Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
# Paso 4: preparar la salida de Amazon Comprehend para la visualización de datos
Para preparar los resultados de los trabajos de análisis de opiniones y entidades y crear visualizaciones de datos, utilice AWS Glue y Amazon Athena. En este paso, extraiga los archivos de resultados de Amazon Comprehend. A continuación, cree un *rastreador* AWS Glue que explora sus datos y los cataloga automáticamente en las tablas de AWS Glue Data Catalog. Después de eso, puede acceder a estas tablas y transformarlas mediante Amazon Athena un servicio de consultas interactivo y sin servidor. Cuando haya terminado este paso, los resultados de Amazon Comprehend estarán limpios y listos para su visualización.
Para un trabajo de detección de entidades de PII, el archivo de salida es texto simple, no comprimido. El nombre del archivo de salida es el mismo que el del archivo de entrada, con un `.out` anexo al final. No necesita el paso de extraer el archivo de salida. Omitir para [cargar los datos en un AWS Glue Data Catalog](#tutorial-reviews-tables-crawler).
**Topics**
+ [Requisitos previos](#tutorial-reviews-tables-prereqs)
+ [Cómo descargar el archivo de salida](#tutorial-reviews-tables-download)
+ [Extraer los archivos de salida](#tutorial-reviews-tables-extract)
+ [Cómo cargar los archivos extraídos](#tutorial-reviews-tables-upload)
+ [Cargue los datos en un AWS Glue Data Catalog](#tutorial-reviews-tables-crawler)
+ [Cómo preparar los datos para su análisis](#tutorial-reviews-tables-prep)
## Requisitos previos
Antes de empezar, complete [Paso 3: ejecutar trabajos de análisis en documentos en Amazon S3](tutorial-reviews-analysis.md).
## Cómo descargar el archivo de salida
Amazon Comprehend utiliza la compresión Gzip para comprimir los archivos de salida y guardarlos como un archivo tar. La forma más sencilla de extraer los archivos de salida es descargar los `output.tar.gz` localmente.
En este paso, descargará los archivos de salida de opiniones y entidades.
### Cómo descargar los archivos de salida (consola)
Para buscar los archivos de salida de cada trabajo, vuelva al trabajo de análisis en la consola de Amazon Comprehend. El trabajo de análisis proporciona la ubicación S3 de la salida, donde puede descargar el archivo de salida.
**Cómo descargar los archivos de salida (consola)**
1. En la [consola Amazon Comprehend](https://console.aws.amazon.com/comprehend/), en el panel de navegación, vuelva a **Trabajos de análisis**.
1. Seleccione su trabajo de análisis de opiniones `reviews-sentiment-analysis`.
1. En **Salida**, seleccione el enlace que aparece junto a la **ubicación de los datos de salida**. Esto lo redirige al archivo `output.tar.gz` de su bucket de S3.
1. En la página **Información general**, seleccione **Descargar**.
1. En su ordenador, cambie el nombre del archivo a `sentiment-output.tar.gz`. Como todos los archivos de salida tienen el mismo nombre, esto le ayuda a realizar un seguimiento de los archivos de opiniones y entidades.
1. Repita los pasos del 1 al 4 para buscar y descargar el resultado de su trabajo de `reviews-entities-analysis`. En su ordenador, cambie el nombre del archivo a `entities-output.tar.gz`.
### Cómo descargar los archivos de salida (AWS CLI)
Para buscar los archivos de salida de cada trabajo, utilice la `JobId` del trabajo de análisis para buscar la ubicación de S3 de salida. A continuación, utilice el comando `cp` para descargar el archivo de salida a su ordenador.
**Cómo descargar de los archivos de salida (AWS CLI)**
1. Para ver una lista de detalles acerca de su trabajo de análisis de opiniones, ejecute el siguiente comando. Sustituya `{{sentiment-job-id}}` por la `JobId` de opinión que guardó.
```
aws comprehend describe-sentiment-detection-job --job-id {{sentiment-job-id}}
```
Si perdió el registro de su `JobId`, puede ejecutar el siguiente comando para enumerar todos sus trabajos de opinión y filtrarlos por su nombre.
