Process real-time bidding requests using GPU-accelerated inference on Amazon Elastic Kubernetes Service, enabling sub-millisecond model scoring that helps you win more auctions at optimal prices.
Overview
This Guidance demonstrates how to optimize real-time bidding decisions across multiple machine learning models by deploying GPU-accelerated NVIDIA model architectures that run in parallel within an ARTF-compliant framework. When an OpenRTB bid request arrives, an orchestrator container distributes it simultaneously to four specialized containers: one predicts click-through rates and computes optimal bid prices, another scores user-segment affinities to activate high-value audiences, a third evaluates deal relevance to activate or suppress private marketplace opportunities, and a fourth enriches requests with viewability and brand safety metrics. Each container applies specific ARTF mutations—such as BID_SHADE for pricing optimization, ACTIVATE_SEGMENTS for audience targeting, and ADD_METRICS for quality enrichment—and the orchestrator consolidates all recommendations into a single OpenRTB response within milliseconds. You can reduce advertising overspend while maintaining win rates, autonomously manage private marketplace deals, and enable AI agents to make real-time bidding decisions through Model Context Protocol integration.
Benefits
Accelerate bid decisions with GPU inference
Enrich bids with parallel model scoring
Fan out each bid request across multiple specialized models simultaneously. Score click-through rates, audience segments, and deal relevance in a single round trip to maximize yield.
Optimize ad spend with intelligent bid shading
Deploy deep learning models that predict optimal bid prices and suppress poor-match deals automatically. Reduce wasted spend while maintaining competitive win rates across programmatic auctions.
How it works
This architecture shows how accelerator-optimized compute can enable agentic real-time bid-stream mutations for OpenRTB auctions using Triton Inference Server on Amazon Elastic Kubernetes Service with GPU-accelerated inference.
Download the architecture diagram.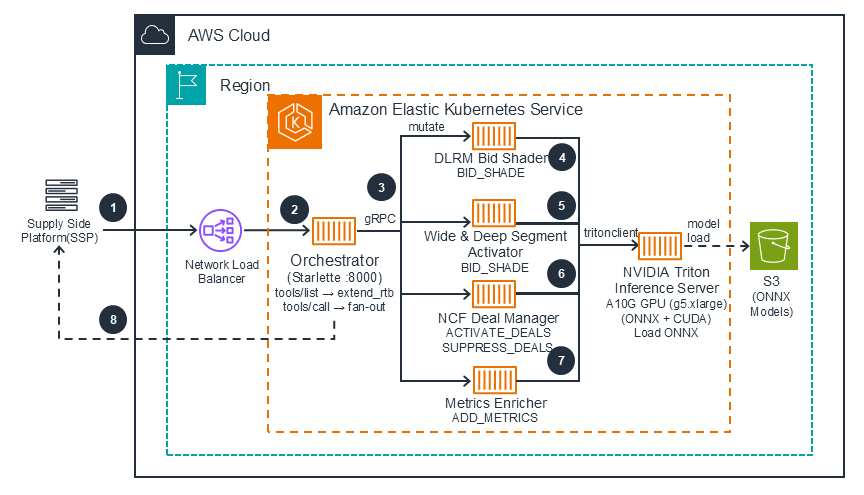 Step 1
Step 1
The Requester (for example, a Supply Side Platform) sends an OpenRTB bid request with JSON Web Token (JWT) tokens for session access.
The request routes through a Network Load Balancer to the Amazon Elastic Kubernetes Service cluster's Orchestrator container.
The Orchestrator on CPU nodes verifies the JWT token against Amazon Cognito's JSON Web Key Set (JWKS) endpoint, then fans out the request to all four containers (DLRM, Wide & Deep, NCF, and Metrics Enricher) in parallel.
The NVIDIA model containers (DLRM, Wide & Deep, NCF) call Triton Inference Server via tritonclient Python library, which runs GPU-accelerated inference using Open Neural Network Exchange (ONNX) Runtime with CUDA Execution Provider on A10G GPUs.
DLRM predicts click-through rate and computes an optimal shaded bid price. Wide & Deep scores user-segment affinities and activates audience segments above threshold.
NCF scores user-deal relevance to activate high-affinity deals and suppress poor matches.
The rule-based Metrics Enricher adds viewability and brand-safety scores.
The Orchestrator merges all mutations from the four containers into a single OpenRTB response and returns it to the requester.
Deploy with confidence
Everything you need to launch this Guidance in your account is right here.
Let's make it happen
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.