Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Automatice la implementación de lagos de Supply Chain datos en una configuración de múltiples repositorios
Keshav Ganesh, Amazon Web Services
Resumen
Este patrón proporciona un enfoque automatizado para implementar y administrar lagos de AWS Supply Chain datos mediante capacidades de integración continua y despliegue continuo () de múltiples repositorios. CI/CD) pipeline. It demonstrates two deployment methods: automated deployment using GitHub Actions workflows, or manual deployment using Terraform directly. Both approaches use Terraform for infrastructure as code (IaC), with the automated method adding GitHub Actions and JFrog Artifactory for enhanced CI/CD
La solución aprovecha Supply Chain y Amazon Simple Storage Service (Amazon S3) para establecer la infraestructura del lago de datos y, al mismo tiempo, utiliza cualquiera de los dos métodos de implementación para automatizar la configuración y la creación de recursos. AWS Lambda Esta automatización elimina los pasos de configuración manual y garantiza la uniformidad de las implementaciones en todos los entornos. Además, Supply Chain elimina la necesidad de contar con una amplia experiencia en extracción, transformación y carga (ETL) y puede proporcionar información y análisis impulsados por Amazon Quick Sight.
Al implementar este patrón, las organizaciones pueden reducir el tiempo de implementación, mantener la infraestructura como código y administrar los lagos de datos de la cadena de suministro mediante un proceso automatizado y controlado por versiones. El enfoque de múltiples repositorios proporciona un control de acceso detallado y permite el despliegue independiente de diferentes componentes. Los equipos pueden elegir el método de implementación que mejor se adapte a sus herramientas y procesos existentes.
Requisitos previos y limitaciones
Requisitos previos
Asegúrese de que lo siguiente esté instalado en su máquina local:
AWS Command Line Interface (AWS CLI) versión 2
Terraform v1.12
o posterior
Asegúrese de que se cuente con lo siguiente antes de la implementación:
Un activo Cuenta de AWS.
Una nube privada virtual (VPC) con dos subredes privadas Cuenta de AWS en Región de AWS la que elija.
Permisos suficientes para el rol AWS Identity and Access Management (IAM) utilizado para la implementación en los siguientes servicios:
Supply Chain — Se prefiere Full Access para implementar sus componentes, como conjuntos de datos y flujos de integración, además de acceder a ellos desde. Consola de administración de AWS
Amazon CloudWatch Logs: para crear y administrar grupos de CloudWatch registros.
Amazon Elastic Compute Cloud (Amazon EC2): para grupos de seguridad de Amazon EC2 y puntos de conexión de Amazon Virtual Private Cloud (Amazon VPC).
Amazon EventBridge : para uso de Supply Chain.
IAM: para crear funciones AWS Lambda de servicio.
AWS Key Management Service (AWS KMS) — Para acceder al depósito AWS KMS keys de artefactos de Amazon S3 y al depósito Supply Chain provisional de Amazon S3.
AWS Lambda — Para crear las funciones Lambda que despliegan los Supply Chain componentes.
Amazon S3: para acceder al depósito de artefactos de Amazon S3, al depósito de registro de acceso al servidor y al Supply Chain depósito provisional. Si utiliza la implementación manual, también necesitará permisos para el depósito de artefactos Terraform de Amazon S3.
Amazon VPC: para crear y administrar una VPC.
Si prefiere utilizar los flujos de trabajo de GitHub Actions para la implementación, haga lo siguiente:
Configure OpenID Connect (OIDC)
para el rol de IAM con los permisos mencionados anteriormente. Cree un rol de IAM con permisos similares para acceder al. Consola de administración de AWS Para obtener más información, consulte Crear un rol para conceder permisos a un usuario de IAM en la documentación de IAM.
Si prefiere realizar una implementación manual, haga lo siguiente:
Cree un usuario de IAM para que asuma la función de IAM con los permisos mencionados anteriormente. Para obtener más información, consulte Crear un rol para conceder permisos a un usuario de IAM en la documentación de IAM.
Asuma el rol en su terminal local.
