Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Enriquecimiento semántico automático para Amazon Service OpenSearch
Introducción
Amazon OpenSearch Service utiliza la concordancia palabra a palabra (búsqueda léxica) para encontrar resultados, de forma similar a lo que hacen otros motores de búsqueda tradicionales. Este enfoque funciona bien para consultas específicas, como códigos de productos o números de modelo, pero tiene problemas con las búsquedas abstractas, en las que es crucial entender la intención del usuario. Por ejemplo, si buscas «zapatos para la playa», la búsqueda léxica encuentra las palabras individuales «zapatos», «playa», «para» y «el» en los artículos del catálogo, por lo que podrían omitir productos relevantes como «sandalias resistentes al agua» o «calzado de surf» que no contienen los términos de búsqueda exactos.
El enriquecimiento semántico automático resuelve esta limitación al tener en cuenta tanto las coincidencias de palabras clave como el significado contextual de las búsquedas. Esta función comprende la intención de búsqueda y mejora la relevancia de la búsqueda hasta en un 20%. Activa esta función en los campos de texto de tu índice para mejorar los resultados de búsqueda.
nota
El enriquecimiento semántico automático está disponible para los dominios de OpenSearch servicio que ejecutan la versión 2.19 o posterior. Además, los dominios con la OpenSearch versión 2.19 también deben incluir la última actualización de la versión del software de servicio. Actualmente, la función está disponible para los dominios públicos y no se admiten los dominios de VPC.
Detalles del modelo y punto de referencia de rendimiento
Si bien esta función resuelve las complejidades técnicas entre bastidores sin exponer el modelo subyacente, ofrecemos transparencia mediante una breve descripción del modelo y resultados comparativos para ayudarlo a tomar decisiones informadas sobre la adopción de funciones en sus cargas de trabajo críticas.
El enriquecimiento semántico automático utiliza un modelo disperso prediseñado y gestionado por el servicio que funciona de forma eficaz sin necesidad de ajustes personalizados. El modelo analiza los campos que especificas y los expande en vectores dispersos en función de las asociaciones aprendidas a partir de diversos datos de entrenamiento. Los términos ampliados y sus ponderaciones de significancia se almacenan en un formato de índice nativo de Lucene para una recuperación eficiente. Hemos optimizado este proceso mediante el modo de solo documentos, en el que la codificación solo
Nuestra validación del rendimiento durante el desarrollo de las funciones utilizó el conjunto de datos de recuperación de pasajes de MS MARCO
-
Idioma inglés: mejora la relevancia del 20% con respecto a la búsqueda léxica. También redujo la latencia de búsqueda del P90 en un 7,7% con respecto a la búsqueda léxica (el BM25 es de 26 ms y el enriquecimiento semántico automático es de 24 ms).
-
Multi-lingual - La relevancia mejoró un 105% con respecto a la búsqueda léxica, mientras que la latencia de búsqueda del P90 aumentó un 38,4% con respecto a la búsqueda léxica (BM25 es de 26 ms y el enriquecimiento semántico automático es de 36 ms).
Dada la naturaleza única de cada carga de trabajo, le recomendamos que evalúe esta función en su entorno de desarrollo utilizando sus propios criterios de evaluación comparativa antes de tomar decisiones de implementación.
Idiomas compatibles
La función es compatible con el inglés. Además, el modelo también admite árabe, bengalí, chino, finés, francés, hindi, indonesio, japonés, coreano, persa, ruso, español, swahili y telugu.
Configure un índice de enriquecimiento semántico automático para los dominios
Configurar un índice con el enriquecimiento semántico automático activado para sus campos de texto es fácil y puede gestionarlo mediante la consola, las API y las CloudFormation plantillas durante la creación de un nuevo índice. Para habilitarlo en un índice existente, debe volver a crear el índice con el enriquecimiento semántico automático activado para los campos de texto.
Experiencia de consola: la AWS consola le permite crear fácilmente un índice con campos de enriquecimiento semántico automático. Una vez que selecciones un dominio, encontrarás el botón de creación de índice en la parte superior de la consola. Al hacer clic en el botón de creación de índice, encontrará opciones para definir campos de enriquecimiento semántico automático. En un índice, puede tener combinaciones de enriquecimiento semántico automático para campos en inglés y multilingüe, así como para campos léxicos.
