Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren auch keine neuen Nutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unter Was ist Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Schritt 2: Erstellen einer Schulungsdatenquelle
Nachdem Sie den banking.csv Datensatz an Ihren Amazon Simple Storage Service (Amazon S3) -Standort hochgeladen haben, verwenden Sie ihn, um eine Trainingsdatenquelle zu erstellen. Eine Datenquelle ist ein Amazon Machine Learning-Objekt (Amazon ML), das den Speicherort Ihrer Eingabedaten und wichtige Metadaten zu Ihren Eingabedaten enthält. Amazon ML verwendet die Datenquelle für Operationen wie das Training und die Evaluierung von ML-Modellen.
Geben Sie Folgendes an, um eine Datenquelle zu erstellen:
-
Der Amazon S3 S3-Speicherort Ihrer Daten und die Erlaubnis, auf die Daten zuzugreifen
-
Das Schema, das die Namen der Attribute in den Daten und den Typ der einzelnen Attribute (numerisch, Text, kategorisch oder Binary) enthält
-
Der Name des Attributs, das die Antwort enthält, deren Vorhersage Amazon ML lernen soll, das Zielattribut
Anmerkung
Die Datenquelle speichert Ihre Daten nicht, sondern verweist nur darauf. Vermeiden Sie es, die in Amazon S3 gespeicherten Dateien zu verschieben oder zu ändern. Wenn Sie sie verschieben oder ändern, kann Amazon ML nicht auf sie zugreifen, um ein ML-Modell zu erstellen, Bewertungen zu generieren oder Prognosen zu generieren.
Vorgehensweise zum Erstellen der Schulungsdatenquelle
Öffnen Sie die Amazon Machine Learning Learning-Konsole unter https://console.aws.amazon.com/machinelearning/
. -
Wählen Sie Erste Schritte.
Anmerkung
In diesem Tutorial wird davon ausgegangen, dass Sie Amazon ML zum ersten Mal verwenden. Wenn Sie Amazon ML schon einmal verwendet haben, können Sie die Option Create new... verwenden. Drop-down-Liste im Amazon ML-Dashboard, um eine neue Datenquelle zu erstellen.
-
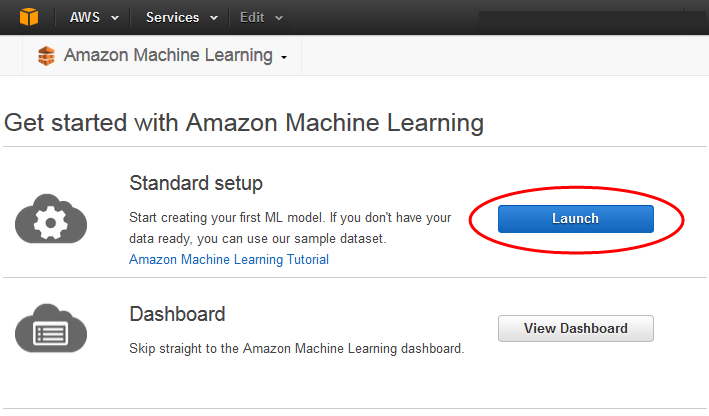
Wählen Sie auf der Seite Erste Schritte mit Amazon Machine Learning die Option Launch aus.
-
Stellen Sie auf der Seite Eingabedaten sicher, dass bei Where is your data located? (Wo befinden sich Ihre Daten?) die Option S3 ausgewählt ist.

-
Geben Sie bei S3 Location (S3-Speicherort) den vollständigen Pfad zur
banking.csv-Datei aus Schritt 1 "Vorbereitung Ihrer Daten" ein. Beispiel:your-bucket/banking.csv. Amazon ML stellt Ihrem Bucket-Namen für Sie s3://voran. -
Geben Sie bei Datenquellenname den Wert
Banking Data 1ein.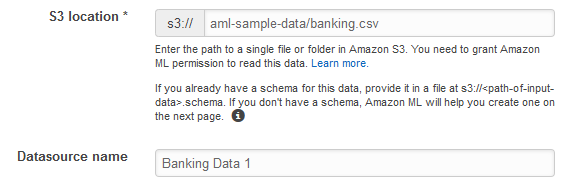
-
Wählen Sie Überprüfen.
-
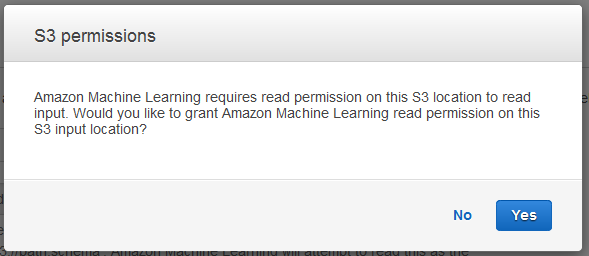
Klicken Sie im Dialogfeld S3 permissions (S3-Berechtigungen) auf Ja.
-
Wenn Amazon ML auf die Datendatei am S3-Standort zugreifen und sie lesen kann, wird eine Seite ähnlich der folgenden angezeigt. Überprüfen Sie die Eigenschaften und wählen Sie dann Weiter aus.