Si prefieres usar los flujos de trabajo de GitHub Actions para la implementación, configura lo siguiente:
Una cuenta JFrog Artifactory
para obtener el nombre de host, el nombre de usuario y el token de acceso al inicio de sesión. Una clave de JFrog proyecto y un repositorio
para almacenar artefactos.
Limitaciones
La Supply Chain instancia no admite técnicas complejas de transformación de datos.
Supply Chain es la más adecuada para los dominios de la cadena de suministro porque proporciona análisis e información integrados. Para cualquier otro dominio, se Supply Chain puede utilizar como almacén de datos como parte de la arquitectura del lago de datos.
Es posible que sea necesario mejorar las funciones Lambda utilizadas en esta solución para gestionar los reintentos de API y la administración de memoria en una implementación a escala de producción.
Algunas Servicios de AWS no están disponibles en todos. Regiones de AWS Para obtener información sobre la disponibilidad en regiones, consulte AWS Services by Region
. Para ver los puntos de conexión específicos, consulte Service endpoints and quotas y elija el enlace del servicio.
Arquitectura
Puedes implementar esta solución mediante flujos de trabajo de GitHub Actions automatizados o manualmente con Terraform.
Despliegue automatizado con Actions GitHub
En el siguiente diagrama, se muestra la opción de despliegue automatizado que utiliza los flujos de trabajo de GitHub Actions. JFrog Artifactory se utiliza para la gestión de artefactos. Almacena la información y los resultados de los recursos para utilizarlos en una implementación de varios repositorios.

Despliegue manual con Terraform
El siguiente diagrama muestra la opción de despliegue manual a través de Terraform. En lugar de JFrog Artifactory, Amazon S3 se utiliza para la administración de artefactos.
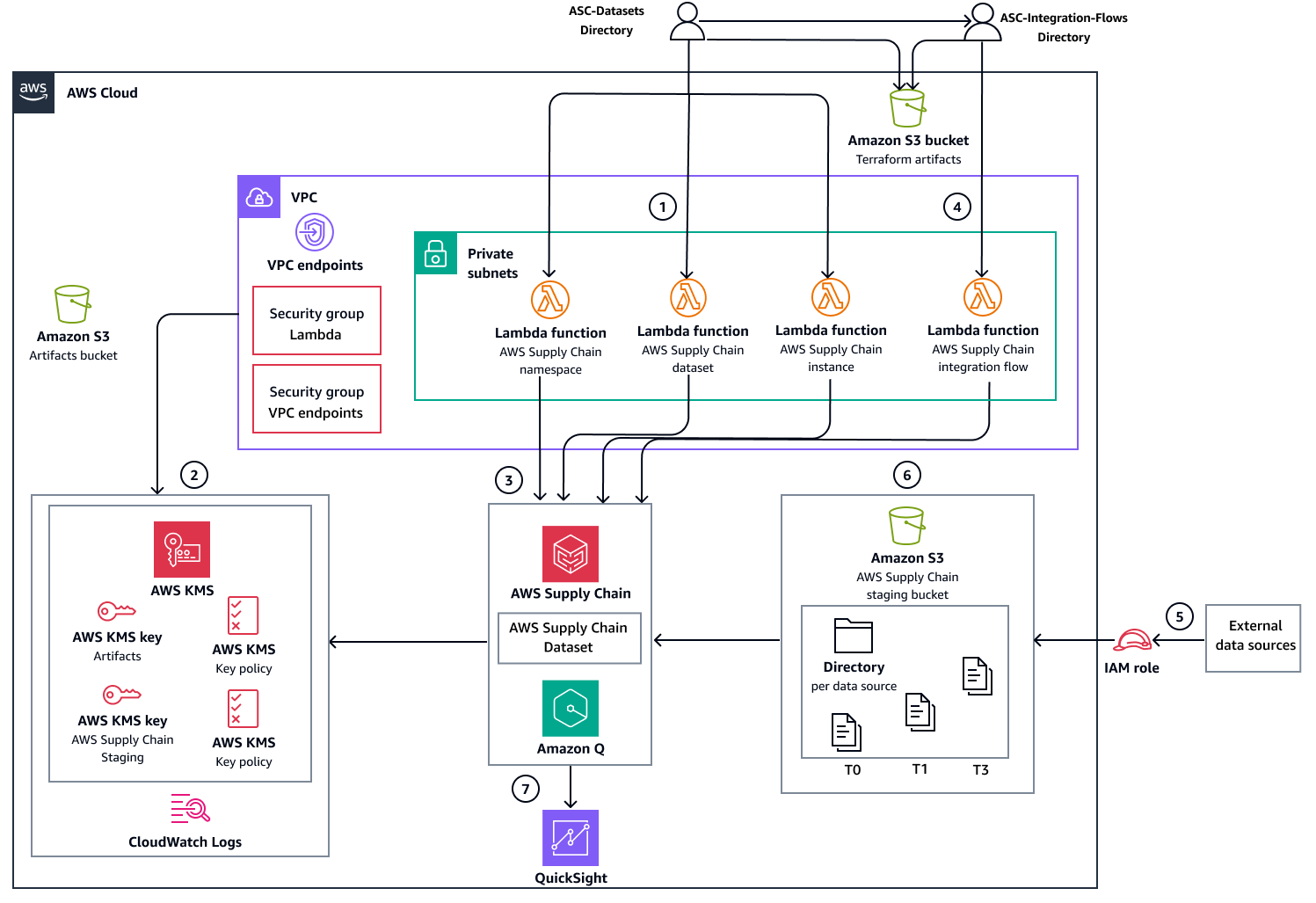
Flujo de trabajo de una implementación
Los diagramas muestran el siguiente flujo de trabajo:
Implemente conjuntos de datos de Supply Chain servicios, infraestructura y bases de datos mediante uno de los siguientes métodos de implementación:
Implementación automatizada: utiliza los flujos de trabajo de GitHub Actions para organizar todos los pasos de la implementación y utiliza JFrog Artifactory para la gestión de artefactos.
