Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anwendungsüberwachung
Die Anwendungsüberwachung bietet einen Echtzeitüberblick über die Leistung Ihrer Dienste. Es kombiniert in Amazon Managed Service for Prometheus gespeicherte Topologiedaten OpenSearch mit RED-Metriken (Rate, Errors, Duration) für Zeitreihen, um Informationen zu Zustand, Latenz, Durchsatz und Fehlern in Ihrem gesamten verteilten System zu ermitteln.
Um auf die Anwendungsüberwachung zuzugreifen, navigieren Sie in der OpenSearch Benutzeroberfläche zu Observability > Application Monitoring. Die Seitenleiste zeigt zwei Ansichten:
-
Anwendungsübersicht — Interaktives Topologiediagramm der Dienstabhängigkeiten
-
Dienste — Katalog aller instrumentierten Dienste mit Filtern, Detailansichten und Korrelationslinks
Voraussetzungen
Bevor Sie die Anwendungsüberwachung verwenden können, müssen Sie die folgenden Ressourcen konfiguriert haben.
-
OTLP-Trace-Daten, die von Ihren oTel-Collectors zur OpenSearch Erfassung fließen (Metriken und Protokolle sind optional)
-
Ein OpenSearch UI-Workspace mit aktivierter Observability
Funktionsweise
Das folgende Diagramm zeigt die End-to-End-Architektur für die Anwendungsüberwachung.
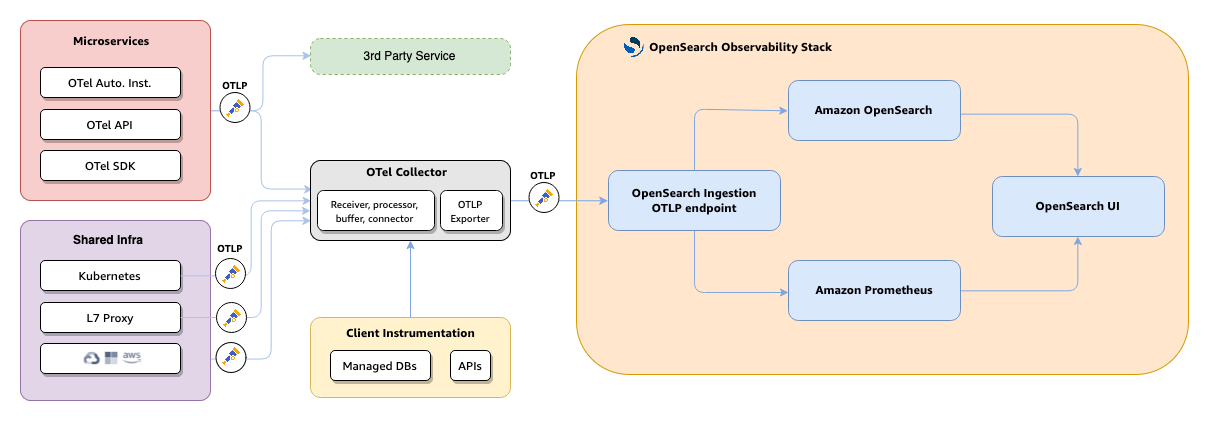
-
Ihre Anwendungen und Infrastruktur senden Telemetrie über OpenTelemetry SDKs, automatische Instrumentierung oder die OTel API an den OTel Collector.
-
Der OTel Collector leitet Trace-Daten über OTLP an OpenSearch Ingestion weiter.
-
Der OpenSearch
otel_apm_service_mapIngestion-Prozessor extrahiert Beziehungen zwischen Diensten und berechnet RED-Metriken. -
Topologie und rohe Trace-Daten werden in indexiert. OpenSearch RED-Metriken werden per Fernschreiben an Amazon Managed Service for Prometheus exportiert.
-
OpenSearch Die Benutzeroberfläche fragt beide Stores ab, um die Anwendungsübersicht, den Servicekatalog und die Service-Detailansichten zu rendern.
Dienstleistungen
Die Serviceansicht bietet einen zentralen Katalog aller instrumentierten Dienste und zeigt die RED-Metriken (Rate, Fehler, Dauer) auf einen Blick an. Mithilfe dieser Ansicht können Sie schnell fehlerhafte Services identifizieren und Detailansichten für tiefere Analysen aufrufen.
Um auf die Serviceansicht zuzugreifen, navigieren Sie in der OpenSearch Benutzeroberfläche zum Observability-Workspace und wählen Sie APM > Services.
Auf der Services-Startseite werden eine Tabelle mit allen instrumentierten Services sowie Übersichtsfenstern angezeigt. Die folgende Abbildung zeigt die Services-Startseite.
