Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
# Optimieren Sie PostgreSQL-Bereitstellungen auf Amazon EKS mithilfe von PGO
*Shalaka Dengale, Amazon Web Services*
## Zusammenfassung
Dieses Muster integriert den Postgres-Operator von Crunchy Data (PGO) mit Amazon Elastic Kubernetes Service (Amazon EKS), um PostgreSQL-Bereitstellungen in cloudnativen Umgebungen zu optimieren. PGO bietet Automatisierung und Skalierbarkeit für die Verwaltung von PostgreSQL-Datenbanken in Kubernetes. Wenn Sie PGO mit Amazon EKS kombinieren, bildet es eine robuste Plattform für die effiziente Bereitstellung, Verwaltung und Skalierung von PostgreSQL-Datenbanken.
Diese Integration bietet die folgenden Hauptvorteile:
+ Automatisierte Bereitstellung: Vereinfacht die Bereitstellung und Verwaltung von PostgreSQL-Clustern.
+ Benutzerdefinierte Ressourcendefinitionen (CRDs):**** Verwendet Kubernetes-Primitive für das PostgreSQL-Management.
+ Hohe Verfügbarkeit: Unterstützt automatisches Failover und synchrone Replikation.
+ Automatisierte Backups und Wiederherstellungen:**** Optimiert Sicherungs- und Wiederherstellungsprozesse.
+ Horizontale Skalierung:**** Ermöglicht die dynamische Skalierung von PostgreSQL-Clustern.
+ Versionsupgrades: Ermöglicht fortlaufende Upgrades mit minimalen Ausfallzeiten.
+ Sicherheit: Erzwingt Verschlüsselungs-, Zugriffskontrollen und Authentifizierungsmechanismen.
## Voraussetzungen und Einschränkungen
**Voraussetzungen**
+ Ein aktiver AWS-Konto.
+ [AWS-Befehlszeilenschnittstelle (AWS CLI) Version 2](https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html), installiert und konfiguriert unter Linux, macOS oder Windows.
+ [AWS CLI Config](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-quickstart.html), um AWS Ressourcen über die Befehlszeile zu verbinden.
+ [eksctl](https://github.com/eksctl-io/eksctl#installation), installiert und konfiguriert unter Linux, MacOS oder Windows.
+ `kubectl`, installiert und konfiguriert für den Zugriff auf Ressourcen in Ihrem Amazon EKS-Cluster. Weitere Informationen finden Sie unter [Kubectl und eksctl einrichten in der Amazon EKS-Dokumentation](https://docs.aws.amazon.com/eks/latest/userguide/install-kubectl.html).
+ Ihr Computerterminal ist für den Zugriff auf den Amazon EKS-Cluster konfiguriert. Weitere Informationen finden [Sie in der Amazon EKS-Dokumentation unter Konfiguration Ihres Computers für die Kommunikation mit Ihrem Cluster](https://docs.aws.amazon.com/eks/latest/userguide/getting-started-console.html#eks-configure-kubectl).
**Produktversionen**
+ [Kubernetes-Versionen 1.21—1.24 oder höher (siehe PGO-Dokumentation).](https://access.crunchydata.com/documentation/postgres-operator/5.2.5/)
+ PostgreSQL Version 10 oder höher. Dieses Muster verwendet PostgreSQL Version 16.
**Einschränkungen**
+ Einige AWS-Services sind nicht in allen verfügbar. AWS-Regionen Informationen zur Verfügbarkeit in den einzelnen Regionen finden Sie [AWS-Services unter Nach Regionen](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/). Informationen zu bestimmten Endpunkten finden Sie auf der Seite [Dienstendpunkte und Kontingente](https://docs.aws.amazon.com/general/latest/gr/aws-service-information.html). Wählen Sie dort den Link für den Dienst aus.