Implementación manual: ejecuta los comandos de Terraform directamente para cada paso de la implementación y usa Amazon S3 para la administración de artefactos.
Cree los AWS recursos de apoyo necesarios para el funcionamiento del Supply Chain servicio:
Puntos de enlace y grupos de seguridad de Amazon VPC
AWS KMS keys
CloudWatch Registros, grupos de registros
Cree e implemente los siguientes recursos de infraestructura:
Funciones Lambda que administran (crean, actualizan y eliminan) la instancia de Supply Chain servicio, los espacios de nombres y los conjuntos de datos.
Supply Chain organizar un bucket de Amazon S3 para la ingesta de datos
Implemente la función Lambda que gestiona los flujos de integración entre el depósito provisional y los conjuntos de datos. Supply Chain Una vez completada la implementación, los pasos restantes del flujo de trabajo gestionan la ingesta y el análisis de los datos.
Configure la ingesta de datos de origen en el bucket Supply Chain provisional de Amazon S3.
Una vez que se añaden los datos al Supply Chain bucket provisional de Amazon S3, el servicio activa automáticamente el flujo de integración de los Supply Chain conjuntos de datos.
Supply Chain se integra con Quick Sight Analytics para crear paneles basados en los datos ingeridos.
Tools (Herramientas)
Servicios de AWS
Amazon CloudWatch Logs le ayuda a centralizar los registros de todos sus sistemas y aplicaciones Servicios de AWS para que pueda supervisarlos y archivarlos de forma segura.
AWS Command Line Interface (AWS CLI) es una herramienta de código abierto que le ayuda a interactuar Servicios de AWS mediante los comandos de su consola de línea de comandos.
Amazon Elastic Compute Cloud (Amazon EC2) brinda capacidad de computación escalable en la Nube de AWS. Puede lanzar tantos servidores virtuales como necesite y escalarlos o reducirlos con rapidez.
Amazon EventBridge es un servicio de bus de eventos sin servidor que le ayuda a conectar sus aplicaciones con datos en tiempo real de diversas fuentes. Por ejemplo, AWS Lambda funciones, puntos de enlace de invocación HTTP que utilizan destinos de API o buses de eventos en otros. Cuentas de AWS
AWS Identity and Access Management (IAM) le ayuda a administrar de forma segura el acceso a sus AWS recursos al controlar quién está autenticado y autorizado a usarlos.
