Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
# Einen Workflow erstellen
Bevor Sie beginnen, stellen Sie sicher, dass Sie der Rolle die erforderlichen Datenberechtigungen und Datenspeicherberechtigungen erteilt haben`LakeFormationWorkflowRole`. Auf diese Weise kann der Workflow Metadatentabellen im Datenkatalog erstellen und Daten an Zielorte in Amazon S3 schreiben. Weitere Informationen erhalten Sie unter [(Optional) Erstellen Sie eine IAM-Rolle für Workflows](initial-lf-config.md#iam-create-blueprint-role) und [Überblick über die Genehmigungen für Lake Formation](lf-permissions-overview.md).
**Anmerkung**
Lake Formation verwendet `GetTemplateInstance``GetTemplateInstances`, und `InstantiateTemplate` Operationen, um Workflows aus Blueprints zu erstellen. Diese Operationen sind nicht öffentlich verfügbar und werden nur intern zur Erstellung von Ressourcen in Ihrem Namen verwendet. Sie erhalten CloudTrail Ereignisse für die Erstellung von Workflows.
**Um einen Workflow aus einem Blueprint zu erstellen**
1. Öffnen Sie die AWS Lake Formation Konsole unter. [https://console.aws.amazon.com/lakeformation/](https://console.aws.amazon.com/lakeformation/) Melden Sie sich als Data Lake-Administrator oder als Benutzer mit Data Engineer-Rechten an. Weitere Informationen finden Sie unter [Referenz zu Personas und IAM-Berechtigungen in Lake Formation](permissions-reference.md).
1. Wählen Sie im Navigationsbereich **Blueprints** und dann **Blueprint verwenden** aus.
1. Wählen Sie auf der Seite **Blueprint verwenden eine** Kachel aus, um den Blueprint-Typ auszuwählen.
1. Geben **Sie unter Importquelle** die Datenquelle an.
Wenn Sie aus einer JDBC-Quelle importieren, geben Sie Folgendes an:
+ ****Datenbankverbindung**** — Wählen Sie eine Verbindung aus der Liste aus. Erstellen Sie zusätzliche Verbindungen mithilfe der AWS Glue Konsole. Der JDBC-Benutzername und das JDBC-Kennwort in der Verbindung bestimmen, auf welche Datenbankobjekte der Workflow Zugriff hat.
+ ****Quelldatenpfad**** — Geben Sie {{}} je nach {{}} {{}} Datenbankprodukt{{}}//oder/{{}}ein. Oracle Database und MySQL unterstützen kein Schema im Pfad. Sie können das Prozentzeichen (%) durch {{}} oder {{}} ersetzen. Geben Sie beispielsweise für eine Oracle-Datenbank mit einem Systembezeichner (SID) von ein`orcl`, `orcl/%` um alle Tabellen zu importieren, auf die der in der Verbindung angegebene Benutzer Zugriff hat.
**Wichtig**
In diesem Feld wird zwischen Groß- und Kleinschreibung unterschieden. Der Workflow schlägt fehl, wenn die Groß- und Kleinschreibung für eine der Komponenten nicht übereinstimmt.
Wenn Sie eine MySQL-Datenbank angeben, verwendet AWS Glue ETL standardmäßig den Mysql5-JDBC-Treiber, sodass My nicht nativ unterstützt SQL8 wird. Sie können das ETL-Jobskript bearbeiten, um einen `customJdbcDriverS3Path` Parameter zu verwenden, wie in [JDBC connectionType Values](https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-connect.html#aws-glue-programming-etl-connect-jdbc) im *AWS Glue Developer Guide* beschrieben, um einen anderen JDBC-Treiber zu verwenden, der My unterstützt. SQL8
Wenn Sie aus einer Protokolldatei importieren, stellen Sie sicher, dass die Rolle, die Sie für den Workflow angeben (die „Workflow-Rolle“), über die erforderlichen IAM-Berechtigungen für den Zugriff auf die Datenquelle verfügt. Um beispielsweise AWS CloudTrail Protokolle zu importieren, muss der Benutzer über die `cloudtrail:LookupEvents` Berechtigungen `cloudtrail:DescribeTrails` und verfügen, um die Liste der CloudTrail Protokolle bei der Erstellung des Workflows zu sehen, und die Workflow-Rolle muss über Berechtigungen für den CloudTrail Standort in Amazon S3 verfügen.
1. Führen Sie eine der folgenden Aktionen aus:
+ Identifizieren Sie für den **Blueprint-Typ Datenbank-Snapshot** optional eine Teilmenge der zu importierenden Daten, indem Sie ein oder mehrere Ausschlussmuster angeben. Bei diesen Ausschlussmustern handelt es sich um Muster im UNIX-Stil`glob`. Sie werden als Eigenschaft der Tabellen gespeichert, die durch den Workflow erstellt werden.
