Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfiguration des Abrufs der Wissensdatenbank
Wenn Sie KI-Agenten für Orchestrierung verwenden, können Sie Retrieve-Tools konfigurieren, mit denen Ihr KI-Agent Wissensdatenbanken durchsuchen und relevante Informationen zurückgeben kann, um Benutzerfragen zu beantworten.
Jedes Retrieve-Tool fragt eine einzelne Wissensdatenbank ab. Durch die Konfiguration mehrerer Abruf-Tools ermöglichen Sie es Ihrem KI-Agenten, mehrere Wissensdatenbanken gleichzeitig abzufragen oder anhand der Frage des Benutzers intelligent auszuwählen, welche Datenbank durchsucht werden soll. Well-defined Werkzeugbeschreibungen und Anweisungen in der Befehlszeile ermöglichen es dem Modell, Abfragen automatisch an die relevanteste Wissensdatenbank weiterzuleiten.
Sie können auf zwei Ebenen steuern, wie Ihr KI-Agent Inhalte abfragt:
-
Wissensdatenbank-Ebene: Konfigurieren Sie mehrere Abruf-Tools, um verschiedene Wissensdatenbanken abzufragen. Verwenden Sie diesen Ansatz, wenn Ihre Inhalte in mehreren Wissensdatenbanken organisiert sind.
-