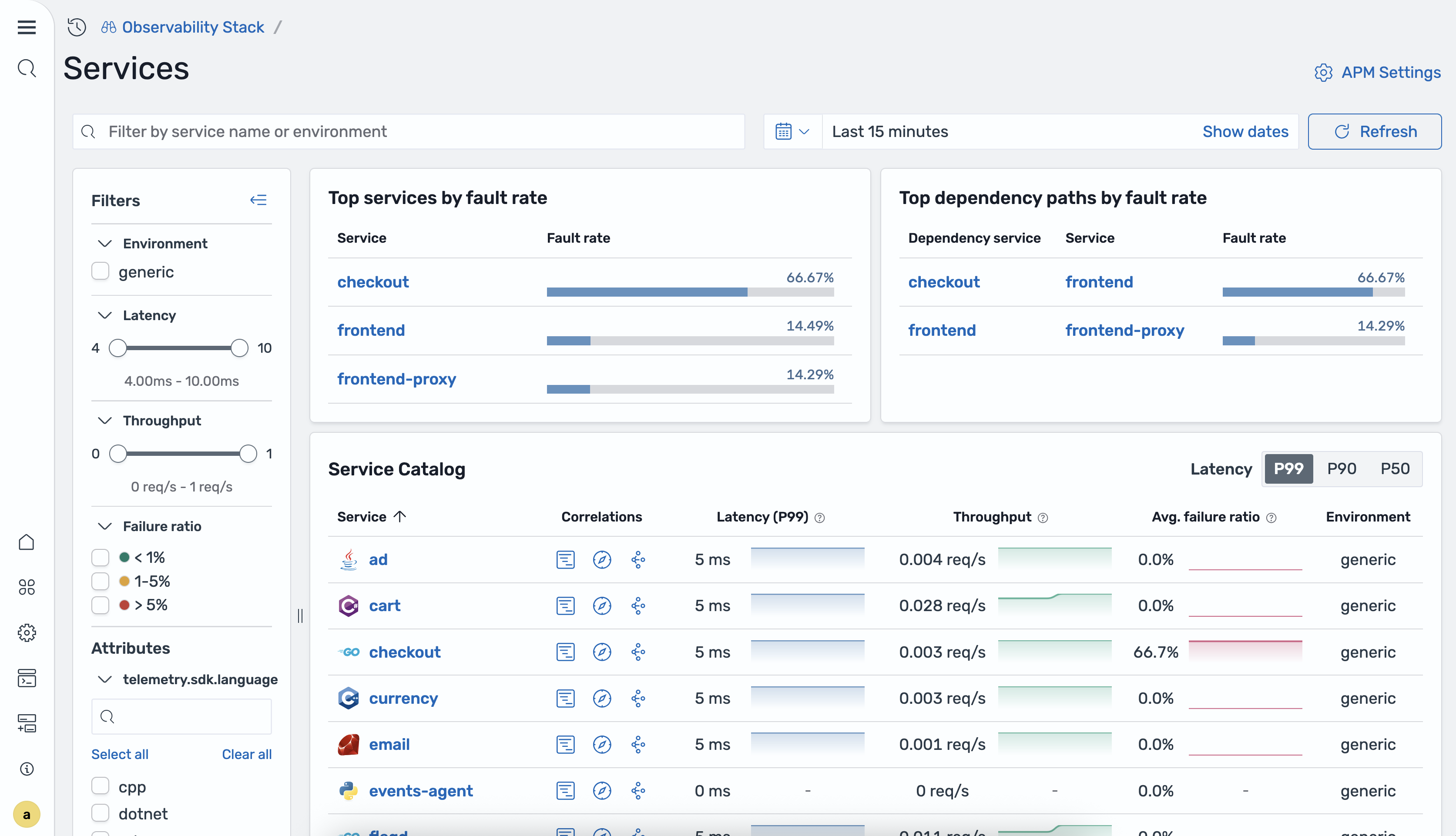
In der folgenden Tabelle werden die Spalten in der Servicetabelle beschrieben.
| Spalte | Description |
|---|---|
| Service-Name | Der Name des instrumentierten Dienstes. |
| P99-Latenz | Die 99. Perzentil-Latenz für den Dienst. |
| P90-Latenz | Die 90. Perzentil-Latenz für den Dienst. |
| P50-Latenz | Die Latenz im 50. Perzentil (Median) für den Dienst. |
| Anforderungen insgesamt | Die Gesamtzahl der Anfragen, die im ausgewählten Zeitraum verarbeitet wurden. |
| Fehlerquote | Das Verhältnis der fehlgeschlagenen Anfragen zur Gesamtzahl der Anfragen. |
| Umgebung | Die Bereitstellungsumgebung des Dienstes, z. B. production oderstaging. |
Die Startseite enthält auch die folgenden Übersichtsbereiche:
-
Top-Dienste nach Fehlerrate — Dienste mit dem höchsten Prozentsatz von 5xx Antworten.
-
Pfade mit den meisten Abhängigkeiten nach Fehlerrate — Service-to-service Abhängigkeitspfade mit den höchsten Fehlerraten.
Sie können die Services-Tabelle mithilfe der folgenden Filter filtern:
-
Umgebung — Filtern Sie nach der Bereitstellungsumgebung.
-
Latenz — Nach Latenzbereich filtern.
-
Durchsatz — Filtert nach Anforderungsdurchsatzbereich.