## Architektur
**Zieltechnologie-Stack**
+ Amazon EKS
+ Amazon Virtual Private Cloud (Amazon VPC)
+ Amazon Elastic Compute Cloud (Amazon EC2)
**Zielarchitektur**
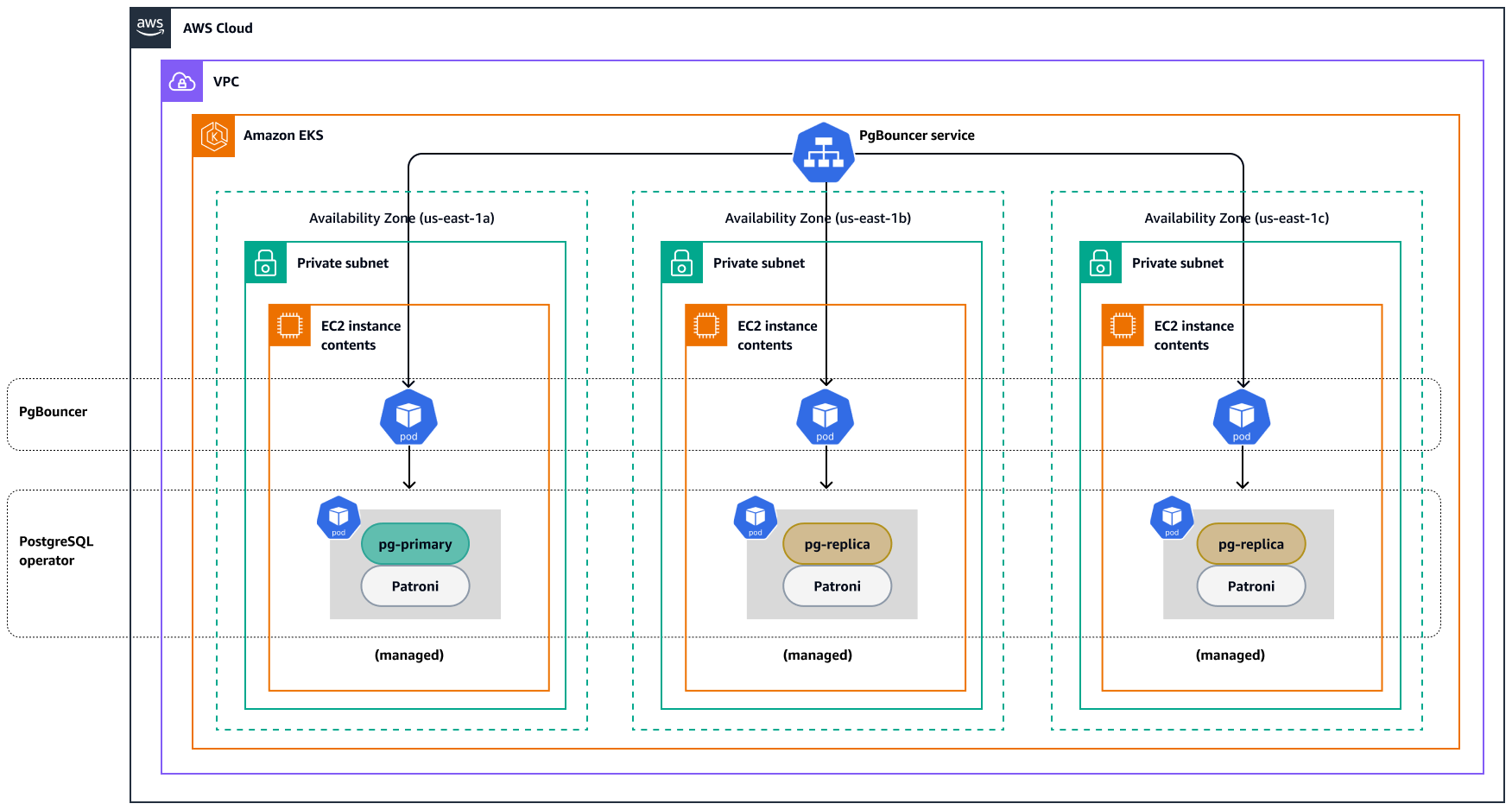
Dieses Muster erstellt eine Architektur, die einen Amazon EKS-Cluster mit drei Knoten enthält. Jeder Knoten läuft auf einer Reihe von EC2-Instances im Backend. Dieses PostgreSQL-Setup folgt einer primären Replikatarchitektur, die besonders für leseintensive Anwendungsfälle effektiv ist. Die Architektur umfasst die folgenden Komponenten:
+ Der **primäre Datenbankcontainer (pg-primary)** hostet die PostgreSQL-Hauptinstanz, an die alle Schreibvorgänge gerichtet sind.