```
aws comprehend list-sentiment-detection-jobs
--filter JobName="reviews-sentiment-analysis"
```
1. En el objeto de la `OutputDataConfig`, busque el valor `S3Uri`. El valor `S3Uri` debería ser similar al siguiente formato: `{{s3://amzn-s3-demo-bucket/.../output/output.tar.gz}}`. Copie este valor en un editor de texto.
1. Para descargar el archivo de salida de opiniones en su directorio local, ejecute el siguiente comando. Sustituya la ruta del bucket de S3 por `S3Uri` que copió en el paso anterior. Sustituya `{{path/}}` por la ruta de la carpeta a su directorio local. El nombre `sentiment-output.tar.gz` sustituye al nombre original del archivo para ayudarle a realizar un seguimiento de los archivos de opiniones y entidades.
```
aws s3 cp {{s3://amzn-s3-demo-bucket/.../output/output.tar.gz}}
{{path/}}sentiment-output.tar.gz
```
1. Para ver una lista de detalles acerca de su trabajo de análisis de entidades, ejecute el siguiente comando.
```
aws comprehend describe-entities-detection-job
--job-id {{entities-job-id}}
```
Si no conoce su `JobId`, puede ejecutar el siguiente comando para enumerar todos sus trabajos de opinión y filtrarlos por su nombre.
```
aws comprehend list-entities-detection-jobs
--filter JobName="reviews-entities-analysis"
```
1. Del objeto `OutputDataConfig` de la descripción del trabajo de entidades, copia el valor `S3Uri`.
1. Para descargar el archivo de salida de entidades en su directorio local, ejecute el siguiente comando. Sustituya la ruta del bucket de S3 por `S3Uri` que copió en el paso anterior. Sustituya `{{path/}}` por la ruta de la carpeta a su directorio local. El nombre `entities-output.tar.gz` reemplaza al nombre del archivo original.
```
aws s3 cp {{s3://amzn-s3-demo-bucket/.../output/output.tar.gz}}
{{path/}}entities-output.tar.gz
```
## Extraer los archivos de salida
Antes de poder acceder a los resultados de Amazon Comprehend, extraiga los archivos de opiniones y entidades. Puede usar su sistema de archivos local o un terminal para extraer los archivos.
### Cómo extraer los archivos de salida (sistema de archivos GUI)
Si usa macOS, haga doble clic en el archivo de su sistema de archivos GUI para extraer el archivo de salida del archivo.
Si utiliza Windows, puede utilizar una herramienta de terceros, como 7-Zip, para extraer los archivos de salida en el sistema de archivos de la GUI. En Windows, debe realizar dos pasos para acceder al archivo de salida del archivo. Primero descomprima el archivo y, a continuación,extráigalo.
Cambie el nombre del archivo de opiniones a `sentiment-output` y del archivo de entidades a `entities-output` para distinguir entre los archivos de salida.
### Cómo extraer los archivos de salida (terminal)
Si utiliza Linux o macOS, puede utilizar un terminal estándar. Si usa Windows, debe tener acceso a un Unix-style entorno, como Cygwin, para ejecutar los comandos tar.
Para extraer el archivo de salida de opiniones del archivo de opiniones, ejecute el siguiente comando en su terminal local.
```
tar -xvf sentiment-output.tar.gz --transform 's,^,sentiment-,'
```
Tenga en cuenta que el parámetro `--transform` añade el prefijo `sentiment-` al archivo de salida dentro del archivo y cambia el nombre del archivo a `sentiment-output`. Esto le permite distinguir entre los archivos de salida de opiniones y entidades y evitar que se sobrescriban.
Para extraer el archivo de salida de entidades del archivo de entidades, ejecute el siguiente comando en su terminal local.
```
tar -xvf entities-output.tar.gz --transform 's,^,entities-,'
```
El parámetro `--transform` añade el prefijo `entities-` al nombre del archivo de salida.
**sugerencia**
Para ahorrar costos de almacenamiento en Amazon S3, puede volver a comprimir los archivos con Gzip antes de cargarlos. Es importante descomprimir y descomprimir los archivos originales porque no se AWS Glue pueden leer automáticamente los datos de un archivo tar. Sin embargo, AWS Glue puede leer archivos en formato Gzip.