Inhaltsebene: Verwenden Sie die Inhaltssegmentierung, um nur bestimmte Inhalte innerhalb einer einzigen Wissensdatenbank abzufragen.
Inhalt
So konfigurieren Sie Ihren Orchestrierungsagenten so, dass er mehrere Wissensdatenbanken abfragt
Sie können mehrere Retrieve-Tools konfigurieren, um verschiedene Wissensdatenbanken abzufragen. Abhängig von Ihrem Anwendungsfall können Sie entweder:
Alle Wissensdatenbanken gleichzeitig abfragen (parallel Aufruf)
Fragen Sie spezifische Wissensdatenbanken auf der Grundlage des Kontextes der Anfrage ab (bedingter Aufruf)
Einrichtung mehrerer Retrieve-Tools
Beide Konfigurationen erfordern dieselbe Ersteinrichtung. Führen Sie zuerst diese Schritte aus und folgen Sie dann den Anweisungen für Ihren speziellen Anwendungsfall.
-
In der AWS-Konsole können Sie zusätzliche Wissensdatenbanken hinzufügen, indem Sie Integration hinzufügen wählen und der Anleitung folgen. In diesem Beispiel haben wir demo-byobkb als zusätzliche Wissensdatenbank hinzugefügt.

-
Erstellen Sie im AI Agent Designer einen neuen Orchestration AI-Agenten und bearbeiten Sie das Standard-Retrieve-Tool
