Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verbesserungen der kollektiven Kommunikationsinitialisierung
NCCL und Gloo sind grundlegende Kommunikationsbibliotheken, die kollektive Operationen (wie All-Reduce und Broadcast) in verteilten Trainingsprozessen ermöglichen. Herkömmliche NCCL- und Gloo-Initialisierungen können jedoch zu Engpässen bei der Fehlerbehebung führen.
Beim standardmäßigen Wiederherstellungsprozess müssen alle Prozesse eine Verbindung zu einem zentralen TCPStore herstellen und über einen Root-Prozess koordiniert werden, was zu einem teuren Overhead führt, der bei Neustarts besonders problematisch wird. Dieser zentralisierte Aufbau führt zu drei kritischen Problemen: Koordinationsaufwand aufgrund obligatorischer TCPStore-Verbindungen, Verzögerungen bei der Wiederherstellung, da bei jedem Neustart die gesamte Initialisierungssequenz wiederholt werden muss, und eine einzelne Fehlerquelle im Root-Prozess selbst. Dies führt bei jeder Initialisierung oder jedem Neustart der Schulung zu kostspieligen, zentralen Koordinationsschritten.
HyperPod Das Training ohne Checkpoint beseitigt diese Koordinationsengpässe und ermöglicht eine schnellere Behebung von Fehlern, indem die Initialisierung auf „Rootless“ und „TCPStoless“ umgestellt wird.
Konfigurationen ohne Roots
Um Rootless zu aktivieren, kann man einfach die folgenden Umgebungsvariablen verfügbar machen.
export HPCT_USE_ROOTLESS=1 && \ sysctl -w net.ipv4.ip_local_port_range="20000 65535" && \
HPCT_USE_ROOTLESS: 0 oder 1. Wird verwendet, um Rootless ein- und auszuschalten
sysctl -w net.ipv4.ip_local_port_range="20000 65535": Legt den Portbereich des Systems fest
Sehen Sie sich das Beispiel für die Aktivierung von Rootless an.
Rootless
HyperPod Das Checkpointless-Training bietet neuartige Initialisierungsmethoden, Rootless und TCPStoreless, für NCCL- und Gloo-Prozessgruppen.
Die Implementierung dieser Optimierungen beinhaltet die Modifikation von NCCL, Gloo und: PyTorch
Erweiterung der Bibliotheks-APIs von Drittanbietern, um Rootless- und Storeless NCCL- und Gloo-Optimierungen zu ermöglichen und gleichzeitig die Abwärtskompatibilität aufrechtzuerhalten
Aktualisierung von Prozessgruppen-Backends, um optimierte Pfade unter bestimmten Bedingungen zu verwenden und Probleme bei der Wiederherstellung während des Prozesses zu lösen
Umgehung der teuren TCPStore-Erstellung auf PyTorch verteilter Ebene bei gleichzeitiger Beibehaltung symmetrischer Adressmuster durch globale Gruppenzähler
Die folgende Grafik zeigt die Architektur der verteilten Trainingsbibliotheken und die Änderungen, die beim Training ohne Checkpoints vorgenommen wurden.