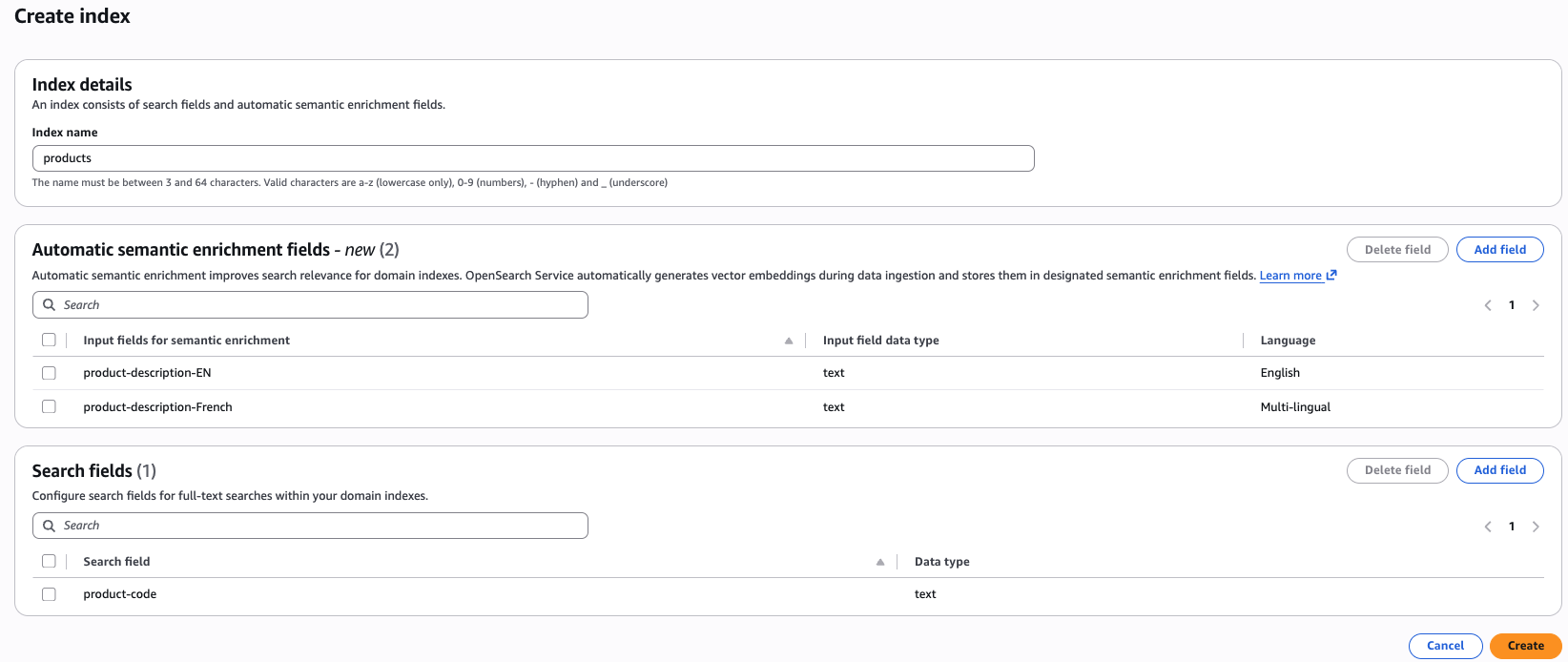
Experiencia con la API: para crear un índice de enriquecimiento semántico automático mediante la interfaz de línea de AWS comandos (AWS CLI), utilice el comando create-index:
aws opensearch create-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body] \
En el siguiente ejemplo de esquema de índice, el campo title_semantic tiene un tipo de campo establecido en texto y el parámetro semantic_enrichment establecido en el estado ENABLED. Si se establece el parámetro semantic_enrichment, se habilita el enriquecimiento semántico automático en el campo title_semantic. Puede usar el campo language_options para especificar el inglés o. MULTI-LINGUAL
aws opensearch create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Para describir el índice creado, utilice el siguiente comando:
aws opensearch get-index \ --domain-name [domain_name] \ --index-name [index_name] \
Actualice un índice existente
Puede actualizar un índice existente para añadir nuevos campos de enriquecimiento semántico, activar o desactivar el enriquecimiento semántico en los campos existentes o añadir campos de texto no semánticos. Use el update-index comando y proporcione solo los campos que desee cambiar en el. index-schema Los campos no incluidos en la solicitud se dejan sin cambios.