-
Ausfallrate — Filtert nach Fehlerquotenbereich.
Service-Übersicht
Um die Service-Detailansicht zu öffnen, wählen Sie einen Dienstnamen in der Servicetabelle aus. Auf der Registerkarte „Übersicht“ werden metrische Kacheln und Zeitreihendiagramme für den ausgewählten Service angezeigt.
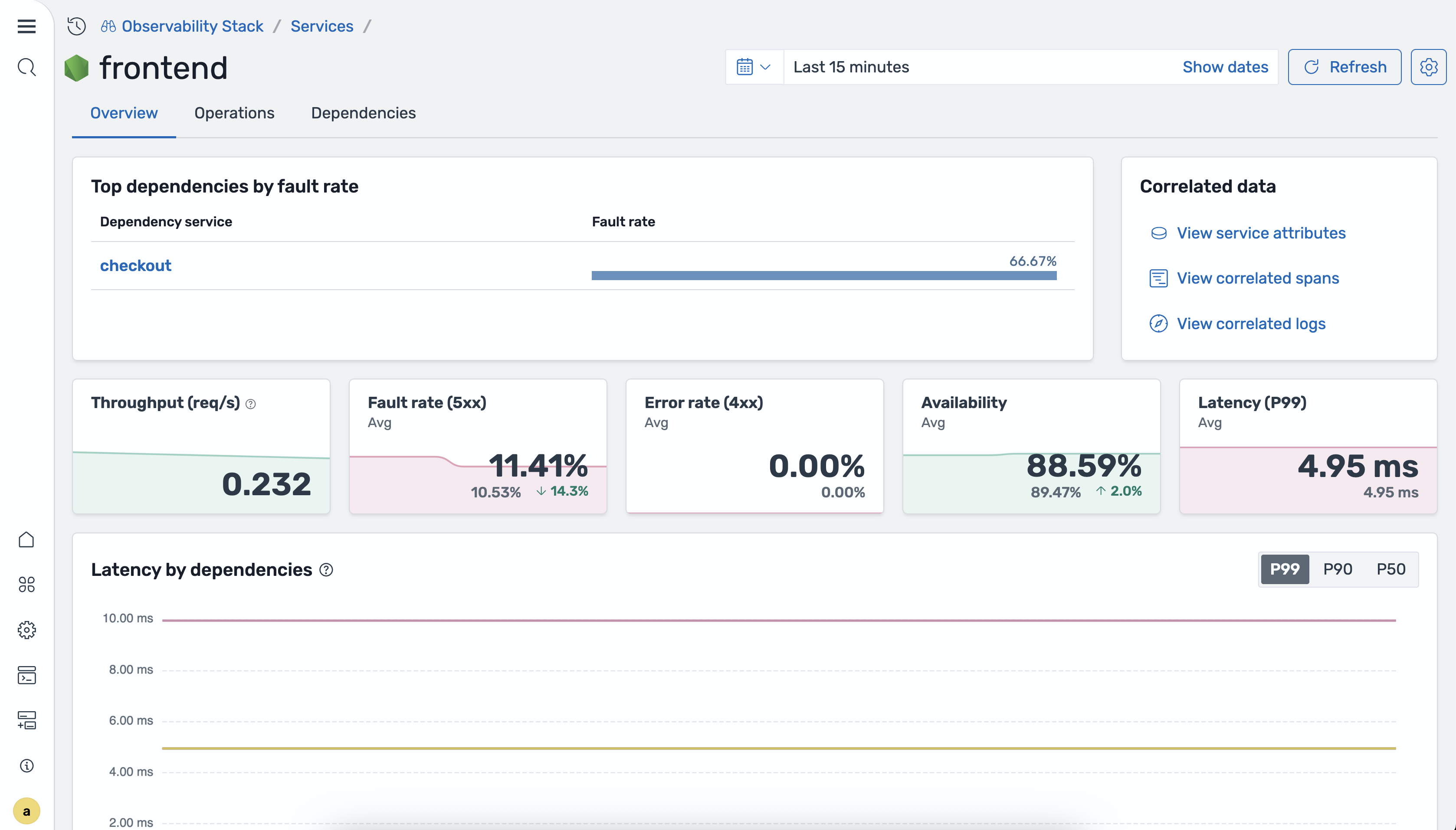
Die Registerkarte „Übersicht“ enthält die folgenden Zeitreihendiagramme:
-
Latenz nach Dienstabhängigkeiten — P50-, P90- und P99-Latenz, aufgeschlüsselt nach Downstream-Abhängigkeiten.
-
Anfragen nach Vorgängen — Anforderungsvolumen für jeden Vorgang des Dienstes.
-
Verfügbarkeit nach Vorgängen — Prozentsatz der erfolgreichen Antworten für jeden Vorgang.
-
Fehlerrate und Fehlerquote nach Vorgängen — Prozentsatz der 5xx- und 4xx-Antworten für jeden Vorgang.
Operationen
Die Registerkarte „Vorgänge“ enthält eine Aufschlüsselung nach Vorgängen für den ausgewählten Dienst. Sie können die Tabelle nach einer beliebigen Spalte sortieren, um problematische Operationen zu identifizieren.
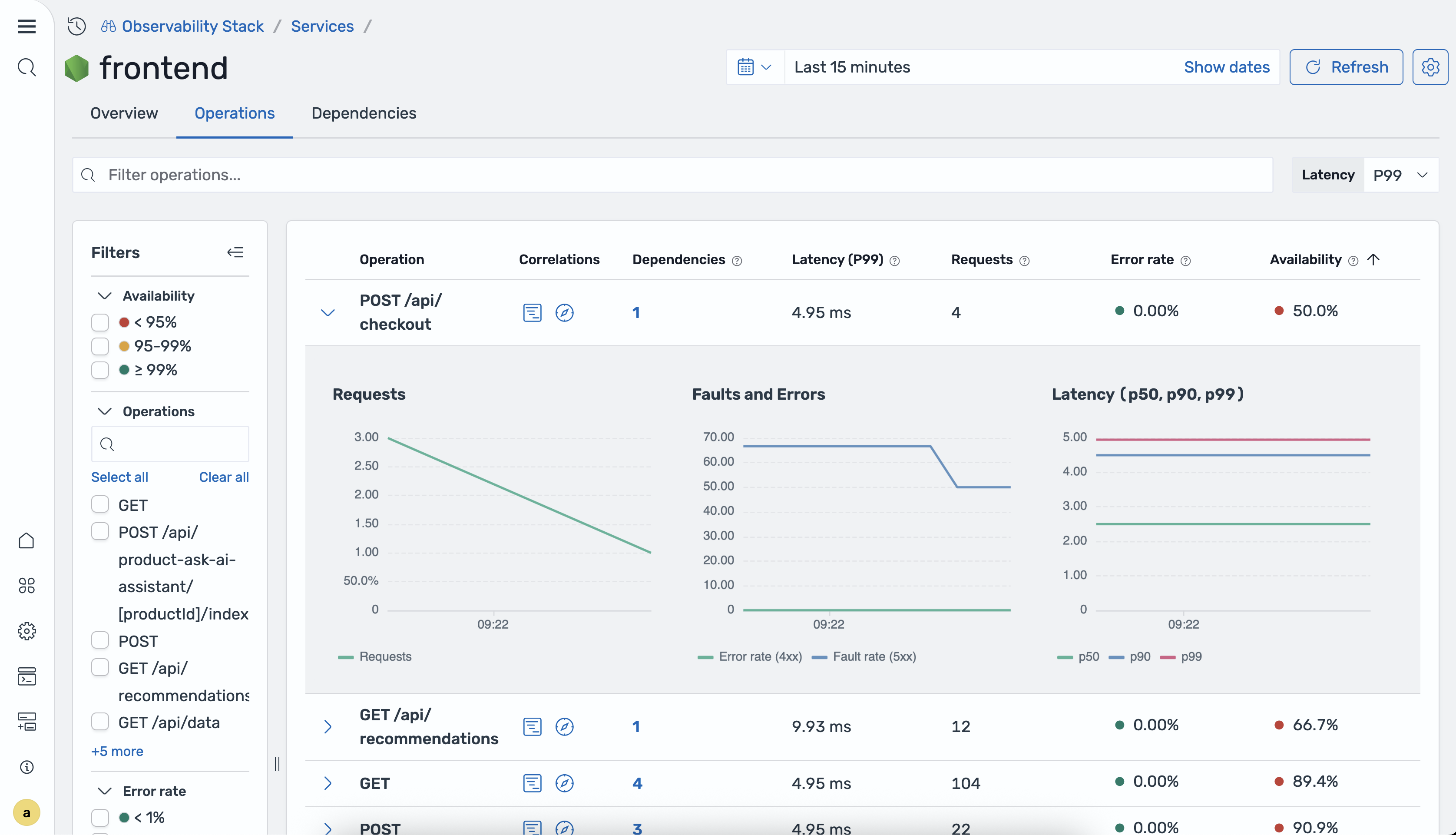
In der folgenden Tabelle werden die Spalten in der Operationstabelle beschrieben.