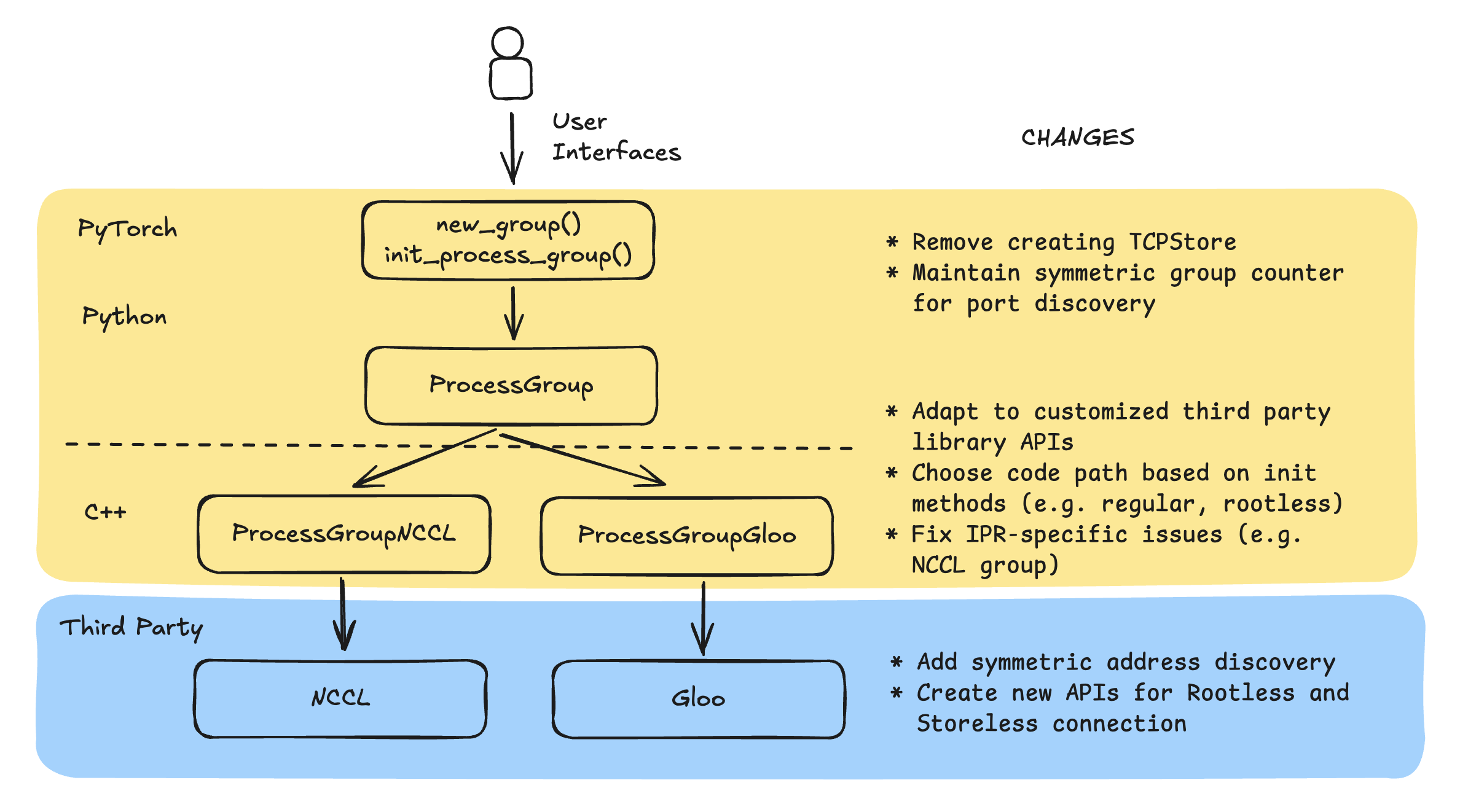
NCCL und Gloo
Dies sind unabhängige Pakete, die die Kernfunktionen der kollektiven Kommunikation erfüllen. Sie stellen wichtige APIs wie nccl CommInitRank bereit, um Kommunikationsnetzwerke zu initialisieren, die zugrunde liegenden Ressourcen zu verwalten und kollektive Kommunikation durchzuführen. Nachdem Sie benutzerdefinierte Änderungen in NCCL und Gloo vorgenommen haben, optimieren Rootless und Storeless die Initialisierung des Kommunikationsnetzwerks (z. B. überspringen Sie die Verbindung zum TCPStore). Sie können flexibel zwischen der Verwendung der ursprünglichen Codepfade und der optimierten Codepfade wechseln.
PyTorch Prozessgruppen-Backend
Die Prozessgruppen-Backends, insbesondere ProcessGroup NCCL und ProcessGroupGloo, implementieren die ProcessGroup APIs, indem sie die APIs der entsprechenden zugrunde liegenden Bibliotheken aufrufen. Da wir die APIs der Drittanbieterbibliotheken erweitern, müssen wir sie ordnungsgemäß aufrufen und Codepfadwechsel auf der Grundlage der Kundenkonfigurationen vornehmen.
Zusätzlich zu den Optimierungscodepfaden ändern wir auch das Prozessgruppen-Backend, um die Wiederherstellung während des Prozesses zu unterstützen.