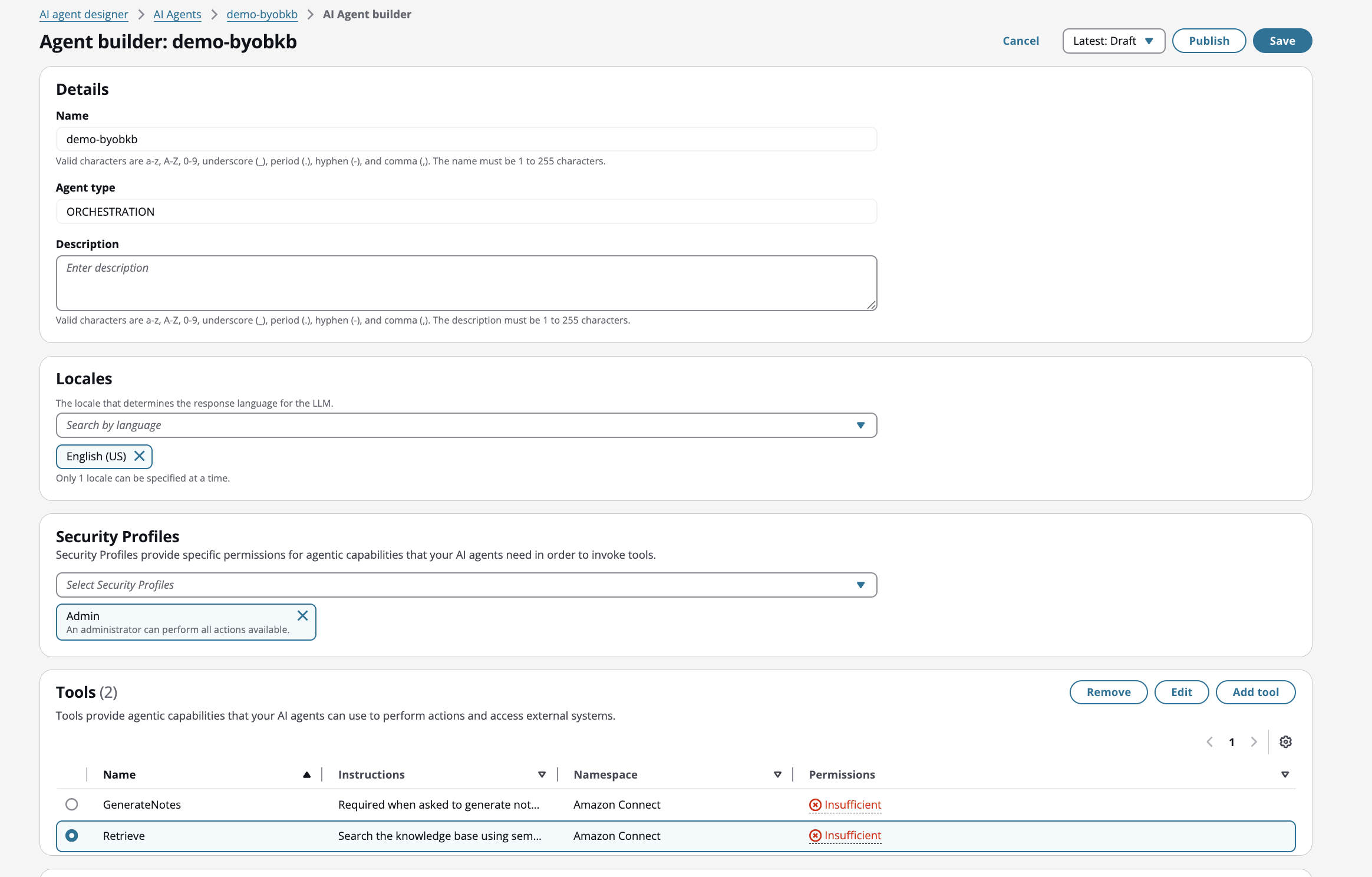
-
Verknüpfen Sie die vorhandene Wissensdatenbank mit dem Retrieve-Tool. Der AI-Agent verwendet diese Wissensdatenbank standardmäßig
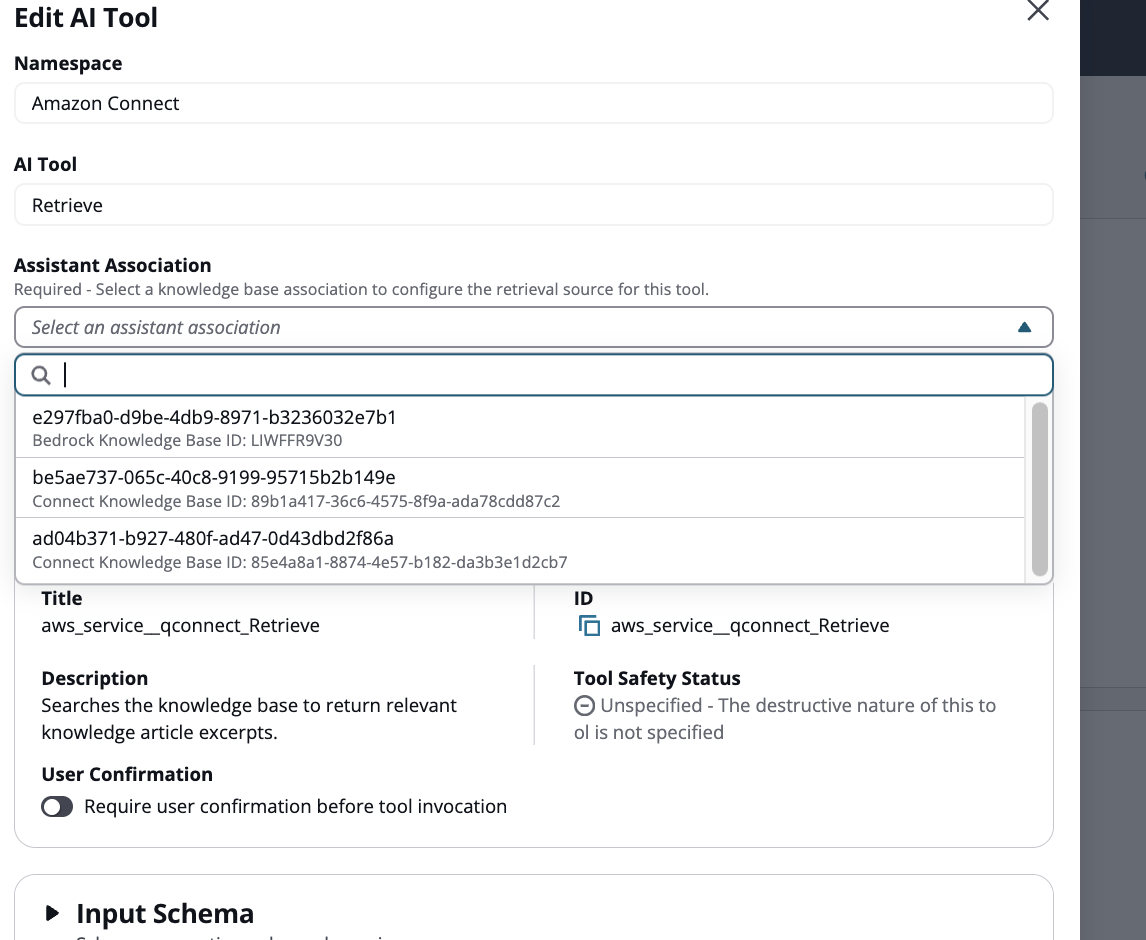
-
Fügen Sie ein zusätzliches Tool hinzu, wählen Sie Amazon Connect als Namespace und wählen Sie den Typ des AI-Tools abrufen
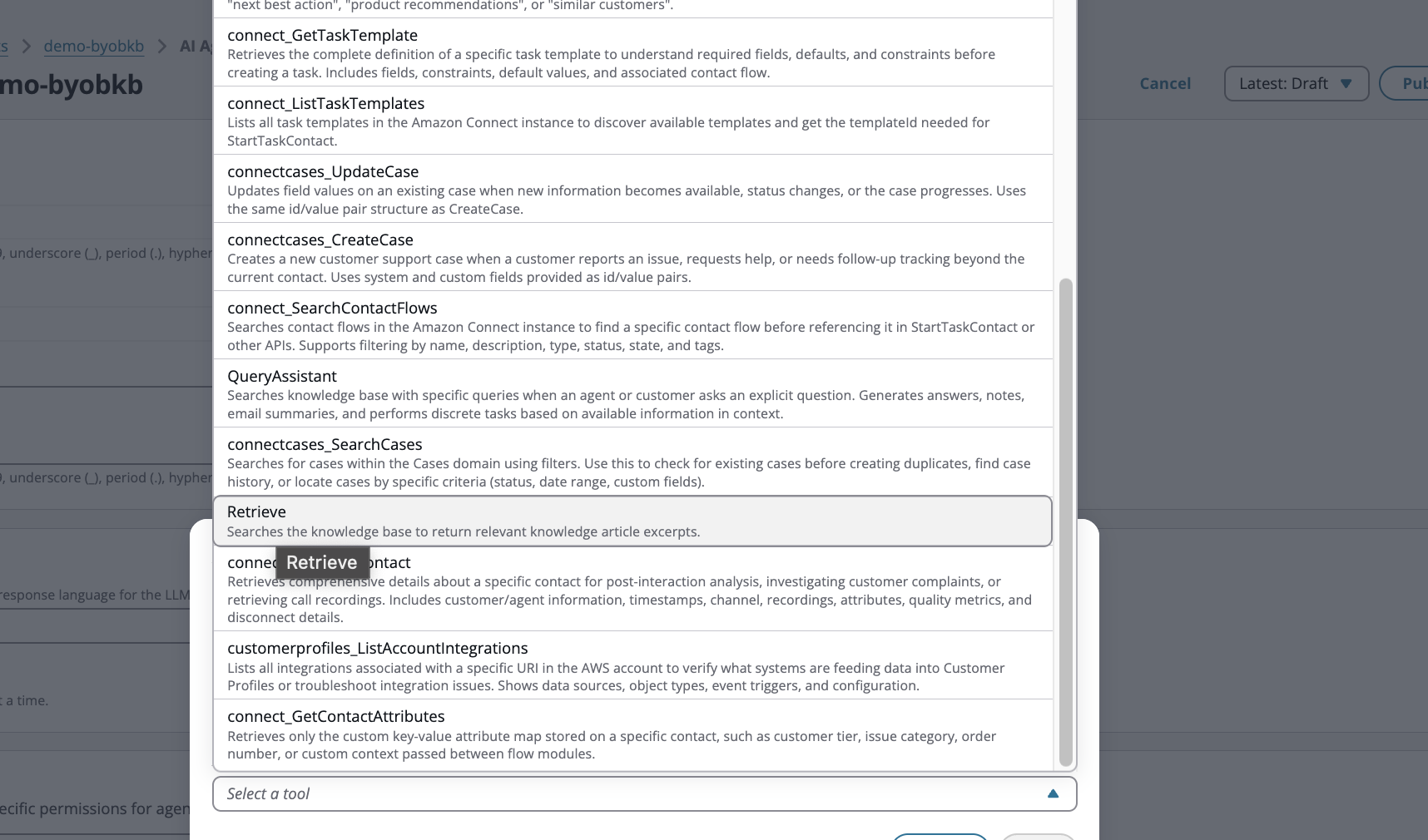
-
Wählen Sie nun die zusätzliche Wissensdatenbank aus, die Sie über die Standard-Wissensdatenbank hinaus verknüpfen möchten
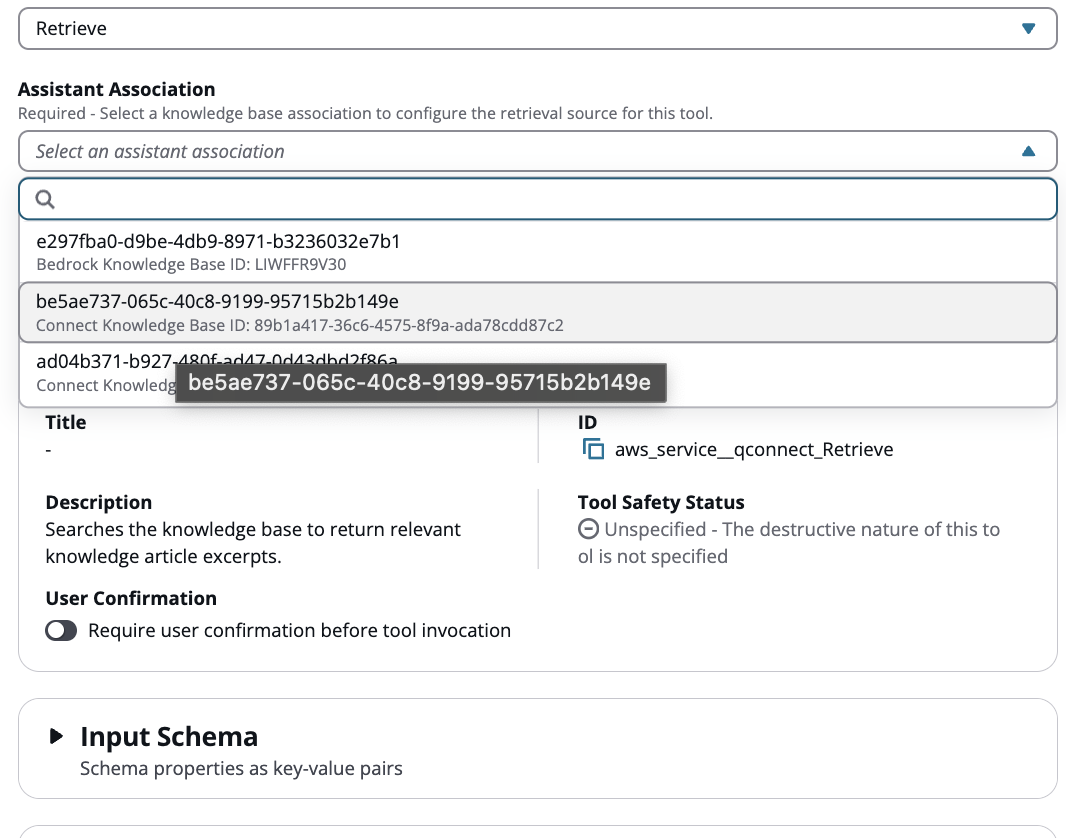
-
Geben Sie jedem weiteren Abruf-Werkzeug einen Namen, der mit „Retrieve“ beginnt (z. B. Retrieve2, Retrieve3,,). RetrieveProducts RetrievePolicies
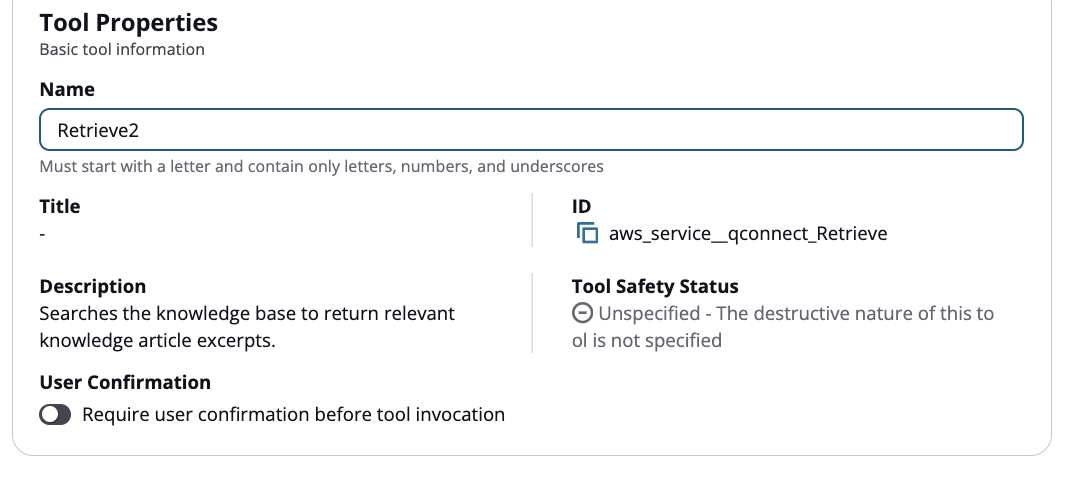
-
Als Nächstes konfigurieren Sie die Anweisungen und Beispiele für das Tool. Die Konfiguration hängt von Ihrem Anwendungsfall ab. In den folgenden Abschnitten werden zwei Szenarien behandelt: das gleichzeitige Abfragen aller Wissensdatenbanken und das selektive Abfragen von Wissensdatenbanken.