nota
settingsNo se puede actualizar el índice. Si incluye un settings bloque en la solicitud, la operación devuelve un error de validación. Para cambiar la configuración del índice, debe eliminar y volver a crear el índice.
Para actualizar un índice mediante el AWS CLI, utilice el update-index comando:
aws opensearch update-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body]
Añada un nuevo campo de enriquecimiento semántico
Puede añadir un text campo nuevo con el enriquecimiento semántico activado a un índice existente. El servicio configura automáticamente el modelo de aprendizaje automático, la canalización de ingesta y la canalización de búsqueda necesarios. Los nuevos documentos indexados después de la actualización se enriquecen automáticamente.
importante
Los documentos existentes no se rellenan. Para rellenar el campo de enriquecimiento semántico de los documentos existentes, debe volver a ingerirlos después de la actualización. Hasta que se vuelvan a incorporar, los documentos existentes no se beneficiarán de la búsqueda semántica en el nuevo campo.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Deshabilita el enriquecimiento semántico en un campo
Para deshabilitar el enriquecimiento semántico en un campo que actualmente lo tiene activado, configúrelo en. status DISABLED El campo se elimina de las canalizaciones de ingesta y búsqueda. El campo de texto subyacente y su campo de incrustación permanecen en el índice, pero ya no están enriquecidos.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Limitaciones de actualización
Las siguientes operaciones no son compatibles con el índice, por update-index lo que es necesario eliminarlo y volver a crearlo:
-
Cambiar
language_optionsen un campo que actualmente tiene activado el enriquecimiento semántico. Desactive primero el campo y, a continuación, vuelva a habilitarlo con la nueva opción de idioma. -
Actualización de campos anidados. El enriquecimiento semántico solo se admite en los campos de nivel superior.
text -
Actualización del índice.
settings
nota
Si el índice tiene una canalización de ingesta o búsqueda personalizada que no se creó mediante el enriquecimiento semántico automático, la operación de actualización se bloquea. Elimine la canalización personalizada antes de añadir campos de enriquecimiento semántico.
Ingestión y búsqueda de datos
Una vez que haya creado un índice con el enriquecimiento semántico automático activado, la función funcionará automáticamente durante el proceso de ingesta de datos, sin necesidad de realizar ninguna configuración adicional.
Ingesta de datos: al añadir documentos al índice, el sistema automáticamente:
-
Analiza los campos de texto que designó para el enriquecimiento semántico
-
Genera codificaciones semánticas mediante OpenSearch un modelo disperso gestionado por el servicio
-
Almacena estas representaciones enriquecidas junto con los datos originales
Este proceso utiliza los conectores OpenSearch de aprendizaje automático integrados y las canalizaciones de ingesta, que se crean y administran automáticamente entre bastidores.
Búsqueda: los datos de enriquecimiento semántico ya están indexados, por lo que las consultas se ejecutan de manera eficiente sin tener que volver a invocar el modelo de aprendizaje automático. Esto significa que obtiene una mayor relevancia de búsqueda sin sobrecargar la latencia de búsqueda adicional.
Configuración de permisos para el enriquecimiento semántico automático
Antes de crear un índice con enriquecimiento semántico automático, debe configurar los permisos necesarios. En esta sección se explican los permisos necesarios para las distintas operaciones de indexación y cómo configurarlos tanto para escenarios AWS Identity and Access Management (IAM) como para escenarios de control de acceso detallados.
Permisos de IAM
Los siguientes permisos de IAM son necesarios para las operaciones de enriquecimiento semántico automático. Estos permisos varían en función de la operación de indexación específica que desee realizar.