+ **Sekundäre Replikatcontainer (pg-replica)** hosten die PostgreSQL-Instanzen, die die Daten aus der Primärdatenbank replizieren und Lesevorgänge abwickeln.
+ **PgBouncer**ist ein leichter Verbindungspooler für PostgreSQL-Datenbanken, der in PGO enthalten ist. Es befindet sich zwischen dem Client und dem PostgreSQL-Server und fungiert als Vermittler für Datenbankverbindungen.
+ **PGO** automatisiert die Bereitstellung und Verwaltung von PostgreSQL-Clustern in dieser Kubernetes-Umgebung.
+ **Patroni** ist ein Open-Source-Tool, das Hochverfügbarkeitskonfigurationen für PostgreSQL verwaltet und automatisiert. Es ist in PGO enthalten. Wenn Sie Patroni mit PGO in Kubernetes verwenden, spielt dies eine entscheidende Rolle bei der Sicherstellung der Widerstandsfähigkeit und Fehlertoleranz eines PostgreSQL-Clusters. [Weitere Informationen finden Sie in der Patroni-Dokumentation.](https://patroni.readthedocs.io/en/latest/)
Der Workflow umfasst die folgenden Schritte:
+ **Stellen Sie den PGO-Operator** bereit. Sie stellen den PGO-Operator auf Ihrem Kubernetes-Cluster bereit, der auf Amazon EKS läuft. Dies kann mithilfe von Kubernetes-Manifesten oder Helm-Diagrammen erfolgen. Dieses Muster verwendet Kubernetes-Manifeste.
+ **Definieren Sie PostgreSQL-Instanzen**. Wenn der Operator ausgeführt wird, erstellen Sie benutzerdefinierte Ressourcen (CRs), um den gewünschten Status von PostgreSQL-Instanzen anzugeben. Dazu gehören Konfigurationen wie Speicher-, Replikations- und Hochverfügbarkeitseinstellungen.
+ **Betreiberverwaltung**. Sie interagieren mit dem Operator über Kubernetes-API-Objekte, z. B. CRs um PostgreSQL-Instanzen zu erstellen, zu aktualisieren oder zu löschen.
+ **Überwachung und Wartung.** Sie können den Zustand und die Leistung der PostgreSQL-Instances überwachen, die auf Amazon EKS ausgeführt werden. Betreiber stellen häufig Metriken und Protokollierung zu Überwachungszwecken bereit. Sie können bei Bedarf routinemäßige Wartungsaufgaben wie Upgrades und Patches durchführen. Weitere Informationen finden Sie unter [Überwachen der Cluster-Leistung und Anzeigen von Protokollen](https://docs.aws.amazon.com/eks/latest/userguide/eks-observe.html) in der Amazon EKS-Dokumentation.
+ **Skalierung und Backup**: Sie können die vom Betreiber bereitgestellten Funktionen verwenden, um PostgreSQL-Instanzen zu skalieren und Backups zu verwalten.
Dieses Muster deckt keine Überwachungs-, Wartungs- und Sicherungsvorgänge ab.
**Automatisierung und Skalierung**
+ Sie können es verwenden CloudFormation , um die Erstellung der Infrastruktur zu automatisieren. Weitere Informationen finden Sie unter [Amazon EKS-Ressourcen erstellen mit CloudFormation](https://docs.aws.amazon.com/eks/latest/userguide/creating-resources-with-cloudformation.html) in der Amazon EKS-Dokumentation.