Gleichzeitiges Abfragen aller Wissensdatenbanken
Verwenden Sie diese Konfiguration, wenn der Agent alle Wissensdatenbanken gleichzeitig nach jeder Abfrage durchsuchen soll.
Anweisungen zum Konfigurieren des Tools
-
Füllen Sie die Werkzeuganweisungen aus, indem Sie die Anweisungen und Beispiele aus dem Standardtool „Abrufen“ kopieren.
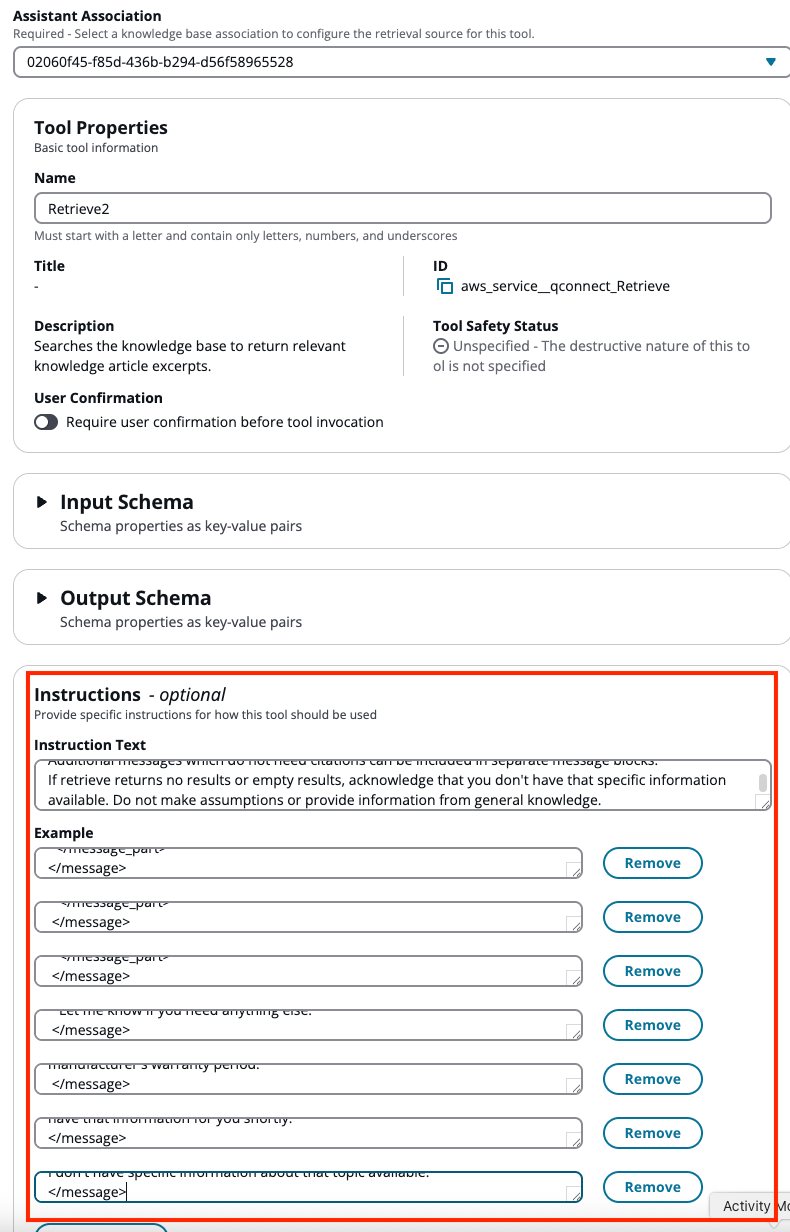
-
Wählen Sie die Schaltfläche Hinzufügen, um das neue Tool „Abrufen“ zu erstellen. Ihre Werkzeugliste sollte jetzt das neue Retrieve-Tool enthalten.
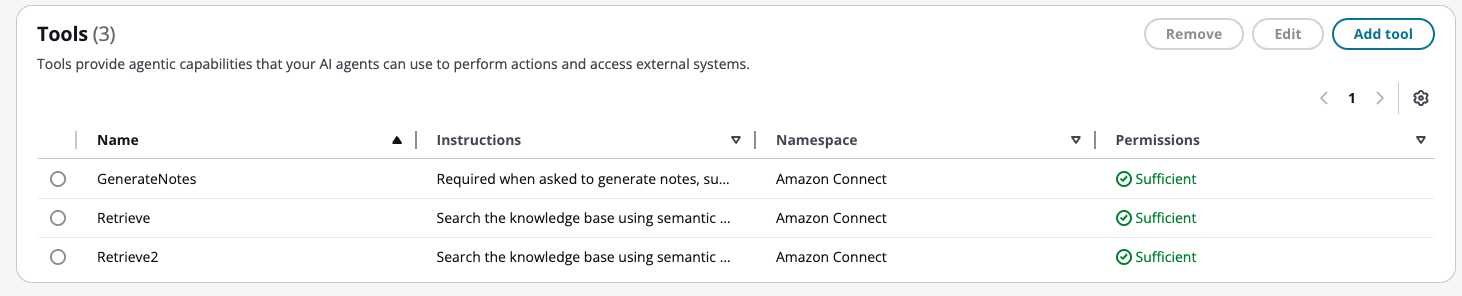
Sie haben jetzt ein zweites Retrieve-Tool. Um alle Abruf-Tools zusammen verwenden zu können, müssen Sie die Eingabeaufforderung mit Anweisungen ändern, um sie gleichzeitig aufzurufen. Ohne diese Änderung wird nur ein Retrieve-Tool verwendet.
Aktualisierung Ihrer Eingabeaufforderung für parallel Aufruf
-
Ändern Sie die Aufforderung, um sie anzuweisen, mehrere Retrieve-Tools zu verwenden. Standard-Orchestrierungsaufforderungen können nicht direkt bearbeitet werden, sodass Sie eine Kopie mit Ihren Änderungen erstellen müssen.
Erstellen Sie eine neue Aufforderung, indem Sie die Standard-Orchestrierungsaufforderung kopieren, die Ihrem Anwendungsfall entspricht. In diesem Beispiel kopieren wir aus der AgentAssistanceOrchestration Eingabeaufforderung.