AWS IAM Identity Centerle ayuda a gestionar de forma centralizada el acceso mediante el inicio de sesión único (SSO) a todas sus aplicaciones y a las de la nube. Cuentas de AWS
AWS Key Management Service (AWS KMS) le ayuda a crear y controlar claves criptográficas para proteger sus datos.
AWS Lambda es un servicio de computación que ayuda a ejecutar código sin necesidad de aprovisionar ni administrar servidores. Ejecuta el código solo cuando es necesario y amplía la capacidad de manera automática, por lo que solo pagará por el tiempo de procesamiento que utilice.
Amazon Q in Supply Chain es un asistente de IA generativa interactivo que le ayuda a gestionar su cadena de suministro de forma más eficiente mediante el análisis de los datos de su lago de Supply Chain datos.
Amazon QuickSight es un servicio de inteligencia empresarial (BI) a escala de la nube que lo ayuda a visualizar, analizar y generar informes de sus datos en un único panel.
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos basado en la nube que lo ayuda a almacenar, proteger y recuperar cualquier cantidad de datos.
Supply Chaines una aplicación gestionada basada en la nube que se puede utilizar como almacén de datos en las organizaciones para los dominios de la cadena de suministro, que se puede utilizar para generar información y realizar análisis de los datos ingeridos.
Amazon Virtual Private Cloud (Amazon VPC) le ayuda a lanzar AWS recursos en una red virtual que haya definido. Esa red virtual es similar a la red tradicional que utiliza en su propio centro de datos, con los beneficios de usar la infraestructura escalable de AWS. Un punto de conexión de Amazon VPC es un dispositivo virtual que le ayuda a conectar de forma privada su VPC a una red compatible Servicios de AWS sin necesidad de una pasarela de Internet, un dispositivo NAT, una conexión VPN o una conexión. AWS Direct Connect
Otras herramientas
GitHub Actions
es una plataforma de integración y entrega continuas (CI/CD) que está estrechamente integrada con los repositorios. GitHub Puedes usar GitHub Actions para automatizar tu proceso de creación, prueba e implementación. HashiCorp Terraform
es una herramienta de infraestructura como código (IaC) que te ayuda a crear y administrar recursos locales y en la nube. JFrog Artifactory
proporciona end-to-end automatización y administración de archivos binarios y artefactos a través del proceso de entrega de la aplicación. Python
es un lenguaje de programación informático de uso general. Este patrón usa Python para que el código de la AWS función interactúe con Supply Chain .
Prácticas recomendadas
Mantenga la mayor seguridad posible al implementar este patrón. Como se indica en los requisitos previos, asegúrese de tener una nube privada virtual (VPC) con dos subredes privadas en Región de AWS la que Cuenta de AWS elija.
Utilice claves administradas por el AWS KMS cliente siempre que sea posible y concédales permisos de acceso limitados.
Para configurar las funciones de IAM con el acceso mínimo necesario para ingerir datos según este patrón, consulte Proteger la ingestión de datos desde los sistemas de origen a Amazon S3
en el repositorio de este patrón.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Clonar el repositorio. | Para clonar el repositorio de este patrón, ejecute el comando siguiente en la estación de trabajo local:
| AWS DevOps |
(Opción automatizada) Verifique los requisitos previos para la implementación. | Asegúrese de que se hayan completado los requisitos previos para la implementación automática. | Propietario de la aplicación |
(Opción manual) Prepárese para la implementación de los Supply Chain conjuntos de datos. | Para ir al
Para asumir el rol ARN que se creó en los requisitos previos, ejecute el siguiente comando:
Para configurar y exportar las variables de entorno, ejecute los siguientes comandos:
| AWS DevOps |
(Opción manual) Prepárese para gestionar los flujos de Supply Chain integración durante la implementación. | Para ir al
Para asumir el rol ARN que se creó anteriormente, ejecute el siguiente comando:
Para configurar y exportar las variables de entorno, ejecute los siguientes comandos:
| Propietario de la aplicación |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Copia el | Para copiar el
| AWS DevOps |
Configure el | Para configurarlo
| AWS DevOps |
Configure el nombre de la rama en el archivo de flujo de trabajo .github. | Configura el nombre de la rama en el archivo de flujo de trabajo de implementación
| Propietario de la aplicación |