## Cómo cargar los archivos extraídos
Después de extraer los archivos, súbalos a su bucket. Debe almacenar los archivos de salida de opiniones y entidades en carpetas separadas AWS Glue para poder leer los datos correctamente. En su bucket, cree una carpeta para los resultados de las opiniones extraídas y una segunda carpeta para los resultados de las entidades extraídas. Puede crear carpetas con la consola de Amazon S3 o con AWS CLI.
### Cómo cargar los archivos extraídos en Amazon S3 (consola)
En su bucket de S3, cree una carpeta para el archivo de los resultados de las opiniones extraído y una carpeta para el archivo de los resultados de las entidades. A continuación, cargue los archivos de los resultados extraídos en sus carpetas respectivas.
**Cómo cargar los archivos extraídos en Amazon S3 (consola)**
1. Abra la consola de Amazon S3 en [https://console.aws.amazon.com/s3/](https://console.aws.amazon.com/s3/).
1. En **Buckets**, elija su bucket y, a continuación, seleccione **Crear carpeta**.
1. Para el nombre de la nueva carpeta, ingrese `sentiment-results` y seleccione **Guardar**. Esta carpeta contendrá el archivo de salida de opiniones extraído.
1. En la pestaña **Descripción general** del bucket, de la lista del contenido del bucket, seleccione la nueva carpeta `sentiment-results`. Seleccione **Cargar**.
1. Seleccione **Añadir archivos**, seleccione el archivo `sentiment-output` de su ordenador local y, a continuación, seleccione **Siguiente**.
1. Deje las opciones **Administrar usuarios**, **Acceder a otros Cuenta de AWS** usuarios y **Administrar permisos públicos** como predeterminadas. Elija **Siguiente**.
1. Para la **Clase de almacenamiento**, seleccione **Estándar**. Deje las opciones de **Cifrado**, **Metadata** y **Etiqueta** como valores predeterminados. Seleccione **Siguiente**.
1. Revise las opciones de carga y, a continuación, seleccione **Cargar**.
1. Repita los pasos del 1 al 8 para crear una carpeta llamada `entities-results` y carga el `entities-output` archivo en ella.
### Cómo cargar los archivos extraídos en Amazon S3 (AWS CLI)
Puede crear una carpeta en su bucket de S3 mientras carga un archivo con el comando `cp`.
**Cómo cargar los archivos extraídos en Amazon S3 (AWS CLI)**
1. Cree una carpeta de opiniones y carga su archivo de opiniones en esta y ejecute el siguiente comando. Sustituya `{{path/}}` por la ruta local al archivo de salida de opiniones extraído.
```
aws s3 cp {{path/}}sentiment-output s3://amzn-s3-demo-bucket/sentiment-results/
```
1. Cree una carpeta de salida de entidades y cargue su archivo de entidades en esta y ejecute el siguiente comando. Sustituya `{{path/}}` por la ruta local al archivo de salida de entidades extraído.
```
aws s3 cp {{path/}}entities-output s3://amzn-s3-demo-bucket/entities-results/
```
## Cargue los datos en un AWS Glue Data Catalog
Para obtener los resultados en una base de datos, puede utilizar un AWS Glue *rastreador*. Un AWS Glue *rastreador* escanea los archivos y descubre el esquema de los datos. A continuación, organice los datos en tablas en una AWS Glue Data Catalog (base de datos sin servidor). Puede crear un rastreador con la AWS Glue consola o el. AWS CLI
### Cargue los datos en una AWS Glue Data Catalog (consola)
Cree un AWS Glue rastreador que escanee sus `entities-results` carpetas `sentiment-results` y carpetas por separado. Un nuevo rol de IAM para AWS Glue le concede permiso al rastreador para acceder a su bucket de S3. Este rol de IAM se crea al configurar el rastreador.
**Para cargar los datos en una AWS Glue Data Catalog (consola)**
1. Asegúrese de estar en una región que lo admita AWS Glue. Si se encuentra en otra región, en la barra de navegación, seleccione una región compatible con el **Selector de regiones**. Para obtener una lista de las regiones compatibles AWS Glue, consulta la [tabla de regiones](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/) de la *Guía de infraestructura global*.