| Spalte | Description |
|---|---|
| Vorgangsname | Der Name der Operation. |
| P50/P90/P99 Latenz | Die Latenz im 50., 90. und 99. Perzentil für den Vorgang. |
| Anforderungen insgesamt | Die Gesamtzahl der Anfragen für den Vorgang im ausgewählten Zeitraum. |
| Fehlerrate | Der Prozentsatz der Anfragen, bei denen Fehler zurückgegeben wurden. |
| Verfügbarkeit | Der Prozentsatz der erfolgreichen Antworten für den Vorgang. |
Abhängigkeiten
Auf der Registerkarte Abhängigkeiten werden die Downstream-Dienste angezeigt, die der ausgewählte Dienst aufruft.
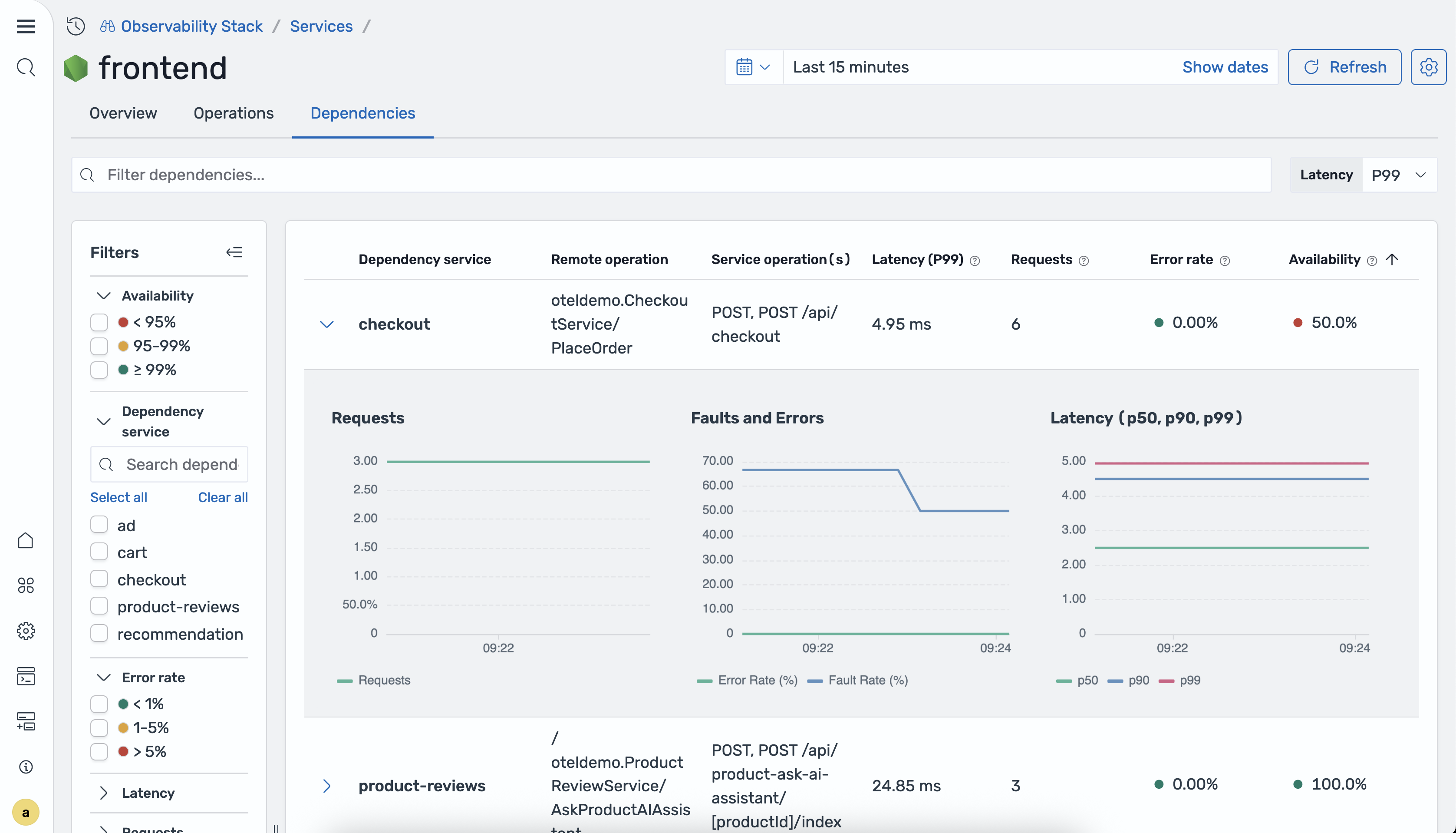
In der folgenden Tabelle werden die Spalten in der Tabelle mit den Abhängigkeiten beschrieben.
| Spalte | Description |
|---|---|
| Dienst für Abhängigkeiten | Der Name des Downstream-Dienstes. |
| Bedienung aus der Ferne | Der Vorgang wurde im Downstream-Dienst aufgerufen. |
| Serviceoperationen | Die Operationen im aktuellen Dienst, die diese Abhängigkeit aufrufen. |
| P99/P90/P50 Latenz | Die Latenz im 99., 90. und 50. Perzentil für den Abhängigkeitspfad. |
| Anforderungen insgesamt | Die Gesamtzahl der Anfragen an die Abhängigkeit im ausgewählten Zeitraum. |
| Fehlerrate | Der Prozentsatz der Anfragen an die Abhängigkeit, bei denen Fehler zurückgegeben wurden. |
| Verfügbarkeit | Der Prozentsatz der erfolgreichen Antworten aus der Abhängigkeit. |
Korrelationen
Die Service-Detailansicht bietet kontextbezogene Korrelationen, mit denen Sie von Servicemetriken direkt zu zugehörigen Traces und Protokollen navigieren können. Sie können Korrelationen verwenden, um die Hauptursache von Latenzspitzen oder erhöhten Fehlerraten zu untersuchen.