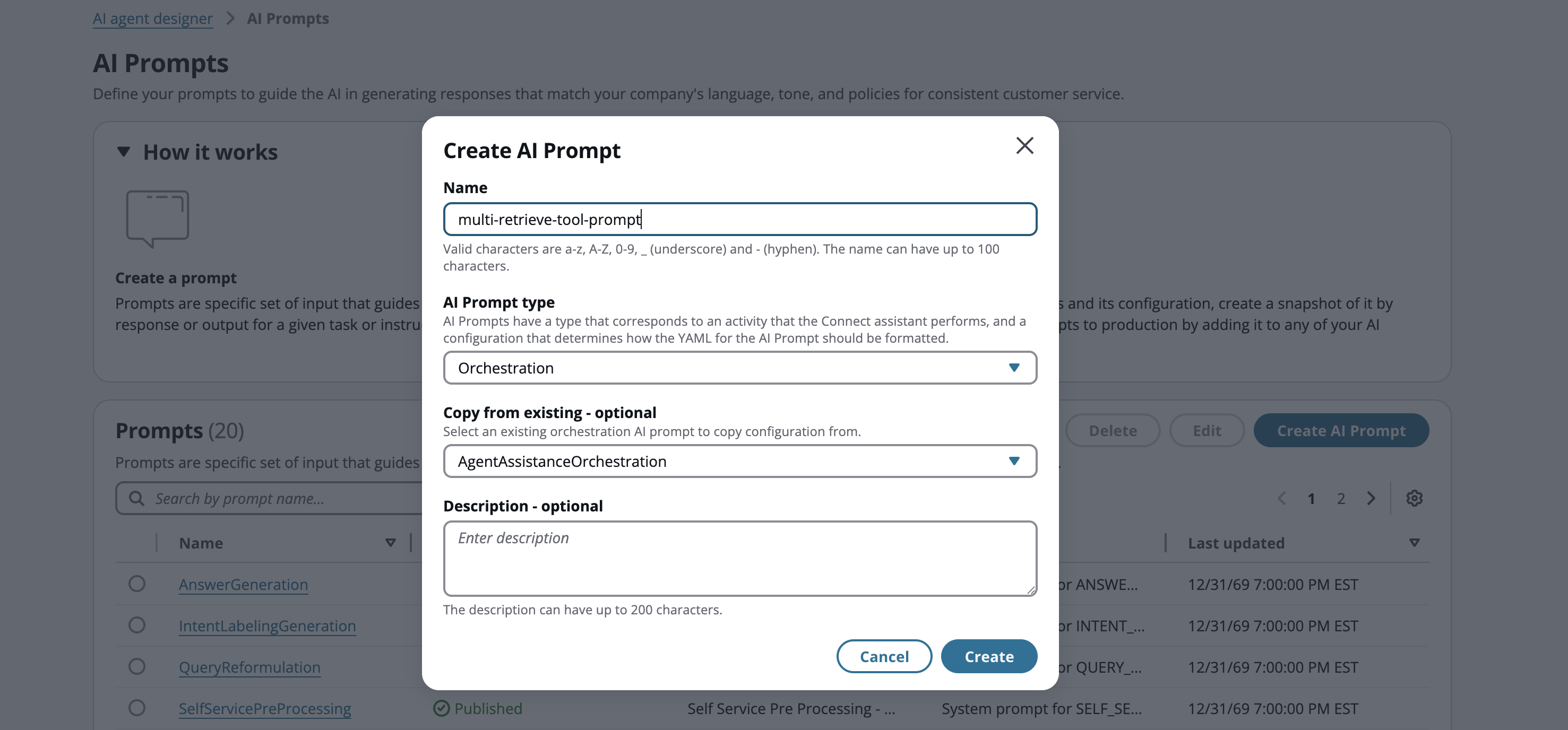
-
Wählen Sie die Schaltfläche Erstellen und Sie werden zu einer Seite weitergeleitet, auf der Sie die Aufforderung ändern können.
-
Ändern Sie Ihre Eingabeaufforderung basierend auf Ihrem Orchestrierungstyp:
-
Für Orchestrierungsaufforderungen zur Agentenunterstützung:
Suchen Sie den Abschnitt mit den nummerierten Regeln in Ihrer Orchestrierungsaufforderung. Dieser Abschnitt beginnt mit einer Zeile, die der folgenden ähnelt:
Your goal is to resolve the customer's issue while also being responsive. While responding, follow these important rules:Fügen Sie Folgendes als letzte nummerierte Regel in diesem Abschnitt hinzu:
CRITICAL - Multiple Retrieve Tools: When multiple Retrieve-type tools are available ([Retrieve], [Retrieve2]), you MUST invoke ALL of them simultaneously for any search request. Never use only one Retrieve tool when multiple are available-always select and invoke them together to ensure comprehensive results from all knowledge sources. -
Für Self-Service Orchestrierungsaufforderungen:
Suchen Sie den Abschnitt
core_behavior. Fügen Sie in diesem Abschnitt die folgende Regel hinzu:CRITICAL - Multiple Retrieve Tools: When multiple Retrieve-type tools are available ([Retrieve], [Retrieve2]), you MUST invoke ALL of them simultaneously for any search request. Never use only one Retrieve tool when multiple are available—always invoke them together to ensure comprehensive results from all knowledge sources.
Anmerkung
Ersetzen Sie die Platzhalter in Klammern durch Ihre tatsächlichen Werkzeugnamen.
-
Selektives Abfragen von Wissensdatenbanken
Verwenden Sie diese Konfiguration, wenn Sie möchten, dass der Agent die passende Wissensdatenbank basierend auf der Art der Frage oder des Kontextes auswählt.
Tool-Anweisungen für jede Wissensdatenbank konfigurieren
Im Gegensatz zum parallel Aufruf benötigt jedes Retrieve-Tool eigene Anweisungen, die beschreiben, wann es verwendet werden sollte. Dazu gehört auch das standardmäßige Retrieve-Tool. Sie müssen dessen Anweisungen aktualisieren, um es von den zusätzlichen Retrieve-Tools zu unterscheiden. Verwenden Sie aussagekräftige Namen, die den Inhalt der einzelnen Wissensdatenbanken widerspiegeln (z. B., RetrievePolicies) RetrieveProducts, damit das Modell das richtige Tool auswählen kann.
-
Schreiben Sie für jedes Retrieve-Tool, einschließlich des Standardwerkzeugs, spezifische Anweisungen, die den Inhalt der zugehörigen Wissensdatenbank beschreiben und angeben, wann sie verwendet werden soll.
-
Wählen Sie die Schaltfläche Hinzufügen, um das neue Tool „Abrufen“ zu erstellen. Ihre Werkzeugliste sollte jetzt das neue Retrieve-Tool enthalten.
Sie haben jetzt ein zweites Retrieve-Tool. Damit der Agent das passende Tool je nach Kontext auswählt, müssen Sie die Eingabeaufforderung mit Anweisungen ändern, wann die einzelnen Tools verwendet werden sollen.
