trabajo de la IU de Spark, puede ver la hora de envío. En el siguiente ejemplo, el controlador de Spark inició el trabajo 0 a las 10:56:46, aunque el trabajo comenzó a las 10:00:00. AWS Glue

También puede ver las tareas (para todas las etapas): Succeeded/Total tiempo en la pestaña Trabajo. En este caso, el número de tareas se registra como 58100. Como se explica en la sección de Amazon S3 de la página Paralelización de las tareas, la cantidad de tareas corresponde aproximadamente a la cantidad de objetos de S3. Esto significa que hay unos 58 100 objetos en Amazon S3.
Para obtener más información sobre este trabajo y su cronograma, consulte la pestaña Etapa. Si observa un cuello de botella con el controlador de Spark, considere las siguientes soluciones:
-
Si Amazon S3 tiene demasiados archivos, consulte las instrucciones sobre el paralelismo excesivo de la sección Demasiadas particiones de la página Paralelización de las tareas.
-
Si Amazon S3 tiene demasiadas particiones, consulte las instrucciones sobre la partición excesiva de la sección Demasiadas particiones de Amazon S3 de la página Reducción de la cantidad de análisis de datos. Habilite los índices de particiones de AWS Glue si hay muchas particiones para reducir la latencia a la hora de recuperar los metadatos de las particiones del Catálogo de datos. Para obtener más información, consulte Mejorar el rendimiento de las consultas mediante índices de AWS Glue partición
. -
Si JDBC tiene demasiadas particiones, reduzca el valor de
hashpartition. -
Si DynamoDB tiene demasiadas particiones, reduzca el valor de
dynamodb.splits. -
Si los trabajos de transmisión tienen demasiadas particiones, reduzca el número de particiones.