1. Abra la AWS Glue consola en [https://console.aws.amazon.com/glue/](https://console.aws.amazon.com/glue/).
1. En el panel de navegación, seleccione **Rastreadores** y después seleccione **Añadir rastreador**.
1. En **Nombre de rastreador**, escribe `comprehend-analysis-crawler` y, a continuación, seleccione **Siguiente**.
1. Para **Tipo de origen del rastreador**, seleccione **Almacenes de datos** y a continuación, elija **Siguiente**.
1. En la página **Agregar un almacén de datos**, haga lo siguiente:
1. En **Elegir un almacén de datos**, elija **S3**.
1. Deje **Conexión** en blanco.
1. Para la opción **Rastrear los datos en**, elija **Ruta especificada en mi cuenta**.
1. En **Incluir ruta**, introduzca la ruta S3 completa de la carpeta de salida de opiniones: `s3://amzn-s3-demo-bucket/sentiment-results`.
1. Seleccione **Siguiente**.
1. En **Agregar otro almacén de datos**, seleccione **Sí** y, a continuación, **Siguiente**. Repita el paso 6, pero introduzca la ruta S3 completa de la carpeta de salida de las entidades: `s3://amzn-s3-demo-bucket/entities-results`.
1. En **Agregar otro almacén de datos** elija **No** y, a continuación, **Siguiente**.
1. En **Elija un Rol de IAM**, realice una de las operaciones siguientes:
1. Elija **Crear un rol de IAM**.
1. Para el **rol de IAM**, introduzca `glue-access-role` y, a continuación, seleccione **Siguiente**.
1. En **Crear una programación para este rastreador**, elija **Ejecutar bajo demanda** y seleccione **Siguiente**.
1. Para **Configurar la salida del rastreador**, haga lo siguiente:
1. En **Base de datos** elija **Agregar base de dato**.
1. En **Database name (Nombre de base de datos)**, escriba `comprehend-results`. Esta base de datos almacenará las tablas de resultados de Amazon Comprehend.
1. Deje las demás opciones en su configuración predeterminada y seleccione **Siguiente**.
1. Revise la información del rastreador y seleccione **Finalizar**.
1. En la consola Glue, en **Rastreadores**, seleccione `comprehend-analysis-crawler` y elija **Ejecutar rastreador**. El rastreador demorará unos minutos en finalizar.
### Cargue los datos en un AWS Glue Data Catalog (AWS CLI)
Cree un rol de IAM AWS Glue que le dé permiso para acceder a su bucket de S3. A continuación, cree una base de datos en AWS Glue Data Catalog. Por último, cree y ejecute un rastreador que cargue sus datos en tablas de la base de datos.
**Para cargar los datos en un AWS Glue Data Catalog ()AWS CLI**
1. Para crear un rol de IAM AWS Glue, haga lo siguiente:
1. Guarde la siguiente política de confianza como un documento JSON llamado `glue-trust-policy.json` en su ordenador.
------
#### [ JSON ]
****
```
{
"Version":"2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "glue.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
```
------
1. Para crear el rol de IAM, ejecute el siguiente comando. Sustituya `{{path/}}` con la ruta de su ordenador local para el documento JSON.
```
aws iam create-role --role-name glue-access-role
--assume-role-policy-document file://{{path/}}glue-trust-policy.json
```
1. Cuando aparezca el AWS CLI número de recurso de Amazon (ARN) para el nuevo rol, cópielo y guárdelo en un editor de texto.
1. Guarde la siguiente política de IAM como un documento JSON llamado `glue-access-policy.json` en su ordenador. La política concede AWS Glue permiso para rastrear las carpetas de resultados.
------
#### [ JSON ]
****
```
{
"Version":"2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::amzn-s3-demo-bucket/sentiment-results*",
"arn:aws:s3:::amzn-s3-demo-bucket/entities-results*"
]
}
]
}
```
------
1. Para crear una política de IAM, ejecute el siguiente comando. Sustituya `{{path/}}` con la ruta de su ordenador local para el documento JSON.
```
aws iam create-policy --policy-name glue-access-policy
--policy-document file://{{path/}}glue-access-policy.json
```
1. Cuando muestre el AWS CLI ARN de la política de acceso, cópielo y guárdelo en un editor de texto.
1. Adjunte la nueva política al rol de IAM y ejecute el siguiente comando. Sustituya `{{policy-arn}}` por el ARN de la política de IAM que copió en el paso anterior.