Configure GitHub los entornos y configure los valores del entorno. | Para configurar GitHub los entornos de su GitHub organización, siga las instrucciones de Configuración de GitHub los entornos Para configurar los valores del entorno en los | Propietario de la aplicación |
Activa el flujo de trabajo. | Para introducir los cambios en su GitHub organización y activar el flujo de trabajo de implementación, ejecute el siguiente comando:
| AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Copia el | Para copiar el
| AWS DevOps |
Configure el | Para configurar el
| AWS DevOps |
Configure el nombre de la rama en el archivo de flujo de trabajo .github. | Configura el nombre de la rama en el archivo de flujo de trabajo de implementación
| Propietario de la aplicación |
Configure GitHub los entornos y configure los valores del entorno. | Para configurar GitHub los entornos de su GitHub organización, siga las instrucciones de Configuración de GitHub los entornos Para configurar los valores del entorno en los | Propietario de la aplicación |
Activa el flujo de trabajo. | Para introducir los cambios en su GitHub organización y activar el flujo de trabajo de implementación, ejecute el siguiente comando:
| AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Vaya al directorio | Para ir al
| AWS DevOps |
Configure el bucket Amazon S3 del estado de Terraform. | Para configurar el bucket Amazon S3 del estado de Terraform, utilice el siguiente script:
| AWS DevOps |
Configure el bucket Amazon S3 de Terraform Artifacts. | Para configurar el bucket Amazon S3 de Terraform Artifacts, utilice el siguiente script:
| AWS DevOps |
Configure el backend y la configuración de los proveedores de Terraform. | Para configurar el backend y los proveedores de Terraform, utilice el siguiente script:
| AWS DevOps |
Genere un plan de despliegue. | Para generar un plan de despliegue, ejecute los siguientes comandos:
| AWS DevOps |
Implemente las configuraciones. | Para implementar las configuraciones, ejecute el siguiente comando:
| AWS DevOps |
Actualice otras configuraciones y almacene los resultados. | Para actualizar las políticas AWS KMS clave y almacenar los resultados de las configuraciones aplicadas en el bucket Amazon S3 de Terraform Artifacts, ejecute los siguientes comandos:
| AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Vaya al directorio | Para ir al
| AWS DevOps |
Configure el backend y la configuración de los proveedores de Terraform. | Para configurar las configuraciones del backend y del proveedor de Terraform, utilice el siguiente script:
| AWS DevOps |
Genere un plan de despliegue. | Para generar un plan de despliegue, ejecute los siguientes comandos. Estos comandos inicializan el entorno de Terraform, combinan las variables de configuración
| AWS DevOps |
Implemente las configuraciones. | Para implementar las configuraciones, ejecute el siguiente comando:
| AWS DevOps |
Actualice otras configuraciones. | Para actualizar las políticas AWS KMS clave y almacenar los resultados de las configuraciones aplicadas en el bucket Amazon S3 de Terraform Artifacts, ejecute los siguientes comandos:
| AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cargue archivos CSV de muestra. | Para cargar archivos CSV de muestra para los conjuntos de datos, siga los siguientes pasos:
| Ingeniero de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Configura el Supply Chain acceso. | Para configurar el Supply Chain acceso desde Consola de administración de AWS, siga los siguientes pasos:
| Propietario de la aplicación |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Active el flujo de trabajo de destrucción de los recursos de los flujos de integración. | Active el flujo de trabajo de destrucción | AWS DevOps |
Active el flujo de trabajo de destrucción de los recursos de conjuntos de datos. | Active el flujo de trabajo de destrucción | AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Vaya al directorio | Para ir al
| AWS DevOps |
Configure el backend y la configuración de los proveedores de Terraform. | Para configurar el backend y los proveedores de Terraform, utilice el siguiente script:
| AWS DevOps |
Genere un plan de destrucción de infraestructura. | Para prepararse para la destrucción controlada de su AWS infraestructura mediante la generación de un plan de desmontaje detallado, ejecute los siguientes comandos. El proceso inicializa Terraform, incorpora configuraciones de Supply Chain conjuntos de datos y crea un plan de destrucción que puede revisar antes de ejecutarlo.