+ Sie können Build Numbers GitVersion oder Jenkins verwenden, um die Bereitstellung von Datenbank-Instances zu automatisieren.
## Tools
**AWS-Services**
+ Mit [Amazon Elastic Kubernetes Service (Amazon EKS)](https://docs.aws.amazon.com/eks/latest/userguide/getting-started.html) können Sie Kubernetes ausführen, AWS ohne dass Sie Ihre eigene Kubernetes-Steuerebene oder Knoten installieren oder verwalten müssen.
+ [AWS Command Line Interface (AWS CLI)](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html) ist ein Open-Source-Tool, mit dem Sie über Befehle in Ihrer Befehlszeilen-Shell interagieren AWS-Services können.
**Andere Tools**
+ [eksctl](https://eksctl.io/) ist ein einfaches Befehlszeilentool zum Erstellen von Clustern auf Amazon EKS.
+ [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) ist ein Befehlszeilenprogramm zum Ausführen von Befehlen für Kubernetes-Cluster.
+ [PGO](https://github.com/CrunchyData/postgres-operator) automatisiert und skaliert die Verwaltung von PostgreSQL-Datenbanken in Kubernetes.
## Best Practices
Folgen Sie diesen Best Practices, um eine reibungslose und effiziente Bereitstellung zu gewährleisten:
+ **Schützen Sie Ihren EKS-Cluster**. Implementieren Sie bewährte Sicherheitsmethoden für Ihren EKS-Cluster, z. B. die Verwendung von AWS Identity and Access Management (IAM-) Rollen für Dienstkonten (IRSA), Netzwerkrichtlinien und VPC-Sicherheitsgruppen. Beschränken Sie den Zugriff auf den EKS-Cluster-API-Server und verschlüsseln Sie die Kommunikation zwischen den Knoten und dem API-Server mithilfe von TLS.
+ **Stellen Sie die Versionskompatibilität** zwischen PGO und Kubernetes sicher, die auf Amazon EKS ausgeführt werden. Einige PGO-Funktionen erfordern möglicherweise bestimmte Kubernetes-Versionen oder führen zu Kompatibilitätseinschränkungen. Weitere Informationen finden Sie in der PGO-Dokumentation unter [Komponenten und Kompatibilität](https://access.crunchydata.com/documentation/postgres-operator/5.2.5/references/components/).
+ **Planen Sie die Ressourcenzuweisung** für Ihre PGO-Bereitstellung, einschließlich CPU, Arbeitsspeicher und Speicher. Berücksichtigen Sie die Ressourcenanforderungen sowohl von PGO als auch der von ihr verwalteten PostgreSQL-Instanzen. Überwachen Sie die Ressourcennutzung und skalieren Sie die Ressourcen nach Bedarf.
+ **Design für hohe Verfügbarkeit**. Gestalten Sie Ihre PGO-Bereitstellung für hohe Verfügbarkeit, um Ausfallzeiten zu minimieren und die Zuverlässigkeit zu gewährleisten. Stellen Sie aus Gründen der Fehlertoleranz mehrere PGO-Repliken in mehreren Availability Zones bereit.
+ **Implementieren Sie Sicherungs- und Wiederherstellungsverfahren** für Ihre von PGO verwalteten PostgreSQL-Datenbanken. Verwenden Sie Funktionen von PGO oder Backup-Lösungen von Drittanbietern, die mit Kubernetes und Amazon EKS kompatibel sind.
+ **Richten Sie die Überwachung und Protokollierung** für Ihre PGO-Bereitstellung ein, um Leistung, Zustand und Ereignisse zu verfolgen. Verwenden Sie Tools wie Prometheus für die Überwachung von Metriken und Grafana für die Visualisierung. Konfigurieren Sie die Protokollierung, um PGO-Protokolle zur Fehlerbehebung und Prüfung zu erfassen.