Einzelheiten zu den verfügbaren Ausschlussmustern finden Sie unter [Einschluss- und Ausschlussmuster](https://docs.aws.amazon.com/glue/latest/dg/define-crawler.html#crawler-data-stores-exclude) im *AWS Glue Entwicklerhandbuch*.
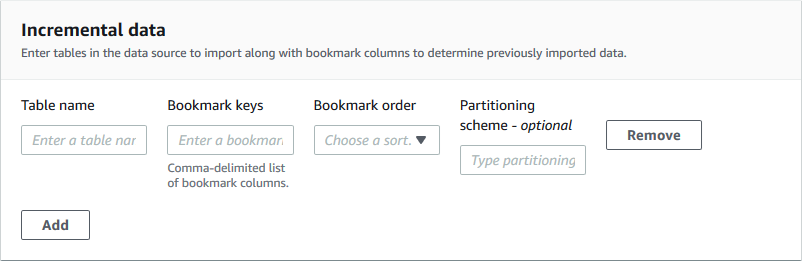
+ Geben Sie für den Blueprint-Typ **Inkrementelle Datenbank** die folgenden Felder an. Fügen Sie für jede zu importierende Tabelle eine Zeile hinzu.
**Tabellenname**
Zu importierende Tabelle. Muss ausschließlich in Kleinbuchstaben geschrieben werden.
**Schlüssel als Lesezeichen speichern**
Durch Kommas getrennte Liste von Spaltennamen, die die Lesezeichenschlüssel definieren. Wenn das Feld leer ist, wird der Primärschlüssel verwendet, um neue Daten zu ermitteln. Die Groß- und Kleinschreibung für jede Spalte muss mit der in der Datenquelle definierten Groß- und Kleinschreibung übereinstimmen.
Der Primärschlüssel gilt nur dann als Standardlesezeichenschlüssel, wenn er sequenziell erhöht oder verringert wird (ohne Lücken). Wenn Sie den Primärschlüssel als Lesezeichenschlüssel verwenden möchten und dieser Lücken aufweist, müssen Sie die Primärschlüsselspalte als Lesezeichenschlüssel benennen.
**Reihenfolge der Lesezeichen**
Wenn Sie **Aufsteigend** wählen, werden Zeilen mit Werten, die größer sind als die mit den Lesezeichen markierten Werte, als neue Zeilen identifiziert. Wenn Sie **Absteigend** wählen, werden Zeilen, deren Werte kleiner als die mit der Textmarke markierten Werte sind, als neue Zeilen identifiziert.
**Partitionierungsschema**
(Optional) Liste der Partitionierungsschlüsselspalten, getrennt durch Schrägstriche (/). ` year/month/day`Beispiel:.
Weitere Informationen finden Sie unter [Verfolgen verarbeiteter Daten mithilfe von Job-Lesezeichen](https://docs.aws.amazon.com/glue/latest/dg/monitor-continuations.html) im *AWS Glue Entwicklerhandbuch*.
1. Geben Sie unter **Importziel** die Zieldatenbank, den Amazon S3 S3-Zielort und das Datenformat an.
Stellen Sie sicher, dass die Workflow-Rolle über die erforderlichen Lake Formation Formation-Berechtigungen für die Datenbank und den Amazon S3 S3-Zielstandort verfügt.
**Anmerkung**
Derzeit unterstützen Blueprints die Verschlüsselung von Daten am Ziel nicht.
1. Wählen Sie eine Importhäufigkeit.
Sie können einen `cron` Ausdruck mit der Option **Benutzerdefiniert** angeben.
1. Unter **Importoptionen**:
1. Geben Sie einen Workflow-Namen ein.
1. Wählen Sie unter Rolle die Rolle aus`LakeFormationWorkflowRole`, in der Sie sie erstellt haben[(Optional) Erstellen Sie eine IAM-Rolle für Workflows](initial-lf-config.md#iam-create-blueprint-role).
1. Geben Sie optional ein Tabellenpräfix an. Das Präfix wird den Namen der Datenkatalogtabellen vorangestellt, die der Workflow erstellt.
1. Wählen Sie **Erstellen** und warten Sie, bis die Konsole meldet, dass der Workflow erfolgreich erstellt wurde.
**Tipp**
Haben Sie die folgende Fehlermeldung erhalten?
`User: arn:aws:iam::{{}}:user/{{}} is not authorized to perform: iam:PassRole on resource:arn:aws:iam::{{}}:role/{{}}...`
Falls ja, überprüfen Sie, ob Sie in allen Policen die AWS Kontonummer durch eine gültige ersetzt {{}} haben.
**Weitere Informationen finden Sie auch unter:**
[Baupläne und Arbeitsabläufe in Lake Formation](workflows-about.md)