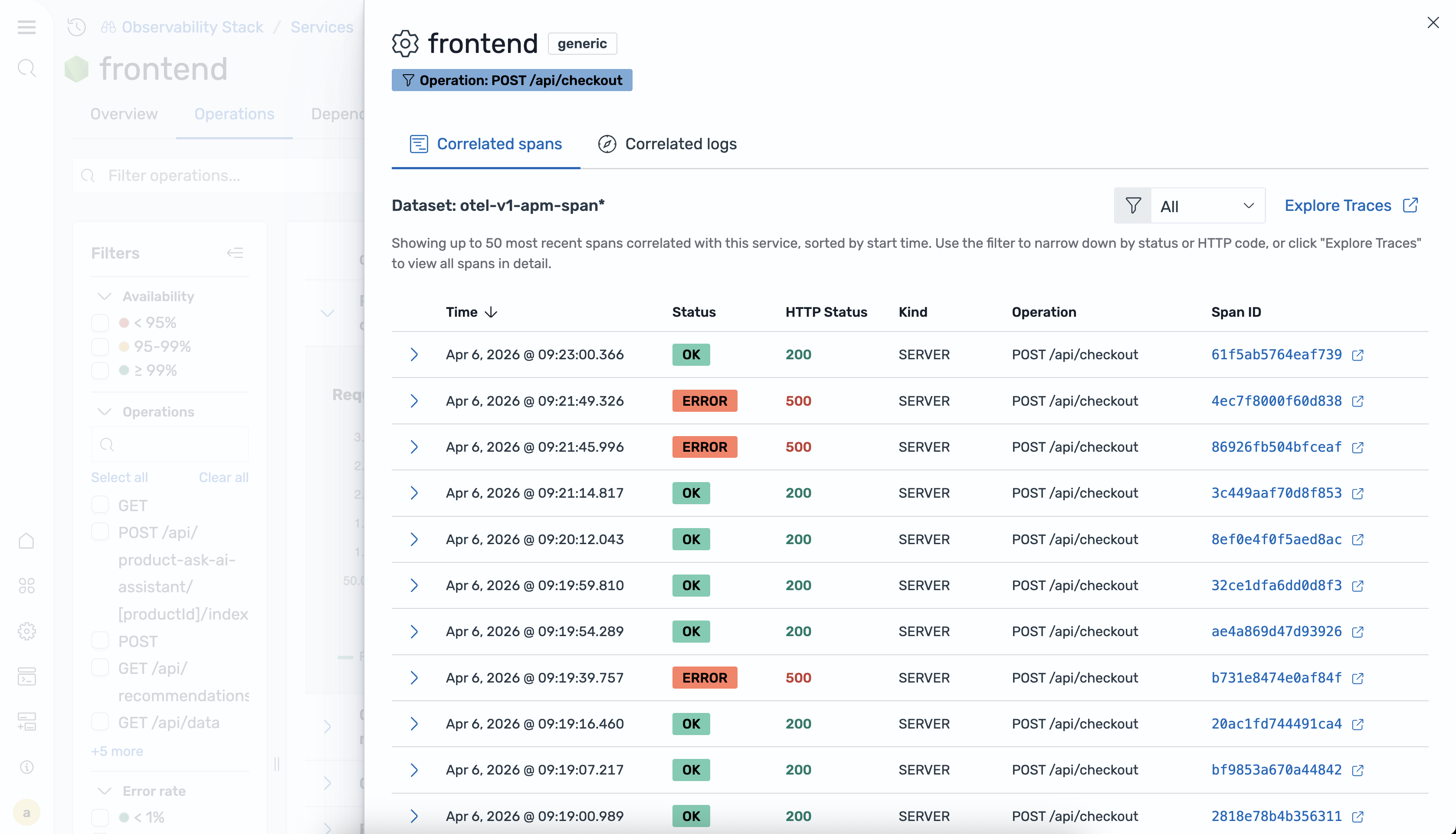
Die folgenden Korrelationsoptionen sind verfügbar:
-
Verwandte Ablaufverfolgungen anzeigen — Öffnet eine gefilterte Ablaufverfolgungsansicht für den ausgewählten Dienst oder Vorgang.
-
Verwandte Protokolle anzeigen — Öffnet eine gefilterte Protokollansicht für den ausgewählten Dienst oder Vorgang.
-
Nach Attributen filtern — Schränkt die Korrelationsergebnisse nach bestimmten Span-Attributen ein.
Übersicht der Anwendung
Die Anwendungsübersicht ist eine interaktive Topologievisualisierung, die OpenSearch Ingestion mithilfe des Prozessors automatisch aus Ihren Trace-Daten generiert. otel_apm_service_map Die Karte zeigt Dienste als Knoten mit Richtungskanten, die Kommunikationsmuster zeigen, überlagert mit RED-Metriken (Rate, Errors, Duration).
Um auf die Anwendungsübersicht zuzugreifen, navigieren Sie in der OpenSearch Benutzeroberfläche zum Observability-Workspace und wählen Sie APM > Application Map.
Die folgende Abbildung zeigt die Anwendungsübersicht.