Als Nächstes erstellen Sie ein Schema. Ein Schema ist die Information, die Amazon ML benötigt, um die Eingabedaten für ein ML-Modell zu interpretieren, einschließlich der Attributnamen und der ihnen zugewiesenen Datentypen sowie der Namen spezieller Attribute. Es gibt zwei Möglichkeiten, Amazon ML ein Schema zur Verfügung zu stellen:
-
Geben Sie eine separate Schemadatei an, wenn Sie Ihre Amazon S3 S3-Daten hochladen.
-
Erlauben Sie Amazon ML, die Attributtypen abzuleiten und ein Schema für Sie zu erstellen.
In diesem Tutorial bitten wir Amazon ML, das Schema abzuleiten.
Weitere Informationen zum Erstellen einer separaten Schemadatei finden Sie unter Erstellen eines Datenschemas für Amazon ML.
Damit Amazon ML das Schema ableiten kann
-
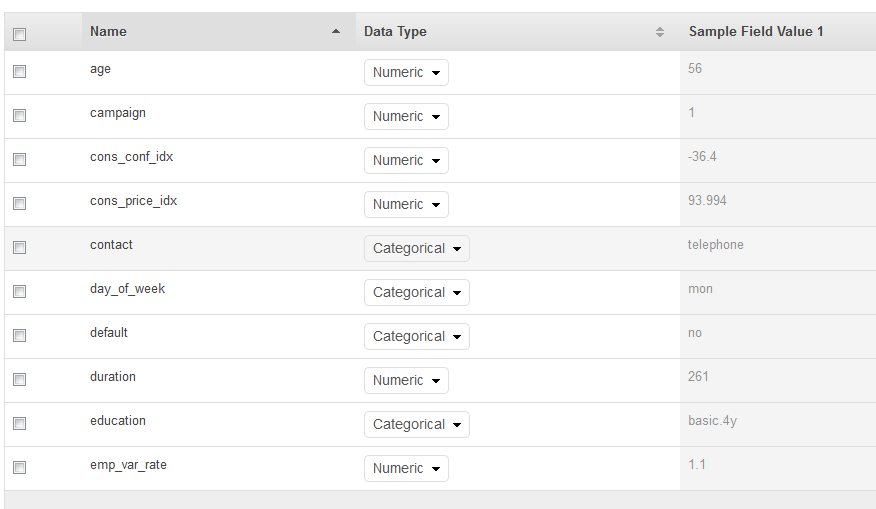
Auf der Schemaseite zeigt Ihnen Amazon ML das Schema, das es abgeleitet hat. Überprüfen Sie die Datentypen, die Amazon ML für die Attribute abgeleitet hat. Es ist wichtig, dass den Attributen der richtige Datentyp zugewiesen wird, damit Amazon ML die Daten korrekt aufnehmen kann und die korrekte Feature-Verarbeitung der Attribute ermöglicht wird.
-
Attribute, für die es nur zwei mögliche Status gibt wie "Ja" oder "Nein", sollten als Binary markiert werden.
-
Attribute, die Zahlen oder Zeichenfolgen zur Kennzeichnung einer Kategorie sind, sollten als Categorical markiert werden.
-
Attribute, die numerischen Mengen sind und bei denen die Reihenfolge wichtig ist, sollten als Numeric markiert werden.
-
Attribute, die Zeichenfolgen sind und als durch Leerzeichen getrennte Wörter gehandhabt werden sollen, sollten als Text markiert werden.
-
-
In diesem Tutorial hat Amazon ML die Datentypen für alle Attribute korrekt identifiziert. Wählen Sie also Weiter.
Wählen Sie als Nächstes ein Zielattribut aus.
Denken Sie daran, dass das Zielattribut das Attribut ist, dessen Voraussage das ML-Modell lernen soll. Attribut y gibt an, ob eine Person in der Vergangenheit eine Kampagne abonniert hat: 1 (Ja) oder 0 (Nein).
Anmerkung
Wählen Sie ein Zielattribut nur aus, wenn Sie die Datenquelle für die Schulung und Evaluierung von ML-Modellen verwenden werden.
Vorgehensweise zum Auswählen von y als Zielattribut
-
Klicken Sie unten rechts in der Tabelle auf den einzelnen Pfeil, um zur letzten Seite der Tabelle zu gelangen, auf der das Attribut
yangezeigt wird.
-
Wählen Sie in der Spalte Ziel den Wert
yaus.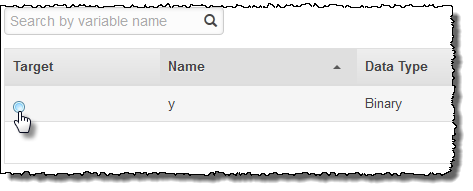
Amazon ML bestätigt, dass y als Ihr Ziel ausgewählt ist.
-
Klicken Sie auf Weiter.
-
Vergewissern Sie sich, dass auf der Seite Zeilen-ID bei Does your data contain an identifier? (Enthalten Ihre Daten eine ID?) die Standardeinstellung Nein ausgewählt ist.
-
Klicken Sie auf Review und dann auf Continue.
Nun, da Sie eine Schulungsdatenquelle haben, können Sie Ihr Modell erstellen.