```
aws iam attach-role-policy --policy-arn {{policy-arn}}
--role-name glue-access-role
```
1. Adjunte la política AWS gestionada `AWSGlueServiceRole` a su función de IAM ejecutando el siguiente comando.
```
aws iam attach-role-policy --policy-arn
arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole
--role-name glue-access-role
```
1. Cree una AWS Glue base de datos ejecutando el siguiente comando.
```
aws glue create-database
--database-input Name="comprehend-results"
```
1. Cree un AWS Glue rastreador nuevo ejecutando el siguiente comando. `{{glue-iam-role-arn}}`Sustitúyalo por el ARN de su función de AWS Glue IAM.
```
aws glue create-crawler
--name comprehend-analysis-crawler
--role {{glue-iam-role-arn}}
--targets S3Targets=[
{Path="s3://amzn-s3-demo-bucket/sentiment-results"},
{Path="s3://amzn-s3-demo-bucket/entities-results"}]
--database-name comprehend-results
```
1. Inicie el rastreador, ejecutando el siguiente comando.
```
aws glue start-crawler --name comprehend-analysis-crawler
```
El rastreador demorará unos minutos en finalizar.
## Cómo preparar los datos para su análisis
Ahora tiene una base de datos rellenada con los resultados de Amazon Comprehend. Sin embargo, los resultados están anidados. Para eliminarlos, debe ejecutar algunas sentencias SQL. Amazon Athena Amazon Athena es un servicio de consultas interactivas que facilita el análisis de datos en Amazon S3 mediante SQL estándar. Athena no requiere un servidor, por lo que no hay una infraestructura para administrar y tiene un modelo de precios de pago por consulte. En este paso, creará nuevas tablas de datos depurados que podrá utilizar para el análisis y la visualización. Utilice la consola de Athena para preparar los datos.
**Cómo preparar los datos**
1. Abra la consola Athena en [https://console.aws.amazon.com/athena/](https://console.aws.amazon.com/athena/home).
1. En el editor de consultas, elija **Settings** (Configuración) y, a continuación, **Manage** (Administrar).
1. En **Ubicación de los resultados de la consulte**, introduzca `s3://amzn-s3-demo-bucket/query-results/`. Esto crea una nueva carpeta llamada `query-results` en su bucket que almacena el resultado de las Amazon Athena consultas que ejecuta. Seleccione **Save**.
1. En el editor de consultas, seleccione **Editor**.
1. En **Base de datos**, elige la AWS Glue base de datos `comprehend-results` que has creado.
1. En la sección **Tablas** debe tener dos tablas denominadas `sentiment_results` y `entities_results`. Obtenga una vista previa de las tablas para asegurarte de que el rastreador cargó los datos. En las opciones de cada tabla (los tres puntos situados junto al nombre de la tabla), seleccione **Vista previa de la tabla**. Se ejecuta automáticamente una consulte breve. Compruebe el panel **Resultados** para asegurarte de que las tablas contienen datos.
**sugerencia**
Si las tablas no tienen ningún dato, intente comprobar las carpetas del bucket de S3. Asegúrese de que haya una carpeta para los resultados de las entidades y otra para los resultados de las opiniones. A continuación, intente ejecutar un AWS Glue rastreador nuevo.
1. Para aplanar la tabla `sentiment_results`, introduzca la siguiente consulte en **Editor de consultas** y seleccione **Ejecutar**.
```
CREATE TABLE sentiment_results_final AS
SELECT file, line, sentiment,
sentimentscore.mixed AS mixed,
sentimentscore.negative AS negative,
sentimentscore.neutral AS neutral,
sentimentscore.positive AS positive
FROM sentiment_results
```
1. Para comenzar a aplanar la tabla de entidades, introduzca la siguiente consulte en **Editor de consultas** y seleccione **Ejecutar**.
```
CREATE TABLE entities_results_1 AS
SELECT file, line, nested FROM entities_results
CROSS JOIN UNNEST(entities) as t(nested)
```
1. Para finalizar el anidamiento de las tablas de entidades, introduzca la siguiente consulte en **Editor de consultas** y seleccione **Ejecutar**.