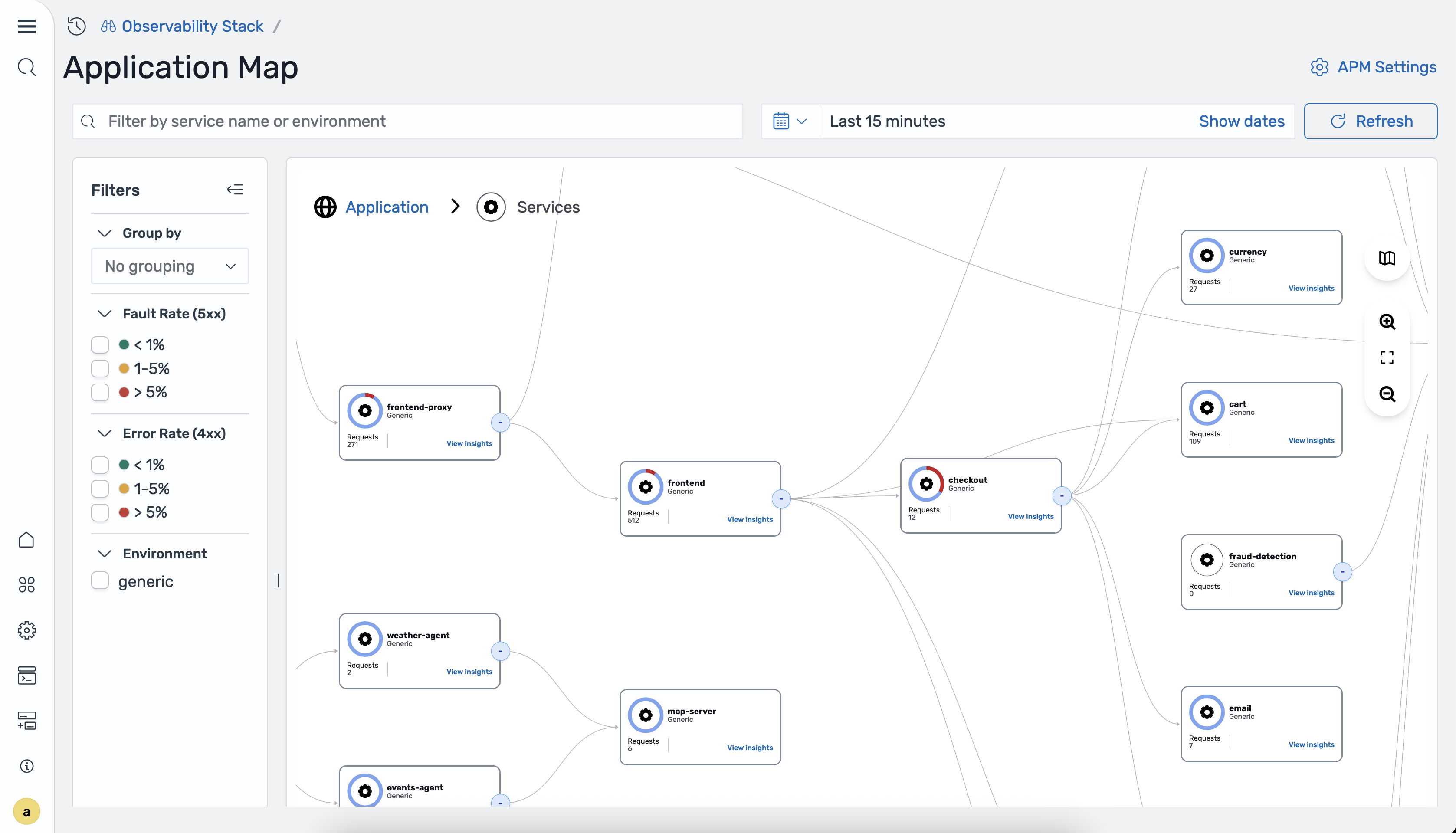
Die Karte zeigt die folgenden RED-Metriken für jeden Service:
-
Rate — Anfragen pro Sekunde, die vom Service verarbeitet werden.
-
Fehler — Prozentsatz der 4xx- und 5xx-Antworten.
-
Dauer — P50- und P99-Latenz für den Dienst.
Der otel_apm_service_map Prozessor generiert diese Metriken und speichert sie per Remote-Schreibzugriff in Amazon Managed Service for Prometheus.
Die Topologievisualisierung stellt Dienste als Knoten und die Kommunikationsrichtung als Kanten dar. Die Farbcodierung gibt den Integritätsstatus der einzelnen Dienste an. Die Karte wird automatisch aktualisiert, wenn OpenSearch Ingestion neue Trace-Daten aufnimmt.
Dienste gruppieren
Sie können Dienste nach Attributen wie Programmiersprache, Team oder Umgebung gruppieren. Wenn Sie ein Gruppierungsattribut auswählen, wechselt die Karte von einem Topologiediagramm zu einer Kartenrasteransicht. Jede Karte steht für eine Gruppe von Diensten, die denselben Attributwert haben.