Aktualisierung Ihrer Aufforderung für einen bedingten Aufruf
-
Ändern Sie die Aufforderung, um sie anzuweisen, je nach Kontext das passende Retrieve-Tool auszuwählen. Die standardmäßigen Orchestrierungsaufforderungen können nicht direkt bearbeitet werden, sodass Sie eine Kopie mit Ihren Änderungen erstellen müssen.
Erstellen Sie eine neue Aufforderung, indem Sie die Standard-Orchestrierungsaufforderung kopieren, die Ihrem Anwendungsfall entspricht. In diesem Beispiel kopieren wir aus der AgentAssistanceOrchestration Eingabeaufforderung.
-
Wählen Sie die Schaltfläche Erstellen und Sie werden zu einer Seite weitergeleitet, auf der Sie die Aufforderung ändern können.
-
Ändern Sie Ihre Eingabeaufforderung basierend auf Ihrem Orchestrierungstyp:
-
Für Orchestrierungsaufforderungen zur Agentenunterstützung:
Suchen Sie den Abschnitt mit den nummerierten Regeln in Ihrer Orchestrierungsaufforderung. Dieser Abschnitt beginnt mit einer Zeile, die der folgenden ähnelt:
Your goal is to resolve the customer's issue while also being responsive. While responding, follow these important rules:Fügen Sie Folgendes als letzte nummerierte Regel in diesem Abschnitt hinzu:
CRITICAL - Retrieve Tool Selection: You have multiple Retrieve tools. Each queries a different knowledge base. You MUST select only ONE tool per question based on the topic. - [Retrieve] contains [description]. - [Retrieve2] contains [description]. Evaluate the question, match it to the most relevant tool, and invoke only that tool. -
Für Self-Service Orchestrierungsaufforderungen:
Suchen Sie den Abschnitt
core_behavior. Fügen Sie in diesem Abschnitt die folgende Regel hinzu:CRITICAL - Retrieve Tool Selection: You have multiple Retrieve tools. Each queries a different knowledge base. You MUST select only ONE tool per question based on the topic. - [Retrieve] contains [description]. - [Retrieve2] contains [description]. Evaluate the question, match it to the most relevant tool, and invoke only that tool.
Anmerkung
Ersetzen Sie die Platzhalter in Klammern durch Ihre tatsächlichen Toolnamen, Beschreibungen und Beispielfragen.
Bewährte Methoden für eine genaue Werkzeugauswahl
Ob das Modell das richtige Retrieve-Werkzeug auswählen kann, hängt von mehreren Faktoren ab: Werkzeugname, Werkzeugbeschreibung, Werkzeugbeispielen und Anweisungen in der Befehlszeile. Befolgen Sie diese Richtlinien:
-
Verwenden Sie aussagekräftige Werkzeugnamen: Namen wie RetrieveProducts oder RetrievePolicies helfen dem Modell, den Zweck der einzelnen Werkzeuge zu verstehen.
-
Seien Sie bei den Beschreibungen spezifisch: Vermeiden Sie vage Beschreibungen wie „allgemeine Informationen“. Führen Sie die spezifischen Themen, Dokumenttypen oder Fragenkategorien auf, mit denen sich jede Wissensdatenbank befasst.
-
Fügen Sie Beispielfragen hinzu: Nehmen Sie Beispielfragen in die Anweisungen des Tools auf, damit das Modell die beabsichtigten Anwendungsfälle besser versteht.
-
Überschneidungen vermeiden: Stellen Sie sicher, dass sich Werkzeugnamen, Beschreibungen und Beispiele gegenseitig ausschließen. Überlappende Inhalte können dazu führen, dass das Modell inkonsistente Entscheidungen trifft.
-
Passen Sie die Terminologie an die Benutzersprache an: Verwenden Sie dieselben Wörter und Ausdrücke, die Ihre Benutzer normalerweise verwenden, nicht nur interne oder technische Terminologie.
Ihr Anwendungsfall erfordert möglicherweise zusätzliche schnelle Änderungen, die über die hier aufgeführten Beispiele hinausgehen.
-
Segmentierung von Inhalten
Mit der Inhaltssegmentierung können Sie den Inhalt Ihrer Wissensdatenbank taggen und die Abrufergebnisse anhand dieser Tags filtern. Wenn Ihr LLM-Tool die Wissensdatenbank abfragt, kann es Tags angeben, um nur Inhalte abzurufen, die diesen Tags entsprechen, sodass gezielte Antworten aus bestimmten Inhaltsuntergruppen möglich sind.
Anmerkung
Die Inhaltssegmentierung ist für den Webcrawler-Datenquellentyp nicht verfügbar.
Taggen von Inhalten nach Datenquellentyp
Das Verfahren zum Taggen von Inhalten hängt von Ihrem Datenquellentyp ab.
S3, Salesforce SharePoint, Zendesk und ServiceNow
Nachdem Sie Ihre Wissensdatenbank erstellt haben, können Sie Tags zur Segmentierung auf einzelne Inhaltselemente anwenden. Tags werden auf Inhaltsebene angewendet, was bedeutet, dass jeder Inhalt einzeln markiert werden muss.
Verwenden Sie die Amazon Connect TagResource Connect-API, um Inhalte zu taggen. Mit dieser API können Sie programmgesteuert Tags zu Inhalten der Wissensdatenbank hinzufügen, die dann für die Filterung der Inhaltssegmentierung beim Abruf verwendet werden können.
Beispiele für das Taggen von Inhalten finden Sie im Workshop zur Inhaltssegmentierung.
Verwenden von Tags im Retrieve-Tool
Sobald Ihr Inhalt markiert ist, können Sie die Abrufergebnisse filtern, indem Sie Tag-Filter in der Konfiguration des Tools „Abrufen“ angeben.
-
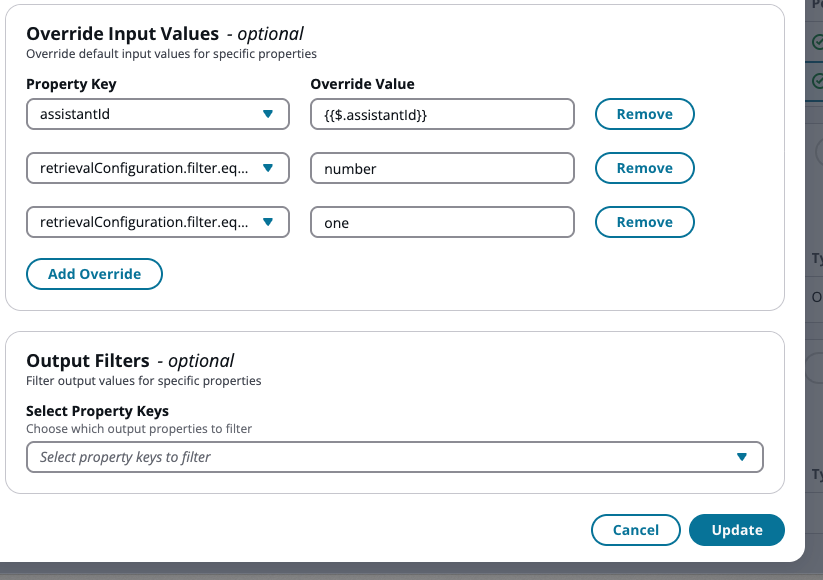
Navigieren Sie in der Konfiguration des Tools „Abrufen“ zum Abschnitt „Eingabewerte überschreiben“.