+ **Konfigurieren Sie das Netzwerk** ordnungsgemäß, um die Kommunikation zwischen PGO, PostgreSQL-Instanzen und anderen Diensten in Ihrem Kubernetes-Cluster zu ermöglichen. Verwenden Sie Amazon VPC-Netzwerkfunktionen und Kubernetes-Netzwerk-Plugins wie Calico oder [Amazon VPC CNI](https://github.com/aws/amazon-vpc-cni-k8s) für die Durchsetzung von Netzwerkrichtlinien und die Isolierung des Datenverkehrs.
+ **Wählen Sie geeignete Speicheroptionen** für Ihre PostgreSQL-Datenbanken aus und berücksichtigen Sie dabei Faktoren wie Leistung, Haltbarkeit und Skalierbarkeit. Verwenden Sie Amazon Elastic Block Store (Amazon EBS) -Volumes oder AWS verwaltete Speicherdienste für persistenten Speicher. Weitere Informationen finden Sie unter [Speichern von Kubernetes-Volumes mit Amazon EBS in der Amazon EKS-Dokumentation](https://docs.aws.amazon.com/eks/latest/userguide/ebs-csi.html).
+ **Verwenden Sie Infrastructure-as-Code-Tools (IaC)** CloudFormation , um beispielsweise die Bereitstellung und Konfiguration von PGO auf Amazon EKS zu automatisieren. Definieren Sie Infrastrukturkomponenten — einschließlich des EKS-Clusters, der Netzwerk- und PGO-Ressourcen — als Code, um Konsistenz, Wiederholbarkeit und Versionskontrolle zu gewährleisten.
## Epen
### Erstellen einer IAM-Rolle
| Aufgabe | Description | Erforderliche Fähigkeiten |
| --- | --- | --- |
| Erstellen Sie eine IAM-Rolle. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) | AWS-Administrator |
### Amazon-EKS-Cluster erstellen
| Aufgabe | Description | Erforderliche Fähigkeiten |
| --- | --- | --- |
| Erstellen Sie einen Amazon-EKS-Cluster. | Wenn Sie bereits einen Cluster bereitgestellt haben, überspringen Sie diesen Schritt. Andernfalls stellen Sie einen Amazon EKS-Cluster in Ihrem aktuellen mithilfe AWS-Konto `eksctl` von Terraform oder bereit. CloudFormation Dieses Muster wird `eksctl` für die Cluster-Bereitstellung verwendet.Dieses Muster verwendet Amazon EC2 als Knotengruppe für Amazon EKS. Wenn Sie es verwenden möchten AWS Fargate, lesen Sie die `managedNodeGroups` Konfiguration in der [eksctl-Dokumentation](https://eksctl.io/usage/schema/#managedNodeGroups).[See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) | AWS-Administrator, Terraform- oder eksctl-Administrator, Kubernetes-Administrator |
| Überprüfen Sie den Status des Clusters. | Führen Sie den folgenden Befehl aus, um den aktuellen Status der Knoten im Cluster zu überprüfen:kubectl get nodes
Wenn Sie auf Fehler stoßen, lesen Sie den [Abschnitt zur Fehlerbehebung](https://docs.aws.amazon.com/eks/latest/userguide/troubleshooting.html) in der Amazon EKS-Dokumentation. | AWS-Administrator, Terraform- oder eksctl-Administrator, Kubernetes-Administrator |
### Erstellen Sie einen OIDC-Identitätsanbieter
| Aufgabe | Description | Erforderliche Fähigkeiten |
| --- | --- | --- |
| Aktivieren Sie den IAM OIDC-Anbieter. | Als Voraussetzung für den Amazon EBS Container Storage Interface (CSI) -Treiber benötigen Sie einen vorhandenen IAM OpenID Connect (OIDC) -Anbieter für Ihren Cluster.