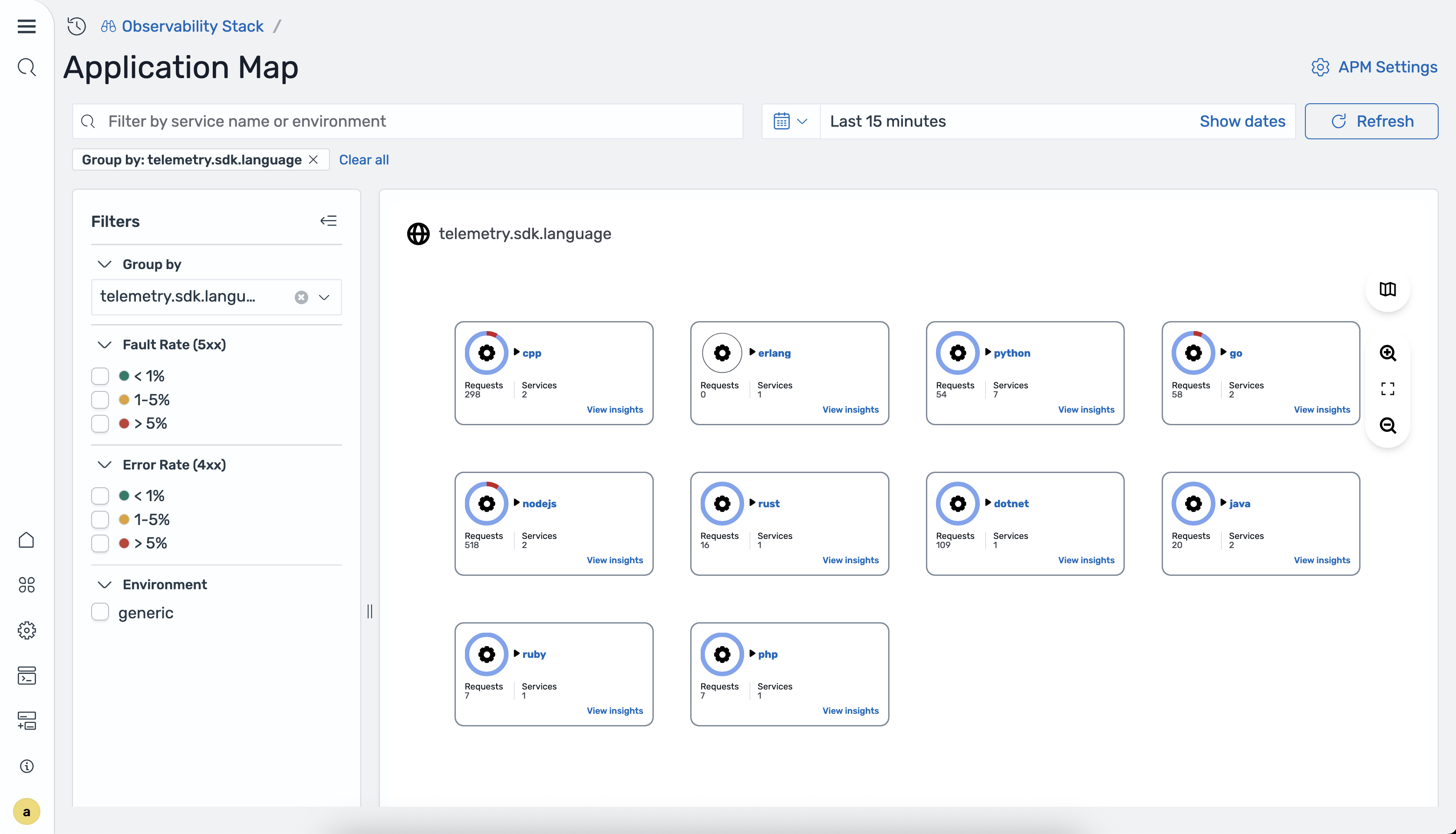
Die verfügbaren Gruppierungsattribute werden durch die group_by_attributes Einstellung in der Prozessorkonfiguration in Ingestion bestimmt. otel_apm_service_map OpenSearch
Knotendetails anzeigen
Um Details für einen Service anzuzeigen, wählen Sie einen Knoten auf der Karte aus. Ein Detailfenster mit den folgenden Abschnitten wird geöffnet.
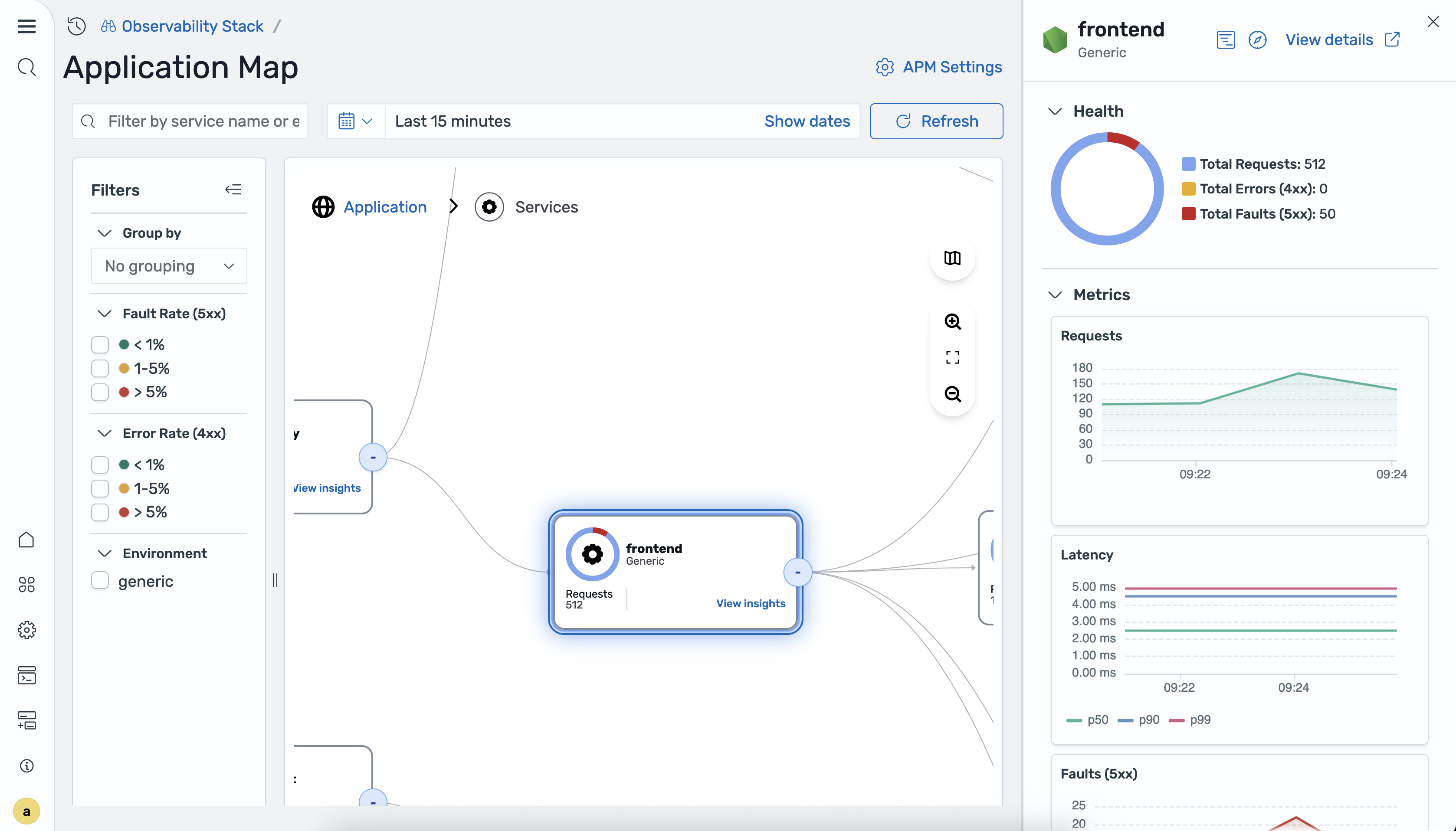
Im Bereich Health werden die folgenden zusammenfassenden Kennzahlen angezeigt:
-
Anfragen insgesamt
-
Gesamtzahl der Fehler: 4xx
-
Gesamtzahl der Fehler 5xx
Im Bereich Metriken werden die folgenden Zeitreihendiagramme angezeigt:
-
Anforderungen
-
Latenz P50/P90/P99
-
Fehler 5xx
-
Fehler 4xx
Wählen Sie „Details anzeigen“, um zur Detailansicht der Dienste für den ausgewählten Dienst zu gelangen.