CreateIndex Permisos de API
Para crear un índice con enriquecimiento semántico automático, necesita los siguientes permisos de IAM:
-
es:CreateIndex— Cree un índice con capacidades de enriquecimiento semántico. -
es:ESHttpHead— Realice solicitudes HEAD para comprobar la existencia del índice. -
es:ESHttpPut— Realizar solicitudes PUT para la creación de índices. -
es:ESHttpPost— Realizar solicitudes POST para operaciones de indexación.
UpdateIndex Permisos de API
Para actualizar un índice existente con un enriquecimiento semántico automático, necesita los siguientes permisos de IAM:
-
es:UpdateIndex— Actualizar la configuración y los mapeos de los índices. -
es:ESHttpPut— Realizar solicitudes PUT para actualizaciones de índices. -
es:ESHttpGet— Realizar solicitudes GET para recuperar la información del índice. -
es:ESHttpPost— Realizar solicitudes POST para operaciones de indexación.
GetIndex Permisos de API
Para recuperar información sobre un índice con enriquecimiento semántico automático, necesita los siguientes permisos de IAM:
-
es:GetIndex— Recuperar la información y la configuración del índice. -
es:ESHttpGet— Realizar solicitudes GET para recuperar los datos del índice.
DeleteIndex Permisos de API
Para eliminar un índice con enriquecimiento semántico automático, necesita los siguientes permisos de IAM:
-
es:DeleteIndex— Eliminar un índice y sus componentes de enriquecimiento semántico. -
es:ESHttpDelete— Realizar solicitudes de ELIMINACIÓN para eliminar el índice.
Ejemplo de política de IAM
El siguiente ejemplo de política de acceso basada en la identidad proporciona los permisos necesarios para que un usuario gestione los índices con un enriquecimiento semántico automático:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSemanticEnrichmentIndexOperations", "Effect": "Allow", "Action": [ "es:CreateIndex", "es:UpdateIndex", "es:GetIndex", "es:DeleteIndex", "es:ESHttpHead", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost", "es:ESHttpDelete" ], "Resource": "arn:aws:es:aws-region:111122223333:domain/domain-name" } ] }
Sustituya aws-region y por 111122223333 sus valores específicos. domain-name Puede restringir aún más el acceso especificando patrones de índice específicos en el ARN del recurso.
Fine-grained permisos de control de acceso
Si tu dominio de Amazon OpenSearch Service tiene activado un control de acceso detallado, necesitarás permisos adicionales además de los permisos de IAM. Se requieren los siguientes permisos para cada operación de indexación.
CreateIndex Permisos de API
Cuando se habilita el control de acceso detallado, se requieren los siguientes permisos adicionales para crear un índice con enriquecimiento semántico automático:
-
indices:admin/create— Crear operaciones de indexación. -
indices:admin/mapping/put— Crear y actualizar mapeos de índices. -
cluster:admin/opensearch/ml/create_connector— Cree conectores de aprendizaje automático para el procesamiento semántico. -
cluster:admin/opensearch/ml/register_model— Registre modelos de aprendizaje automático para el enriquecimiento semántico. -
cluster:admin/ingest/pipeline/put— Cree canales de ingesta para el procesamiento de datos. -
cluster:admin/search/pipeline/put— Crear canales de búsqueda para el procesamiento de consultas.
UpdateIndex Permisos de API
Cuando se habilita el control de acceso detallado, se requieren los siguientes permisos adicionales para actualizar un índice con el enriquecimiento semántico automático:
-
indices:admin/get— Recuperar información del índice. -
indices:admin/settings/update— Actualizar la configuración del índice. -
indices:admin/mapping/put— Actualizar las asignaciones de índices. -
cluster:admin/opensearch/ml/create_connector— Crear conectores de aprendizaje automático. -
cluster:admin/opensearch/ml/register_model— Registrar modelos de aprendizaje automático. -
cluster:admin/ingest/pipeline/put— Crea canalizaciones de ingesta. -
cluster:admin/search/pipeline/put— Crear canalizaciones de búsqueda. -
cluster:admin/ingest/pipeline/get— Recuperar la información de las canalizaciones de ingesta. -
cluster:admin/search/pipeline/get— Recuperar la información de la canalización de búsqueda.