-
Fügen Sie Schlüssel-Wert-Paare hinzu, um Ihren Tag-Filter zu definieren. Sie benötigen zwei Überschreibungen, um nach einem einzigen Tag zu filtern. In diesem Beispiel verwenden wir
equalsals Filteroperator:-
Stellen Sie den Eigenschaftsschlüssel auf
retrievalConfiguration.filter.equals.keymit dem Wert als Tag-Namen ein (z. B.number).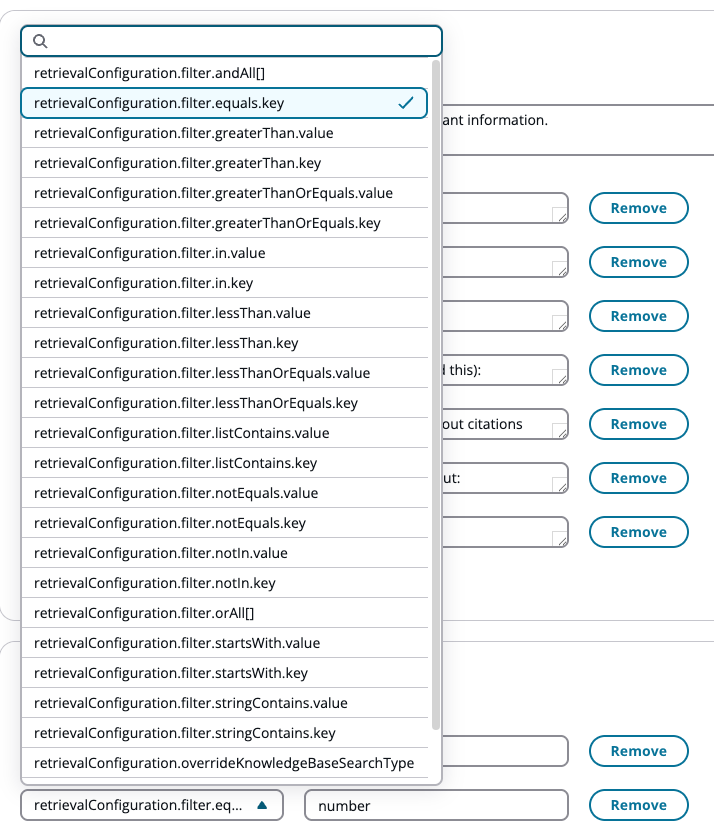
-
Stellen Sie den Eigenschaftsschlüssel auf
retrievalConfiguration.filter.equals.valuemit dem Wert als Tag-Wert ein (z. B.one).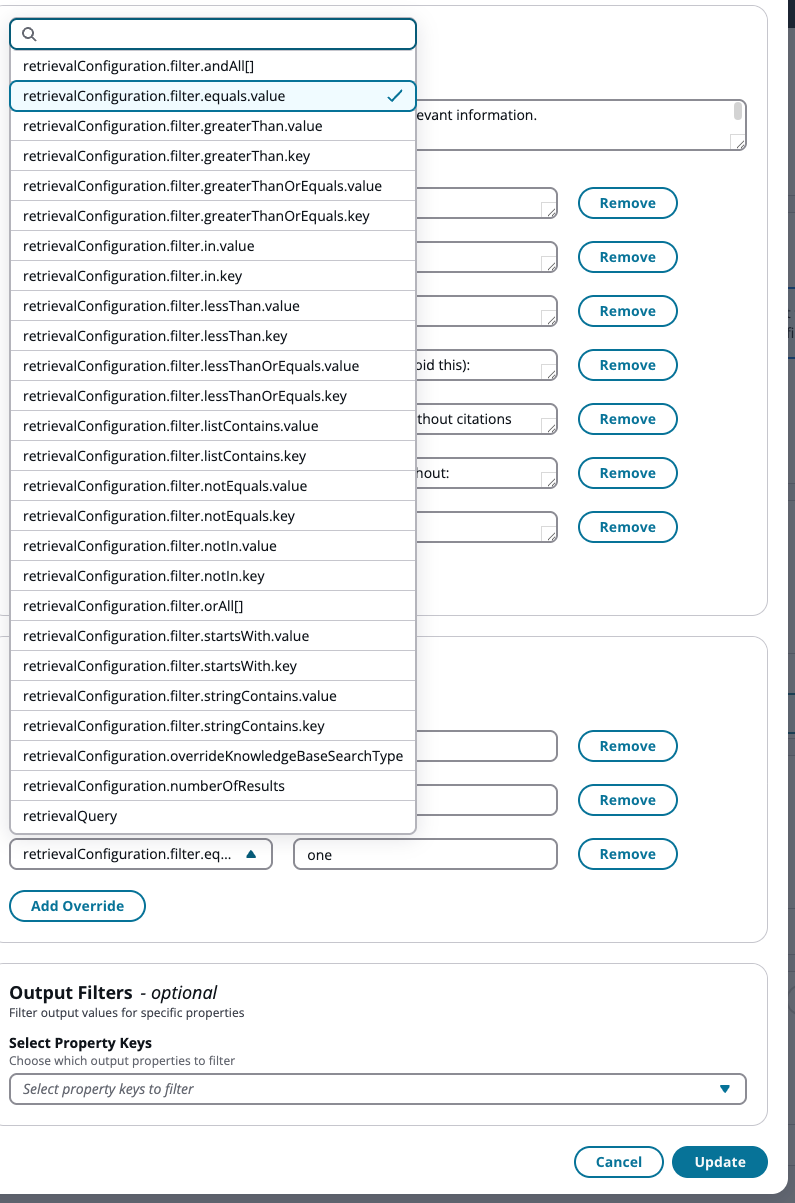
-
Sie können jede Filterkonfiguration verwenden, die mit beginnt, retrievalConfiguration.filter um Ihre Tag-Filterkriterien zu definieren.