Aktivieren Sie den IAM OIDC-Anbieter mit dem folgenden Befehl:eksctl utils associate-iam-oidc-provider --region={region} --cluster={YourClusterNameHere} --approve
Weitere Informationen zu diesem Schritt finden Sie in der [Amazon EKS-Dokumentation](https://docs.aws.amazon.com/eks/latest/userguide/ebs-csi.html). | AWS-Administrator |
| Erstellen Sie eine IAM-Rolle für den Amazon EBS CSI-Treiber. | Verwenden Sie den folgenden `eksctl` Befehl, um die IAM-Rolle für den CSI-Treiber zu erstellen:eksctl create iamserviceaccount \
--region {RegionName} \
--name ebs-csi-controller-sa \
--namespace kube-system \
--cluster {YourClusterNameHere} \
--attach-policy-arn arn:aws:iam::aws:policy/service-role/AmazonEBSCSIDriverPolicy \
--approve \
--role-only \
--role-name AmazonEKS_EBS_CSI_DriverRole
Wenn Sie verschlüsselte Amazon EBS-Laufwerke verwenden, müssen Sie die Richtlinie weiter konfigurieren. Anweisungen finden Sie in der [Amazon EBS SCI-Treiberdokumentation](https://github.com/kubernetes-sigs/aws-ebs-csi-driver/blob/master/docs/install.md#installation-1). | AWS-Administrator |
| Fügen Sie den Amazon EBS CSI-Treiber hinzu. | Verwenden Sie den folgenden `eksctl` Befehl, um den Amazon EBS CSI-Treiber hinzuzufügen:eksctl create addon \
--name aws-ebs-csi-driver \
--cluster service-account-role-arn arn:aws:iam::$(aws sts get-caller-identity \
--query Account \
--output text):role/AmazonEKS_EBS_CSI_DriverRole \
--force
| AWS-Administrator |
### Installieren Sie PGO
| Aufgabe | Description | Erforderliche Fähigkeiten |
| --- | --- | --- |
| Klonen Sie das PGO-Repository. | Klonen Sie das GitHub Repository für PGO:git clone https://github.com/CrunchyData/postgres-operator-examples.git
| AWS DevOps |
| Geben Sie die Rollendetails für die Erstellung des Dienstkontos an. | Um dem Amazon EKS-Cluster Zugriff auf die erforderlichen AWS Ressourcen zu gewähren, geben Sie den Amazon-Ressourcennamen (ARN) der OIDC-Rolle an, die Sie zuvor erstellt haben, in der `service_account.yaml` Datei, die sich unter befindet. [GitHub](https://github.com/CrunchyData/postgres-operator/blob/main/config/rbac/cluster/service_account.yaml)cd postgres-operator-examples
---
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam:::role/ # Update the OIDC role ARN created earlier
| AWS-Administrator, Kubernetes-Administrator |
| Erstellen Sie den Namespace und die PGO-Voraussetzungen. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) | Kubernetes-Administrator |
| Überprüfen Sie die Erstellung von Pods. | Stellen Sie sicher, dass der Namespace und die Standardkonfiguration erstellt wurden:kubectl get pods -n postgres-operator
| AWS-Administrator, Kubernetes-Administrator |
| Verifizieren. PVCs | Verwenden Sie den folgenden Befehl, um Ansprüche auf persistente Volumes (PVCs) zu überprüfen:kubectl describe pvc -n postgres-operator
| AWS-Administrator, Kubernetes-Administrator |
### Erstellen Sie einen Operator und stellen Sie ihn bereit
| Aufgabe | Description | Erforderliche Fähigkeiten |
| --- | --- | --- |
| Erstellen Sie einen Operator. | Überarbeiten Sie den Inhalt der Datei unter`/kustomize/postgres/postgres.yaml`, sodass er den folgenden Kriterien entspricht:spec:
instances:
- name: pg-1
replicas: 3
patroni:
dynamicConfiguration:
postgresql:
pg_hba:
- "host all all 0.0.0.0/0 trust" # this line enabled logical replication with programmatic access
- "host all postgres 127.0.0.1/32 md5"
synchronous_mode: true
users:
- name: replicator
databases:
- testdb
options: "REPLICATION"