```
CREATE TABLE entities_results_final AS
SELECT file, line,
nested.beginoffset AS beginoffset,
nested.endoffset AS endoffset,
nested.score AS score,
nested.text AS entity,
nested.type AS category
FROM entities_results_1
```
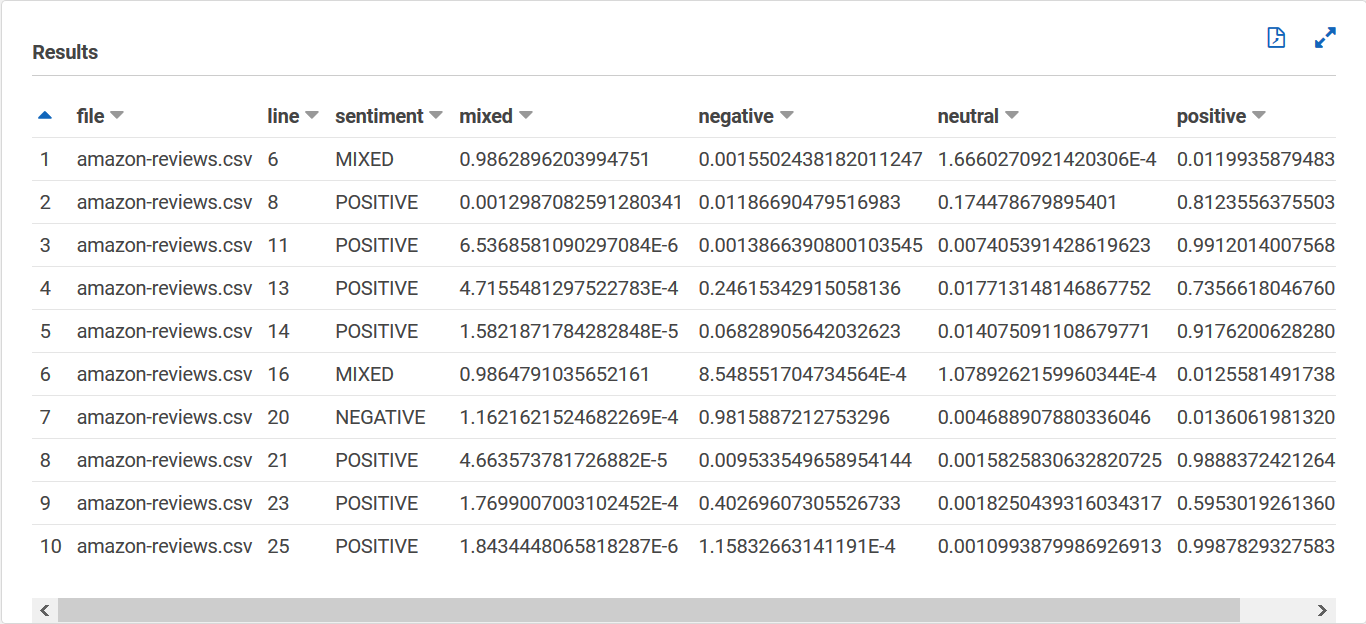
Su tabla `sentiment_results_final` debe tener el siguiente aspecto, con columnas denominadas **archivo**, **línea**, **opinión**, **mixta**, **negativa**, **neutral** y **positiva**. La tabla debe tener un valor por celda. La columna de **opinión** describe la opinión general más probable de una opinión concreta. Las columnas **mixtas**, **negativas**, **neutrales** y **positivas** dan puntuaciones para cada tipo de sentimiento.
Su tabla de `entities_results_final` debería tener el siguiente aspecto, con columnas denominadas **archivo**, **línea**, **comenzardesplazamiento**, **terminardesplazamiento**, **puntuación**, **entidad** y **categoría**. La tabla debe tener un valor por celda. La columna de **puntuación** indica la confianza de Amazon Comprehend en la **entidad** que detectó. La **categoría** indica qué tipo de entidad detectó Comprehend.

Ahora que tiene los resultados de Amazon Comprehend cargados en tablas, puede visualizar y extraer información significativa de los datos.