Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Ladeformat für openCypher-Daten
Um openCypher-Daten im openCypher-CSV-Format zu laden, müssen Sie Knoten und Beziehungen in getrennten Dateien angeben. Der Loader kann Daten aus mehreren Knoten- und Beziehungsdateien in einem einzigen Ladeauftrag laden.
Für jeden Ladebefehl muss der Satz von Dateien, die geladen werden sollen, dasselbe Pfadpräfix in einem Amazon-Simple-Storage-Service-Bucket aufweisen. Sie geben dieses Präfix im Quellparameter an. Die tatsächlichen Dateinamen und Dateierweiterungen sind nicht wichtig.
In Amazon Neptune entspricht das openCypher-CSV-Format der CSV-Spezifikation RFC 4180. Weitere Informationen finden Sie unter Gemeinsames Format und MIME-Typ für CSV-Dateien
Anmerkung
Diese Dateien MÜSSEN im UTF-8 Format codiert sein.
Jede Datei hat eine durch Komma getrennte Überschriftenzeile, die Systemspaltenüberschriften und Eigenschaftsspaltenüberschriften enthält.
Systemspaltenüberschriften in openCypher-Dateien zum Laden von Daten
Jede Systemspalte kann nur einmal in einer Überschrift enthalten sein. Bei allen Systemspaltenüberschriften muss die Groß- und Kleinschreibung beachtet werden.
openCypher-Knotenladedateien und Beziehungsladedateien unterscheiden sich hinsichtlich der erforderlichen und zulässigen Systemspaltenüberschriften:
Systemspaltenüberschriften in Knotendateien
-
:ID– (Erforderlich) Eine ID für den Knoten.Der Knoten–
:IDSpaltenüberschrift kann ein optionaler ID-Bereich wie folgt hinzugefügt werden::ID(. Ein Beispiel istID Space):ID(movies).Verwenden Sie beim Laden von Beziehungen, die die Knoten in dieser Datei verbinden, dieselben ID-Leerzeichen in den Spalten der Beziehungsdateien.
:START_IDand/or:END_IDDie Knoten-
:ID-Spalte kann optional als Eigenschaft im Formular gespeichert werden,property name:IDname:ID.Knoten-IDs sollten für alle Knotendateien in den aktuellen und vorherigen Ladevorgängen eindeutig sein. Bei Verwendung eines ID-Bereichs sollten die Knoten-IDs für alle Knotendateien eindeutig sein, die in aktuellen und vorherigen Ladevorgängen denselben ID-Bereich verwenden.
-
:LABEL– Eine Bezeichnung für den Knoten.Wenn Sie mehrere Labelwerte für einen einzelnen Knoten verwenden, sollte jedes Label durch Semikolons () getrennt werden.
;
Systemspaltenüberschriften in Beziehungsdateien
-
:ID– Eine ID für die Beziehung. Dies ist erforderlich, wennuserProvidedEdgeIdswahr ist (Standard), jedoch ungültig, wennuserProvidedEdgeIdsfalseist.Beziehungs-IDs sollten für alle Beziehungsdateien in den aktuellen und vorherigen Ladevorgängen eindeutig sein.
-
:START_ID– (Erforderlich) Die Knoten-ID des Knotens, an dem diese Beziehung beginnt.Optional kann der Start-ID-Spalte ein ID-Bereich im Format
:START_ID(zugeordnet werden. Der ID-Bereich der Startknoten-ID sollte mit dem ID-Bereich übereinstimmen, der dem Knoten in dessen Knotendatei zugewiesen ist.ID Space) -
:END_ID– (Erforderlich) Die Knoten-ID des Knotens, an dem diese Beziehung endet.Optional kann der End-ID-Spalte ein ID-Bereich im Format
:END_ID(zugeordnet werden. Der ID-Bereich der Endknoten-ID sollte mit dem ID-Bereich übereinstimmen, der dem Knoten in dessen Knotendatei zugewiesen ist.ID Space) -
:TYPE– Ein Typ für die Beziehung. Beziehungen können nur einen einzigen Typ haben.
Anmerkung
Informationen zur Behandlung duplizierter Knoten- oder Beziehungs-IDs beim Massenladen finden Sie unter Laden von openCypher-Daten.
Eigenschaftsspaltenüberschriften in openCypher-Dateien zum Laden von Daten
Sie können mit einer Eigenschaftsspaltenüberschrift angeben, dass eine Spalte die Werte für eine bestimmte Eigenschaft enthält. Die Überschrift muss das folgende Format haben:
propertyname:type
Leerzeichen, Kommas, Zeilenumbrüche und Zeilenumbrüche sind in den Spaltenüberschriften nicht zulässig, sodass Eigenschaftsnamen diese Zeichen nicht enthalten dürfen. Dies ist ein Beispiel für die Spaltenüberschrift einer Eigenschaft mit dem Namen age und dem Typ Int.
age:Int
Die Spalte mit age:Int als Spaltenüberschrift müsste dann in jeder Zeile eine Ganzzahl oder einen leeren Wert enthalten.