Bedrock-Wissensdatenbank
Bei Bedrock Knowledge Base-Datenquellen werden Inhalte nicht als Amazon Connect Connect-Ressourcen gespeichert, sodass das Taggen über die TagResource API nicht verfügbar ist. Stattdessen müssen Sie Metadatenfelder direkt in Ihren Bedrock-Wissensdatenbanken definieren.
Informationen zu S3-Datenquellen finden Sie im Abschnitt Metadatenfelder für Dokumente im Amazon Bedrock S3-Datenquellen-Connector-Benutzerhandbuch.
Informationen zu anderen Datenquellentypen finden Sie unter Benutzerdefinierte Transformation während der Aufnahme in der Amazon Bedrock-Dokumentation.
Verwenden von Metadatenfeldern im Retrieve-Tool
Die Wissensdatenbanken von Bedrock stellen automatisch integrierte Metadatenfelder für alle Dateien bereit. Sie können diese Felder verwenden, um Abrufergebnisse im Retrieve-Tool zu filtern, indem Sie dieselbe Konfigurationsmethode verwenden, die im obigen Beispiel gezeigt wurde.
Um nur Ergebnisse aus einer bestimmten Datenquelle in Ihrer Bedrock-Wissensdatenbank abzurufen, konfigurieren Sie die Filterüberschreibungen wie folgt:
-
retrievalConfiguration.filter.equals.key=x-amz-bedrock-kb-data-source-id -
retrievalConfiguration.filter.equals.value=[your-data-source-id]
Dadurch wird das Tool „Abrufen“ so gefiltert, dass nur Ergebnisse aus dieser bestimmten Datenquelle abgerufen werden. Sie können auch nach benutzerdefinierten Metadatenfeldern filtern, die Sie in Ihren Bedrock-Datenquellen definiert haben, indem Sie dieselbe Override-Konfiguration verwenden.
Fügen Sie Zitationsdaten zu Ihrem AI-Agent-Trace hinzu
Wenn Ihr KI-Agent eine Wissensdatenbank verwendet, um Fragen zu beantworten, können Sie Zitationsdaten erfassen, aus denen hervorgeht, auf welche Inhalte der Wissensdatenbank verwiesen wurde. Diese Daten umfassen Folgendes:
-
ContentID — die Kennung des spezifischen Inhaltselements, auf das verwiesen wird
-
title — der Titel des Inhalts, auf den verwiesen wird (z. B. „Amazon Connect Overview“)
-
Wissen BaseId — die Kennung der verwendeten Wissensdatenbank
-
Wissen BaseArn — der ARN der verwendeten Wissensdatenbank
Diese Zitationsdaten der Wissensdatenbank sind über die ListSpans API und den KI-Agent-Trace verfügbar. Weitere Informationen finden Sie unter ListSpansund AI Agent Traces.
Anmerkung
Wenn Sie Agent Assistance verwenden, sind die Zitationsdaten automatisch enthalten, und es ist keine zusätzliche Konfiguration erforderlich. Die folgenden Schritte gelten nur für Self-Service-Orchestrierungsaufforderungen.
Aktualisieren Sie Ihre Self-Service-Eingabeaufforderung so, dass sie Zitate enthält
-
Um Zitationsdaten zu aktivieren, müssen Sie den Befehlsblock des Retrieve-Tools in Ihrer Self-Service-Orchestrierungsaufforderung aktualisieren. Dadurch wird das Modell angewiesen, Quellenverweise im erforderlichen Format in seine Antworten aufzunehmen.
-
Erstellen Sie eine Kopie Ihrer standardmäßigen Self-Service-Orchestrierungsaufforderung (Standardansagen können nicht direkt bearbeitet werden).
-
Ersetzen Sie in Ihrer kopierten Aufforderung den Anweisungsblock des Retrieve-Tools durch den folgenden Text:
instruction: instruction: |- Search the knowledge base using semantic search to find relevant information. Use the results of the RETRIEVE tool to provide an informed answer to the customer's query. When summarizing retrieve tool results, you MUST include source citations using the format shown in the good examples below. MUST include a <sources> block with the sourceId values from the Retrieve result inside every <message_part> that uses retrieved content. MUST use the exact sourceId string returned by the Retrieve tool. Do not modify, truncate, or fabricate sourceId values. MUST include source citations for ALL information taken from retrieve results. If a message_part is purely conversational (greetings, clarifying questions, hand-offs) and does not use retrieved content, omit the <sources> block. If retrieve returns no results or empty results, acknowledge that you don't have that specific information available. Do not make assumptions or provide information from general knowledge. examples: - |- Good example - single message part with one source: <message> <message_part> <text>Your warranty covers parts replacement for any manufacturing defects during the first year.</text> <sources> <sourceId>warranty_policy_2024</sourceId> </sources> </message_part> </message> - |- Good example - multiple sources contributing to one answer: <message> <message_part> <text>Our check-in time is 3 PM and checkout is 11 AM. Late checkout is available for an additional fee.</text> <sources> <sourceId>checkin_policy</sourceId> <sourceId>fees_addendum</sourceId> </sources> </message_part> </message> - |- Good example - greeting with no retrieval: <message> <message_part> <text>Hello! How can I help you today?</text> </message_part> </message> - |- Bad example - retrieved content with no sources block (avoid this): <message> <message_part> <text>We offer extended warranty coverage beyond the manufacturer's warranty period.</text> </message_part> </message> - |- Bad example - text outside <message_part> (avoid this): <message> <message_part> <text>Your warranty covers parts replacement.</text> <sources> <sourceId>warranty_policy_2024</sourceId> </sources> </message_part> Let me know if you need anything else. </message> - |- Example for no results: <message> <message_part> <text>I don't have specific information about that topic available.</text> </message_part> </message>
-
Speichern Sie Ihre Aufforderung und verknüpfen Sie sie mit Ihrem AI-Agenten.
Sprachagenten
Der <sources> Block besteht aus Metadaten und wird nicht laut ausgesprochen. Es hat keinen Einfluss darauf, was der Anrufer hört.
Wie verifiziert man
Nachdem Sie Ihre Eingabeaufforderung aktualisiert haben, stellen Sie einen Testkontakt her und bestätigen Sie:
-
Der Agent beantwortet die Frage richtig.
-
Überprüfen Sie die ListSpans API-Antwort für diese Sitzung. Die Wissensdatenbank, die zur Beantwortung verwendet wurde, sollte in den ListSpans Details als Quellenangaben erscheinen. Weitere Informationen finden Sie ListSpans unter ListSpans API.