Diese Updates bewirken Folgendes:[See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) | AWS-Administrator, DBA, Kubernetes-Administrator |
| Stellen Sie den Operator bereit. | Stellen Sie den PGO-Operator bereit, um die Verwaltung und den Betrieb von PostgreSQL-Datenbanken in Kubernetes-Umgebungen zu optimieren:kubectl apply -k kustomize/postgres
| AWS-Administrator, DBA, Kubernetes-Administrator |
| Überprüfen Sie die Bereitstellung. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html)Notieren Sie sich in der Befehlsausgabe das primäre Replikat (`primary_pod_name`) und das Lesereplikat (`read_pod_name`). Sie werden diese in den nächsten Schritten verwenden. | AWS-Administrator, DBA, Kubernetes-Administrator |
### Überprüfen Sie die Streaming-Replikation
| Aufgabe | Description | Erforderliche Fähigkeiten |
| --- | --- | --- |
| Schreiben Sie Daten in das primäre Replikat. | Verwenden Sie die folgenden Befehle, um eine Verbindung zum primären PostgreSQL-Replikat herzustellen und Daten in die Datenbank zu schreiben:kubectl exec -it bash -n postgres-operator
psql
CREATE TABLE customers (firstname text, customer_id serial, date_created timestamp);
\dt
| AWS-Administrator, Kubernetes-Administrator |
| Vergewissern Sie sich, dass die Read Replica dieselben Daten enthält. | Connect zur PostgreSQL-Read Replica her und überprüfen Sie, ob die Streaming-Replikation ordnungsgemäß funktioniert:kubectl exec -it {read_pod_name} bash -n postgres-operatorpsql
\dt
Die Read Replica sollte die Tabelle enthalten, die Sie im vorherigen Schritt im primären Replikat erstellt haben. | AWS-Administrator, Kubernetes-Administrator |
## Fehlerbehebung
| Problem | Lösung |
| --- | --- |
| Der Pod startet nicht. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) |
| Replikate liegen deutlich hinter der Primärdatenbank zurück. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) |
| Sie haben keinen Einblick in die Leistung und den Zustand des PostgreSQL-Clusters. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) |
| Die Replikation funktioniert nicht. | [See the AWS documentation website for more details](http://docs.aws.amazon.com/de_de/prescriptive-guidance/latest/patterns/streamline-postgresql-deployments-amazon-eks-pgo.html) |
## Zugehörige Ressourcen
+ [Amazon Elastic Kubernetes Service](https://docs.aws.amazon.com/whitepapers/latest/overview-deployment-options/amazon-elastic-kubernetes-service.html) (*Überblick über Bereitstellungsoptionen auf AWS-Whitepaper*)
+ [CloudFormation](https://docs.aws.amazon.com/whitepapers/latest/overview-deployment-options/aws-cloudformation.html)(*Whitepaper über die Bereitstellungsoptionen auf AWS*)
+ [Erste Schritte mit Amazon EKS — eksctl](https://docs.aws.amazon.com/eks/latest/userguide/getting-started-eksctl.html) (*Amazon EKS-Benutzerhandbuch*)
+ [Kubectl und eksctl einrichten (*Amazon* EKS-Benutzerhandbuch](https://docs.aws.amazon.com/eks/latest/userguide/install-kubectl.html))
+ [Eine Rolle für den OpenID Connect-Verbund erstellen](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-idp_oidc.html) (*IAM-Benutzerhandbuch*)
+ [Konfiguration der Einstellungen für das AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) (*AWS CLI Benutzerhandbuch*)
+ [Dokumentation zu Crunchy Postgres für Kubernetes](https://access.crunchydata.com/documentation/postgres-operator/latest)
+ [Crunch & Learn: Crunchy Postgres für Kubernetes 5.0 (Video](https://www.youtube-nocookie.com/embed/IIf9WZO3K50))