| AWS DevOps |
Ejecute un plan de destrucción de la infraestructura. | Para ejecutar la destrucción planificada de su infraestructura, ejecute el siguiente comando:
| AWS DevOps |
Elimine las salidas de Terraform del bucket de Amazon S3. | Para eliminar el archivo de resultados que se cargó durante la implementación de
| AWS DevOps |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Vaya al directorio | Para ir al
| AWS DevOps |
Configure el backend y la configuración de los proveedores de Terraform. | Para configurar el backend y los proveedores de Terraform, utilice el siguiente script:
| AWS DevOps |
Genere un plan de destrucción de infraestructura. | Para crear un plan para destruir los recursos del Supply Chain conjunto de datos, ejecute los siguientes comandos:
| AWS DevOps |
Depósitos de Amazon S3 vacíos. | Para vaciar todos los depósitos de Amazon S3 (excepto el depósito de registro de acceso al servidor, para el que está configurado
| AWS DevOps |
Ejecute un plan de destrucción de la infraestructura. | Para ejecutar la destrucción planificada de la infraestructura de su Supply Chain conjunto de datos mediante el plan generado, ejecute el siguiente comando:
| AWS DevOps |
Elimine las salidas de Terraform del depósito de artefactos de Terraform de Amazon S3. | Para completar el proceso de limpieza, elimine el archivo de resultados que se cargó durante la implementación de
| AWS DevOps |
Resolución de problemas
| Problema | Solución |
|---|---|
Un Supply Chain conjunto de datos o un flujo de integración no se implementó correctamente debido a errores Supply Chain internos o a la insuficiencia de permisos de IAM para la función de servicio. | En primer lugar, limpie todos los recursos. A continuación, vuelva a implementar los recursos del Supply Chainconjunto de datos y, a continuación, vuelva a implementar los recursos |
El flujo Supply Chain de integración no busca los nuevos archivos de datos cargados para los conjuntos de datos. Supply Chain |
|
Recursos relacionados
AWS documentación
Otros recursos
Descripción de los flujos de trabajo de GitHub Actions
(GitHub documentación)
Información adicional
Esta solución se puede replicar para más conjuntos de datos y se puede consultar para su posterior análisis, a través de paneles prediseñados que se proporcionan con Amazon Quick Sight o mediante una integración Supply Chain personalizada con Amazon Quick Sight. Además, puedes usar Amazon Q para hacer preguntas relacionadas con tu Supply Chain instancia.
Analice los datos con Supply Chain Analytics
Para obtener instrucciones sobre cómo configurar Supply Chain Analytics, consulte Configuración de Supply Chain Analytics en la Supply Chain documentación.
Este patrón demostró la creación de conjuntos de datos Calendar y Outbound_Order_Line. Para crear un análisis que utilice estos conjuntos de datos, siga los siguientes pasos:
Para analizar los conjuntos de datos, utilice el panel de análisis de estacionalidad. Para agregar el panel, siga los pasos que se indican en los paneles prediseñados de la documentación. Supply Chain
Elija el panel para ver su análisis, que se basa en archivos CSV de muestra para los datos del calendario y los datos de las líneas de pedidos salientes.
El panel proporciona información sobre demanda a lo largo de los años en función de los datos ingeridos para los conjuntos de datos. Puede especificar además el ProductID, el CustomeriD, los años y otros parámetros para el análisis.
Usa Amazon Q para hacer preguntas relacionadas con tu Supply Chain instancia
Amazon Q in Supply Chain es un asistente de IA generativa interactivo que le ayuda a gestionar su cadena de suministro de forma más eficiente. Amazon Q puede hacer lo siguiente:
Analice los datos de su lago Supply Chain de datos.
Proporcione información operativa y financiera.
Responda a sus preguntas inmediatas sobre la cadena de suministro.
Para obtener más información sobre el uso de Amazon Q, consulte Activación de Amazon Q Supply Chain y Uso de Amazon Q Supply Chain in en la Supply Chain documentación.