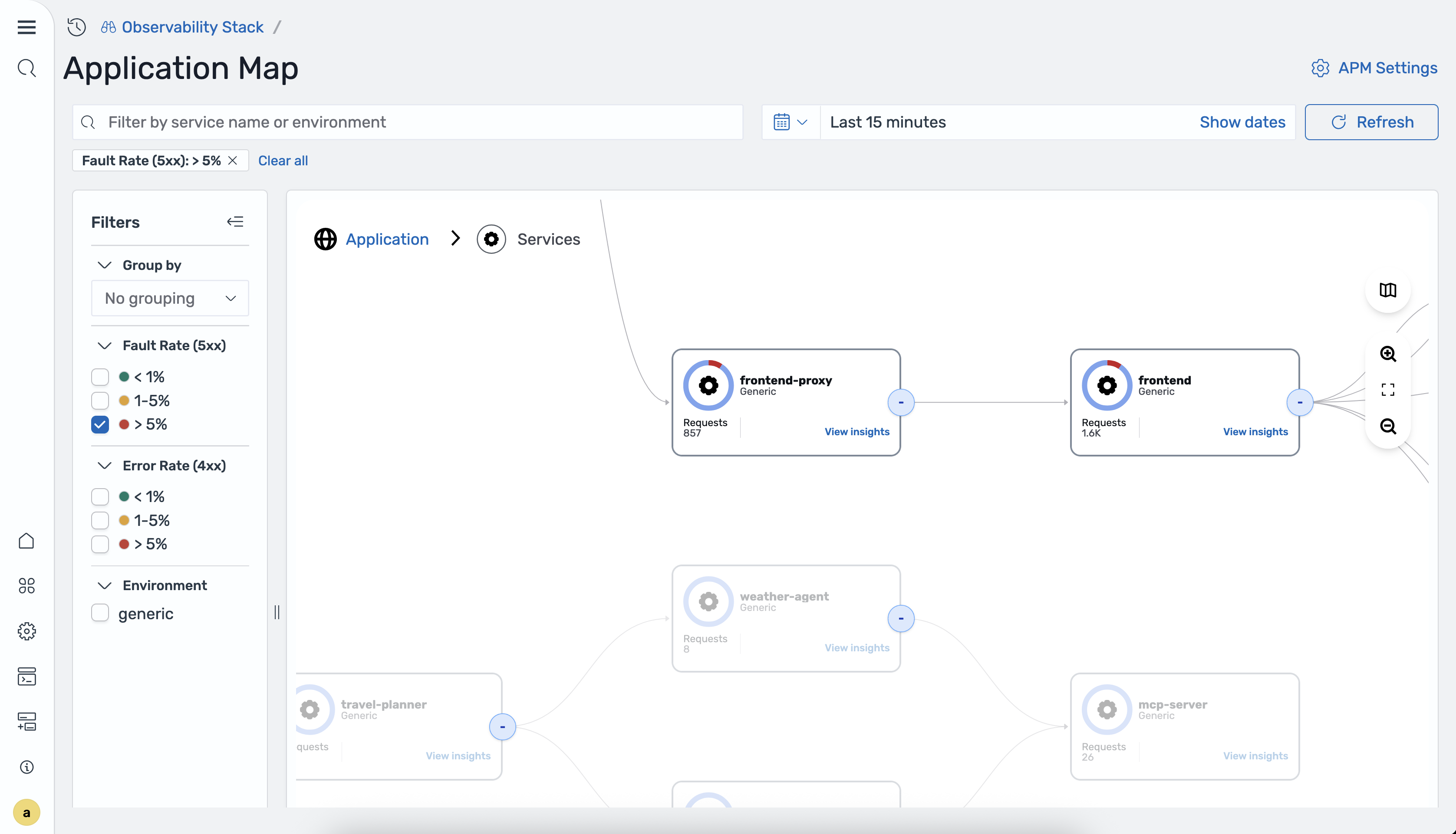
Die Karte filtern
Sie können die Anwendungsübersicht mithilfe der folgenden Filter filtern:
-
Fehlerrate — Filtert Dienste nach serverseitiger Fehlerrate (5xx).
-
Fehlerrate — Filtert Dienste nach der clientseitigen Fehlerrate (4xx).
-
Umgebung — Dienste nach Bereitstellungsumgebung filtern.
Die folgende Abbildung zeigt die Karte, gefiltert nach der Fehlerrate.
In-context Korrelationen
Sie können von der Topologieansicht aus direkt zu zugehörigen Traces und Logs navigieren. Von jedem Serviceknoten aus sind die folgenden Korrelationsoptionen verfügbar:
-
Verwandte Traces anzeigen — Öffnet eine gefilterte Trace-Ansicht für den ausgewählten Service.
-
Verwandte Protokolle anzeigen — Öffnet eine gefilterte Protokollansicht für den ausgewählten Dienst.