GetIndex Permisos de API
Cuando se habilita el control de acceso detallado, se requieren los siguientes permisos adicionales para recuperar información sobre un índice con un enriquecimiento semántico automático:
-
indices:admin/get— Recuperar información del índice. -
cluster:admin/ingest/pipeline/get— Recuperar la información de la canalización de ingesta. -
cluster:admin/search/pipeline/get— Recuperar la información de la canalización de búsqueda.
DeleteIndex Permisos de API
Cuando se habilita el control de acceso detallado, se requiere el siguiente permiso adicional para eliminar un índice con el enriquecimiento semántico automático:
-
indices:admin/delete— Eliminar las operaciones de indexación.
Reescrituras de consultas
El enriquecimiento semántico automático convierte automáticamente las consultas «coincidentes» existentes en consultas de búsqueda semántica sin necesidad de modificar las consultas. Si una consulta de coincidencia forma parte de una consulta compuesta, el sistema recorre la estructura de la consulta, busca las consultas coincidentes y las reemplaza por consultas de dispersión neuronal. Actualmente, la función solo permite reemplazar las consultas «coincidentes», tanto si se trata de una consulta independiente como si forma parte de una consulta compuesta. No se admite la opción «multi_match». Además, la función admite todas las consultas compuestas para reemplazar sus consultas de coincidencia anidadas. Las consultas compuestas incluyen: bool, boost, constant_score, dis_max, function_score e hybrid.
Limitaciones del enriquecimiento semántico automático
La búsqueda semántica automática es más eficaz cuando se aplica a campos de tamaño pequeño o mediano que contienen contenido en lenguaje natural, como títulos de películas, descripciones de productos, reseñas y resúmenes. Si bien la búsqueda semántica aumenta la relevancia en la mayoría de los casos de uso, puede que no sea óptima en algunos casos. Ten en cuenta las siguientes limitaciones a la hora de decidir si vas a implementar el enriquecimiento semántico automático para tu caso de uso específico.
-
Documentos muy largos: el modelo disperso actual procesa solo los primeros 8.192 símbolos de cada documento en inglés. En el caso de los documentos multilingües, se trata de 512 fichas. En el caso de artículos extensos, considere la posibilidad de implementar la fragmentación de documentos para garantizar un procesamiento completo del contenido.
-
Cargas de trabajo de análisis de registros: el enriquecimiento semántico aumenta significativamente el tamaño del índice, lo que puede resultar innecesario en el análisis de registros, donde la coincidencia exacta suele ser suficiente. El contexto semántico adicional rara vez mejora la eficacia de la búsqueda de registros lo suficiente como para justificar el aumento de los requisitos de almacenamiento.
-
El enriquecimiento semántico automático no es compatible con la función Fuente derivada.
-
Limitación: las solicitudes de inferencia de indexación están actualmente limitadas a 200 TPS para los dominios de servicio. OpenSearch Este es un límite flexible; ponte en contacto con AWS Support para obtener límites más altos.
Precios
Amazon OpenSearch Service factura el enriquecimiento semántico automático en función de las unidades de OpenSearch cómputo (OCU) consumidas durante la generación de vectores dispersos en el momento de la indexación. Solo se le cobrará por el uso real durante la indexación de los campos de texto en los que haya activado el enriquecimiento semántico automático. Una OCU de búsqueda semántica puede procesar 11,1 millones de fichas para contenido en inglés. Para procesar 2,4 mil millones de fichas, necesitarías unas 216 búsquedas semánticas OCU-hours (2 400 millones/11,10 millones). Con un precio de 0,24$ por búsqueda semántica OCU-hour, el coste de procesar 10 GB de datos para la búsqueda semántica automática sería de 51$ (216 x 0$). OCU-hours 24/OCU-hora). La búsqueda semántica (OCU) no conlleva cargos adicionales durante las operaciones de búsqueda ni por el almacenamiento de datos.
Puedes monitorizar este consumo mediante la CloudWatch métrica de AmazonSemanticSearchOCU. Para obtener información específica sobre los límites de los tokens del modelo, el volumen de procesamiento por OCU y un ejemplo de un ejemplo de cálculo, consulta los precios de los OpenSearch servicios