Datentypen in Neptune openCypher-Dateien zum Laden von Daten
-
BooloderBoolean– Ein boolesches Feld. Zulässige Werte sindtrueundfalse.Jeder andere Wert als
truewird alsfalsebehandelt. -
Byte– Eine ganze Zahl im Bereich von-128bis127. -
Short– Eine ganze Zahl im Bereich von-32,768bis32,767. -
Int– Eine ganze Zahl im Bereich von-2^31bis2^31 - 1. -
Long– Eine ganze Zahl im Bereich von-2^63bis2^63 - 1. -
Float– Eine 32-Bit-Gleitkommazahl nach IEEE 754. Dezimalschreibweise und wissenschaftliche Notation werden unterstützt.Infinity,-InfinityundNaNwerden erkannt,INFjedoch nicht.Werte mit zu vielen Stellen werden auf den nächsten Wert gerundet. (Ein in der Mitte liegender Wert Wert wird für die letzte Stelle auf Bit-Ebene auf 0 gerundet.)
-
Double– Eine 64-Bit-Gleitkommazahl nach IEEE 754. Dezimalschreibweise und wissenschaftliche Notation werden unterstützt.Infinity,-InfinityundNaNwerden erkannt,INFjedoch nicht.Werte mit zu vielen Stellen werden auf den nächsten Wert gerundet. (Ein in der Mitte liegender Wert Wert wird für die letzte Stelle auf Bit-Ebene auf 0 gerundet.)
-
String– Anführungszeichen sind optional. Kommas, Zeilenumbruchzeichen und Zeilenumschaltzeichen werden automatisch mit Escape-Zeichen markiert, wenn sie in einer von doppelten Anführungszeichen (") umschlossenen Zeichenfolge enthalten sind, z. B."Hello, World".Sie können Anführungszeichen in einer Zeichenfolge mit Anführungszeichen verwenden, indem Sie zwei in einer Zeile verwenden, z. B.
"Hello ""World""". -
DateTime— Ein Java-Datum in einem der folgenden Formate: ISO-8601yyyy-MM-ddyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ
Auto-cast Datentypen in Neptune OpenCypher Daten laden Dateien
Auto-cast Datentypen werden bereitgestellt, um Datentypen zu laden, die derzeit nicht von Neptune nativ unterstützt werden. Daten in solchen Spalten werden in unveränderter Form als Zeichenfolgen gespeichert, ohne sie anhand des beabsichtigten Formats zu verifizieren. Die folgenden Auto-Cast-Datentypen sind zulässig:
-
Char– EinChar-Feld. Als Zeichenfolge gespeichert. -
Date,LocalDateundLocalDateTime– Siehe Zeitliche Neo4j-Instantwertefür eine Beschreibung der Typen date,localdateundlocaldatetime. Die Werte werden in unveränderter Form als Zeichenfolgen ohne Validierung geladen. -
Duration– Siehe das Neo4j-Dauerformat. Die Werte werden in unveränderter Form als Zeichenfolgen ohne Validierung geladen. -
Punkt – Ein Punktfeld zum Speichern räumlicher Daten. Siehe Räumliche Instantwerte
. Die Werte werden in unveränderter Form als Zeichenfolgen ohne Validierung geladen.
Beispiel für das openCypher-Ladeformat
Das folgende Diagramm aus dem TinkerPop Modern Graph zeigt ein Beispiel für zwei Knoten und eine Beziehung:
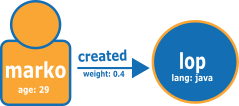
Die folgende Abbildung zeigt das Diagramm im normalen Neptune-openCypher-Ladeformat.
Knotendatei:
:ID,name:String,age:Int,lang:String,:LABEL v1,"marko",29,,person v2,"lop",,"java",software
Beziehungsdatei:
:ID,:START_ID,:END_ID,:TYPE,weight:Double e1,v1,v2,created,0.4
Alternativ könnten Sie ID-Bereiche und ID wie folgt als Eigenschaft verwenden:
Erste Knotendatei:
name:ID(person),age:Int,lang:String,:LABEL "marko",29,,person
Zweite Knotendatei:
name:ID(software),age:Int,lang:String,:LABEL "lop",,"java",software
Beziehungsdatei:
:ID,:START_ID(person),:END_ID(software),:TYPE,weight:Double e1,"marko","lop",created,0.4
